 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCA-LUT: Deep Chromatic Alignment with 5D LUT for Purple Fringing Removal
Nov 15, 2025



Purple fringing, a persistent artifact caused by Longitudinal Chromatic Aberration (LCA) in camera lenses, has long degraded the clarity and realism of digital imaging. Traditional solutions rely on complex and expensive apochromatic (APO) lens hardware and the extraction of handcrafted features, ignoring the data-driven approach. To fill this gap, we introduce DCA-LUT, the first deep learning framework for purple fringing removal. Inspired by the physical root of the problem, the spatial misalignment of RGB color channels due to lens dispersion, we introduce a novel Chromatic-Aware Coordinate Transformation (CA-CT) module, learning an image-adaptive color space to decouple and isolate fringing into a dedicated dimension. This targeted separation allows the network to learn a precise ``purple fringe channel", which then guides the accurate restoration of the luminance channel. The final color correction is performed by a learned 5D Look-Up Table (5D LUT), enabling efficient and powerful% non-linear color mapping. To enable robust training and fair evaluation, we constructed a large-scale synthetic purple fringing dataset (PF-Synth). Extensive experiments in synthetic and real-world datasets demonstrate that our method achieves state-of-the-art performance in purple fringing removal.
PointCG: Self-supervised Point Cloud Learning via Joint Completion and Generation
Nov 09, 2024



The core of self-supervised point cloud learning lies in setting up appropriate pretext tasks, to construct a pre-training framework that enables the encoder to perceive 3D objects effectively. In this paper, we integrate two prevalent methods, masked point modeling (MPM) and 3D-to-2D generation, as pretext tasks within a pre-training framework. We leverage the spatial awareness and precise supervision offered by these two methods to address their respective limitations: ambiguous supervision signals and insensitivity to geometric information. Specifically, the proposed framework, abbreviated as PointCG, consists of a Hidden Point Completion (HPC) module and an Arbitrary-view Image Generation (AIG) module. We first capture visible points from arbitrary views as inputs by removing hidden points. Then, HPC extracts representations of the inputs with an encoder and completes the entire shape with a decoder, while AIG is used to generate rendered images based on the visible points' representations. Extensive experiments demonstrate the superiority of the proposed method over the baselines in various downstream tasks. Our code will be made available upon acceptance.
DeMuVGN: Effective Software Defect Prediction Model by Learning Multi-view Software Dependency via Graph Neural Networks
Oct 25, 2024Software defect prediction (SDP) aims to identify high-risk defect modules in software development, optimizing resource allocation. While previous studies show that dependency network metrics improve defect prediction, most methods focus on code-based dependency graphs, overlooking developer factors. Current metrics, based on handcrafted features like ego and global network metrics, fail to fully capture defect-related information. To address this, we propose DeMuVGN, a defect prediction model that learns multi-view software dependency via graph neural networks. We introduce a Multi-view Software Dependency Graph (MSDG) that integrates data, call, and developer dependencies. DeMuVGN also leverages the Synthetic Minority Oversampling Technique (SMOTE) to address class imbalance and enhance defect module identification. In a case study of eight open-source projects across 20 versions, DeMuVGN demonstrates significant improvements: i) models based on multi-view graphs improve F1 scores by 11.1% to 12.1% over single-view models; ii) DeMuVGN improves F1 scores by 17.4% to 45.8% in within-project contexts and by 17.9% to 41.0% in cross-project contexts. Additionally, DeMuVGN excels in software evolution, showing more improvement in later-stage software versions. Its strong performance across different projects highlights its generalizability. We recommend future research focus on multi-view dependency graphs for defect prediction in both mature and newly developed projects.
Efficient Deep Learning Board: Training Feedback Is Not All You Need
Oct 17, 2024Current automatic deep learning (i.e., AutoDL) frameworks rely on training feedback from actual runs, which often hinder their ability to provide quick and clear performance predictions for selecting suitable DL systems. To address this issue, we propose EfficientDL, an innovative deep learning board designed for automatic performance prediction and component recommendation. EfficientDL can quickly and precisely recommend twenty-seven system components and predict the performance of DL models without requiring any training feedback. The magic of no training feedback comes from our proposed comprehensive, multi-dimensional, fine-grained system component dataset, which enables us to develop a static performance prediction model and comprehensive optimized component recommendation algorithm (i.e., {\alpha}\b{eta}-BO search), removing the dependency on actually running parameterized models during the traditional optimization search process. The simplicity and power of EfficientDL stem from its compatibility with most DL models. For example, EfficientDL operates seamlessly with mainstream models such as ResNet50, MobileNetV3, EfficientNet-B0, MaxViT-T, Swin-B, and DaViT-T, bringing competitive performance improvements. Besides, experimental results on the CIFAR-10 dataset reveal that EfficientDL outperforms existing AutoML tools in both accuracy and efficiency (approximately 20 times faster along with 1.31% Top-1 accuracy improvement than the cutting-edge methods). Source code, pretrained models, and datasets are available at https://github.com/OpenSELab/EfficientDL.
