 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealRep: Generalized SDR-to-HDR Conversion with Style Disentangled Representation Learning
May 12, 2025High-Dynamic-Range Wide-Color-Gamut (HDR-WCG) technology is becoming increasingly prevalent, intensifying the demand for converting Standard Dynamic Range (SDR) content to HDR. Existing methods primarily rely on fixed tone mapping operators, which are inadequate for handling SDR inputs with diverse styles commonly found in real-world scenarios. To address this challenge, we propose a generalized SDR-to-HDR method that handles diverse styles in real-world SDR content, termed Realistic Style Disentangled Representation Learning (RealRep). By disentangling luminance and chrominance, we analyze the intrinsic differences between contents with varying styles and propose a disentangled multi-view style representation learning method. This approach captures the guidance prior of true luminance and chrominance distributions across different styles, even when the SDR style distributions exhibit significant variations, thereby establishing a robust embedding space for inverse tone mapping. Motivated by the difficulty of directly utilizing degradation representation priors, we further introduce the Degradation-Domain Aware Controlled Mapping Network (DDACMNet), a two-stage framework that performs adaptive hierarchical mapping guided by a control-aware normalization mechanism. DDACMNet dynamically modulates the mapping process via degradation-conditioned hierarchical features, enabling robust adaptation across diverse degradation domains. Extensive experiments show that RealRep consistently outperforms state-of-the-art methods with superior generalization and perceptually faithful HDR color gamut reconstruction.
Uncertainty Estimation for Trust Attribution to Speed-of-Sound Reconstruction with Variational Networks
Apr 15, 2025Speed-of-sound (SoS) is a biomechanical characteristic of tissue, and its imaging can provide a promising biomarker for diagnosis. Reconstructing SoS images from ultrasound acquisitions can be cast as a limited-angle computed-tomography problem, with Variational Networks being a promising model-based deep learning solution. Some acquired data frames may, however, get corrupted by noise due to, e.g., motion, lack of contact, and acoustic shadows, which in turn negatively affects the resulting SoS reconstructions. We propose to use the uncertainty in SoS reconstructions to attribute trust to each individual acquired frame. Given multiple acquisitions, we then use an uncertainty based automatic selection among these retrospectively, to improve diagnostic decisions. We investigate uncertainty estimation based on Monte Carlo Dropout and Bayesian Variational Inference. We assess our automatic frame selection method for differential diagnosis of breast cancer, distinguishing between benign fibroadenoma and malignant carcinoma. We evaluate 21 lesions classified as BI-RADS~4, which represents suspicious cases for probable malignancy. The most trustworthy frame among four acquisitions of each lesion was identified using uncertainty based criteria. Selecting a frame informed by uncertainty achieved an area under curve of 76% and 80% for Monte Carlo Dropout and Bayesian Variational Inference, respectively, superior to any uncertainty-uninformed baselines with the best one achieving 64%. A novel use of uncertainty estimation is proposed for selecting one of multiple data acquisitions for further processing and decision making.
A Robust Real-Time Lane Detection Method with Fog-Enhanced Feature Fusion for Foggy Conditions
Apr 08, 2025Lane detection is a critical component of Advanced Driver Assistance Systems (ADAS). Existing lane detection algorithms generally perform well under favorable weather conditions. However, their performance degrades significantly in adverse conditions, such as fog, which increases the risk of traffic accidents. This challenge is compounded by the lack of specialized datasets and methods designed for foggy environments. To address this, we introduce the FoggyLane dataset, captured in real-world foggy scenarios, and synthesize two additional datasets, FoggyCULane and FoggyTusimple, from existing popular lane detection datasets. Furthermore, we propose a robust Fog-Enhanced Network for lane detection, incorporating a Global Feature Fusion Module (GFFM) to capture global relationships in foggy images, a Kernel Feature Fusion Module (KFFM) to model the structural and positional relationships of lane instances, and a Low-level Edge Enhanced Module (LEEM) to address missing edge details in foggy conditions. Comprehensive experiments demonstrate that our method achieves state-of-the-art performance, with F1-scores of 95.04 on FoggyLane, 79.85 on FoggyCULane, and 96.95 on FoggyTusimple. Additionally, with TensorRT acceleration, the method reaches a processing speed of 38.4 FPS on the NVIDIA Jetson AGX Orin, confirming its real-time capabilities and robustness in foggy environments.
LITE: LLM-Impelled efficient Taxonomy Evaluation
Apr 02, 2025This paper presents LITE, an LLM-based evaluation method designed for efficient and flexible assessment of taxonomy quality. To address challenges in large-scale taxonomy evaluation, such as efficiency, fairness, and consistency, LITE adopts a top-down hierarchical evaluation strategy, breaking down the taxonomy into manageable substructures and ensuring result reliability through cross-validation and standardized input formats. LITE also introduces a penalty mechanism to handle extreme cases and provides both quantitative performance analysis and qualitative insights by integrating evaluation metrics closely aligned with task objectives. Experimental results show that LITE demonstrates high reliability in complex evaluation tasks, effectively identifying semantic errors, logical contradictions, and structural flaws in taxonomies, while offering directions for improvement. Code is available at https://github.com/Zhang-l-i-n/TAXONOMY_DETECT .