Joint Depth Estimation and Mixture of Rain Removal From a Single Image
Mar 31, 2023



Rainy weather significantly deteriorates the visibility of scene objects, particularly when images are captured through outdoor camera lenses or windshields. Through careful observation of numerous rainy photos, we have found that the images are generally affected by various rainwater artifacts such as raindrops, rain streaks, and rainy haze, which impact the image quality from both near and far distances, resulting in a complex and intertwined process of image degradation. However, current deraining techniques are limited in their ability to address only one or two types of rainwater, which poses a challenge in removing the mixture of rain (MOR). In this study, we propose an effective image deraining paradigm for Mixture of rain REmoval, called DEMore-Net, which takes full account of the MOR effect. Going beyond the existing deraining wisdom, DEMore-Net is a joint learning paradigm that integrates depth estimation and MOR removal tasks to achieve superior rain removal. The depth information can offer additional meaningful guidance information based on distance, thus better helping DEMore-Net remove different types of rainwater. Moreover, this study explores normalization approaches in image deraining tasks and introduces a new Hybrid Normalization Block (HNB) to enhance the deraining performance of DEMore-Net. Extensive experiments conducted on synthetic datasets and real-world MOR photos fully validate the superiority of the proposed DEMore-Net. Code is available at https://github.com/yz-wang/DEMore-Net.
ImLiDAR: Cross-Sensor Dynamic Message Propagation Network for 3D Object Detection
Nov 17, 2022



LiDAR and camera, as two different sensors, supply geometric (point clouds) and semantic (RGB images) information of 3D scenes. However, it is still challenging for existing methods to fuse data from the two cross sensors, making them complementary for quality 3D object detection (3OD). We propose ImLiDAR, a new 3OD paradigm to narrow the cross-sensor discrepancies by progressively fusing the multi-scale features of camera Images and LiDAR point clouds. ImLiDAR enables to provide the detection head with cross-sensor yet robustly fused features. To achieve this, two core designs exist in ImLiDAR. First, we propose a cross-sensor dynamic message propagation module to combine the best of the multi-scale image and point features. Second, we raise a direct set prediction problem that allows designing an effective set-based detector to tackle the inconsistency of the classification and localization confidences, and the sensitivity of hand-tuned hyperparameters. Besides, the novel set-based detector can be detachable and easily integrated into various detection networks. Comparisons on both the KITTI and SUN-RGBD datasets show clear visual and numerical improvements of our ImLiDAR over twenty-three state-of-the-art 3OD methods.
PointSee: Image Enhances Point Cloud
Nov 03, 2022



There is a trend to fuse multi-modal information for 3D object detection (3OD). However, the challenging problems of low lightweightness, poor flexibility of plug-and-play, and inaccurate alignment of features are still not well-solved, when designing multi-modal fusion newtorks. We propose PointSee, a lightweight, flexible and effective multi-modal fusion solution to facilitate various 3OD networks by semantic feature enhancement of LiDAR point clouds assembled with scene images. Beyond the existing wisdom of 3OD, PointSee consists of a hidden module (HM) and a seen module (SM): HM decorates LiDAR point clouds using 2D image information in an offline fusion manner, leading to minimal or even no adaptations of existing 3OD networks; SM further enriches the LiDAR point clouds by acquiring point-wise representative semantic features, leading to enhanced performance of existing 3OD networks. Besides the new architecture of PointSee, we propose a simple yet efficient training strategy, to ease the potential inaccurate regressions of 2D object detection networks. Extensive experiments on the popular outdoor/indoor benchmarks show numerical improvements of our PointSee over twenty-two state-of-the-arts.
TogetherNet: Bridging Image Restoration and Object Detection Together via Dynamic Enhancement Learning
Sep 03, 2022
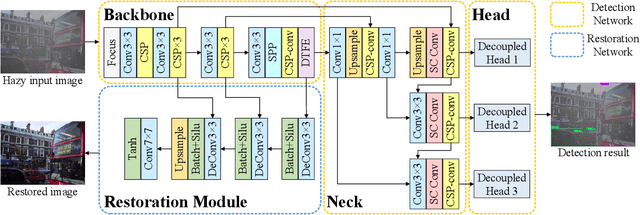
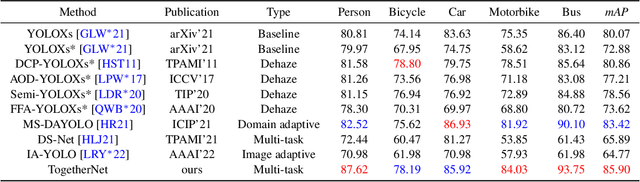
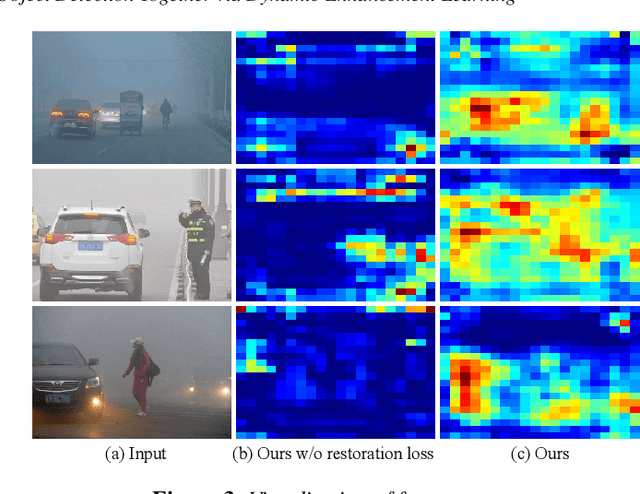
Adverse weather conditions such as haze, rain, and snow often impair the quality of captured images, causing detection networks trained on normal images to generalize poorly in these scenarios. In this paper, we raise an intriguing question - if the combination of image restoration and object detection, can boost the performance of cutting-edge detectors in adverse weather conditions. To answer it, we propose an effective yet unified detection paradigm that bridges these two subtasks together via dynamic enhancement learning to discern objects in adverse weather conditions, called TogetherNet. Different from existing efforts that intuitively apply image dehazing/deraining as a pre-processing step, TogetherNet considers a multi-task joint learning problem. Following the joint learning scheme, clean features produced by the restoration network can be shared to learn better object detection in the detection network, thus helping TogetherNet enhance the detection capacity in adverse weather conditions. Besides the joint learning architecture, we design a new Dynamic Transformer Feature Enhancement module to improve the feature extraction and representation capabilities of TogetherNet. Extensive experiments on both synthetic and real-world datasets demonstrate that our TogetherNet outperforms the state-of-the-art detection approaches by a large margin both quantitatively and qualitatively. Source code is available at https://github.com/yz-wang/TogetherNet.
Contrastive Semantic-Guided Image Smoothing Network
Sep 02, 2022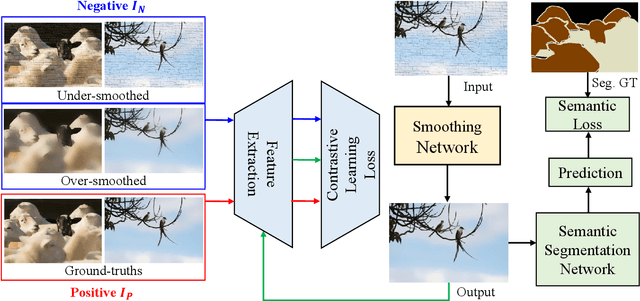
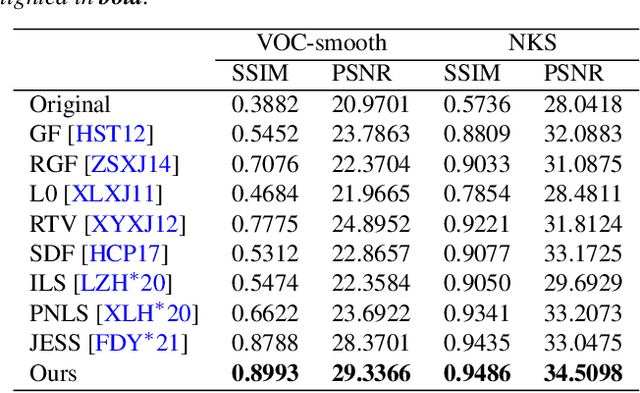
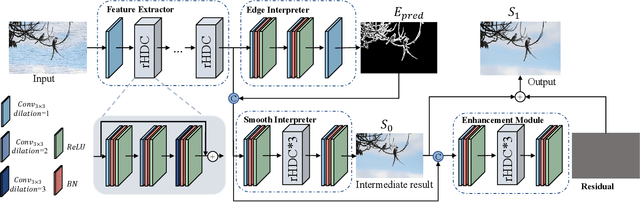

Image smoothing is a fundamental low-level vision task that aims to preserve salient structures of an image while removing insignificant details. Deep learning has been explored in image smoothing to deal with the complex entanglement of semantic structures and trivial details. However, current methods neglect two important facts in smoothing: 1) naive pixel-level regression supervised by the limited number of high-quality smoothing ground-truth could lead to domain shift and cause generalization problems towards real-world images; 2) texture appearance is closely related to object semantics, so that image smoothing requires awareness of semantic difference to apply adaptive smoothing strengths. To address these issues, we propose a novel Contrastive Semantic-Guided Image Smoothing Network (CSGIS-Net) that combines both contrastive prior and semantic prior to facilitate robust image smoothing. The supervision signal is augmented by leveraging undesired smoothing effects as negative teachers, and by incorporating segmentation tasks to encourage semantic distinctiveness. To realize the proposed network, we also enrich the original VOC dataset with texture enhancement and smoothing labels, namely VOC-smooth, which first bridges image smoothing and semantic segmentation. Extensive experiments demonstrate that the proposed CSGIS-Net outperforms state-of-the-art algorithms by a large margin. Code and dataset are available at https://github.com/wangjie6866/CSGIS-Net.
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Aug 12, 2022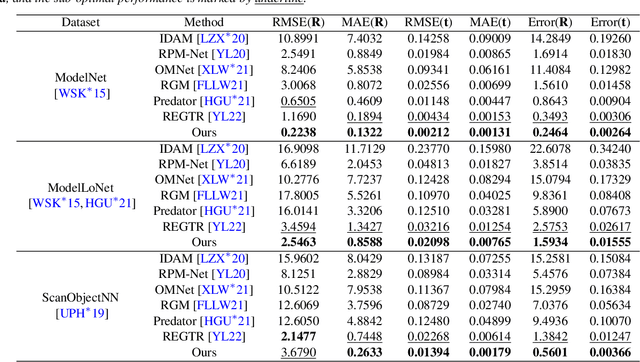
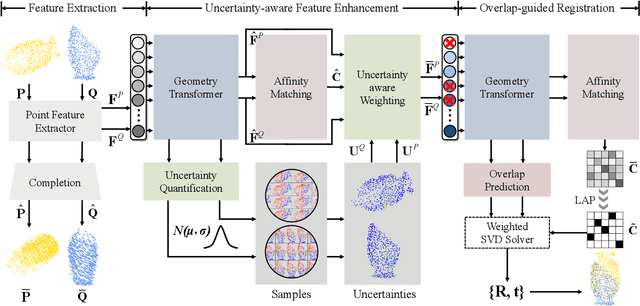
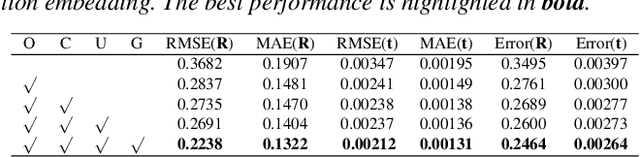
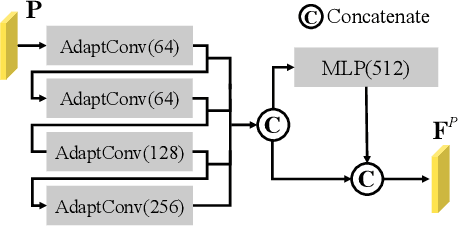
High-confidence overlap prediction and accurate correspondences are critical for cutting-edge models to align paired point clouds in a partial-to-partial manner. However, there inherently exists uncertainty between the overlapping and non-overlapping regions, which has always been neglected and significantly affects the registration performance. Beyond the current wisdom, we propose a novel uncertainty-aware overlap prediction network, dubbed UTOPIC, to tackle the ambiguous overlap prediction problem; to our knowledge, this is the first to explicitly introduce overlap uncertainty to point cloud registration. Moreover, we induce the feature extractor to implicitly perceive the shape knowledge through a completion decoder, and present a geometric relation embedding for Transformer to obtain transformation-invariant geometry-aware feature representations. With the merits of more reliable overlap scores and more precise dense correspondences, UTOPIC can achieve stable and accurate registration results, even for the inputs with limited overlapping areas. Extensive quantitative and qualitative experiments on synthetic and real benchmarks demonstrate the superiority of our approach over state-of-the-art methods.