RECKON: Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model
Apr 01, 2025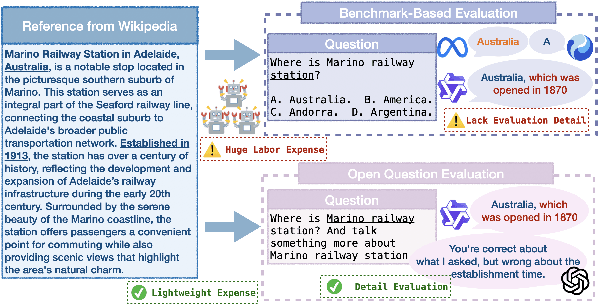
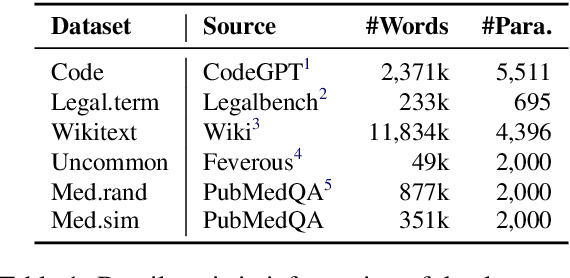
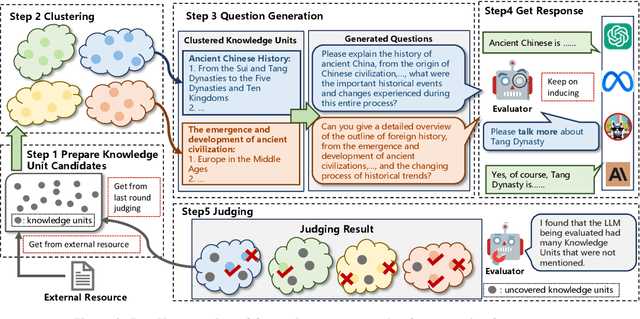
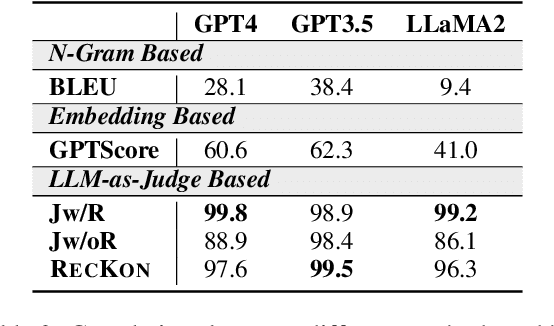
As large language models (LLMs) advance, efficient knowledge evaluation becomes crucial to verifying their capabilities. Traditional methods, relying on benchmarks, face limitations such as high resource costs and information loss. We propose the Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model (RECKON), which directly uses reference data to evaluate models. RECKON organizes unstructured data into manageable units and generates targeted questions for each cluster, improving evaluation accuracy and efficiency. Experimental results show that RECKON reduces resource consumption by 56.5% compared to traditional methods while achieving over 97% accuracy across various domains, including world knowledge, code, legal, and biomedical datasets. Code is available at https://github.com/MikeGu721/reckon
FAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding
Mar 19, 2025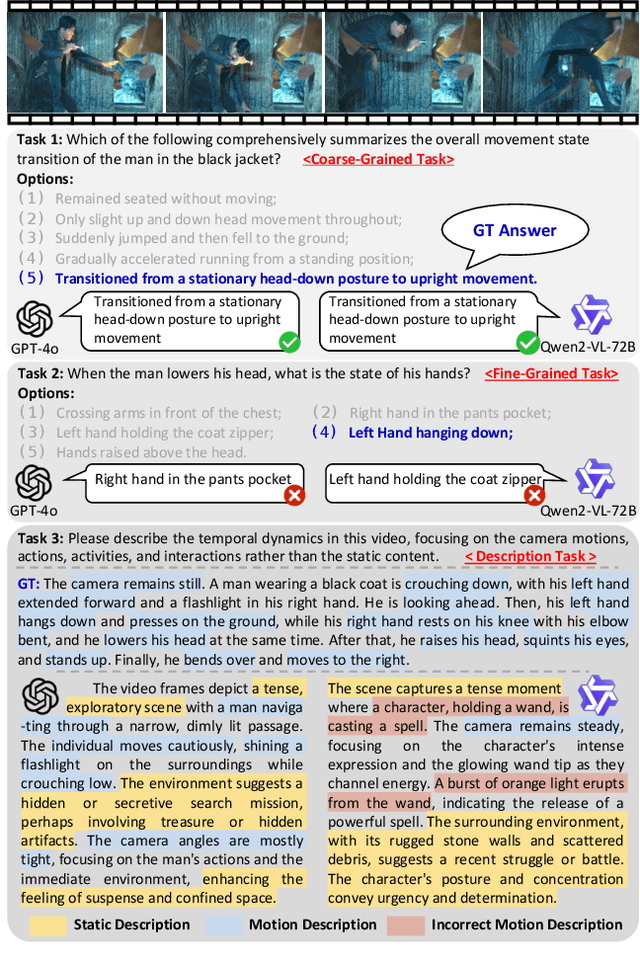

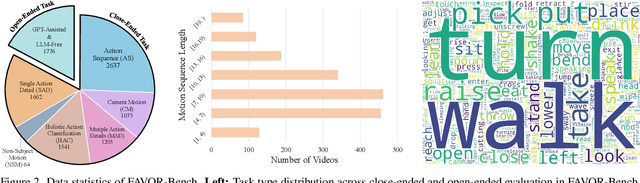
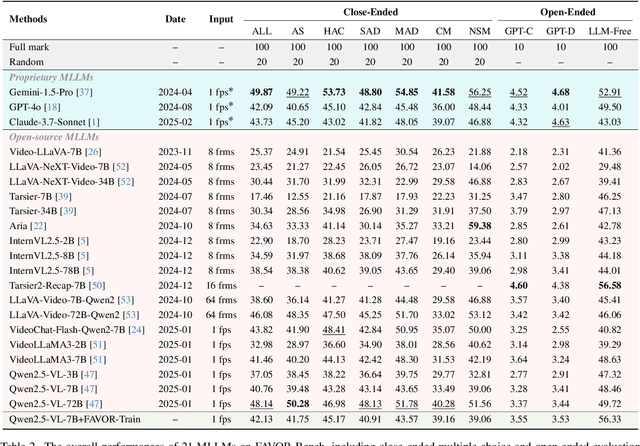
Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in video content understanding but still struggle with fine-grained motion comprehension. To comprehensively assess the motion understanding ability of existing MLLMs, we introduce FAVOR-Bench, comprising 1,776 videos with structured manual annotations of various motions. Our benchmark includes both close-ended and open-ended tasks. For close-ended evaluation, we carefully design 8,184 multiple-choice question-answer pairs spanning six distinct sub-tasks. For open-ended evaluation, we develop both a novel cost-efficient LLM-free and a GPT-assisted caption assessment method, where the former can enhance benchmarking interpretability and reproducibility. Comprehensive experiments with 21 state-of-the-art MLLMs reveal significant limitations in their ability to comprehend and describe detailed temporal dynamics in video motions. To alleviate this limitation, we further build FAVOR-Train, a dataset consisting of 17,152 videos with fine-grained motion annotations. The results of finetuning Qwen2.5-VL on FAVOR-Train yield consistent improvements on motion-related tasks of TVBench, MotionBench and our FAVOR-Bench. Comprehensive assessment results demonstrate that the proposed FAVOR-Bench and FAVOR-Train provide valuable tools to the community for developing more powerful video understanding models. Project page: \href{https://favor-bench.github.io/}{https://favor-bench.github.io/}.
TokenCarve: Information-Preserving Visual Token Compression in Multimodal Large Language Models
Mar 13, 2025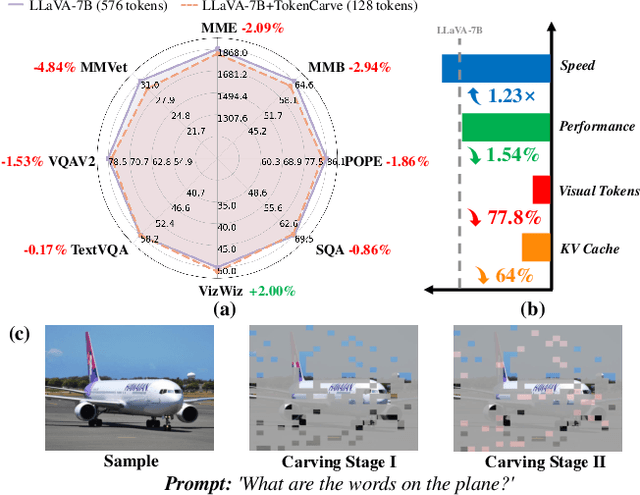
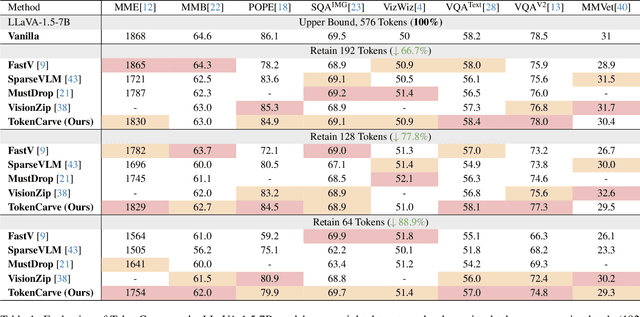
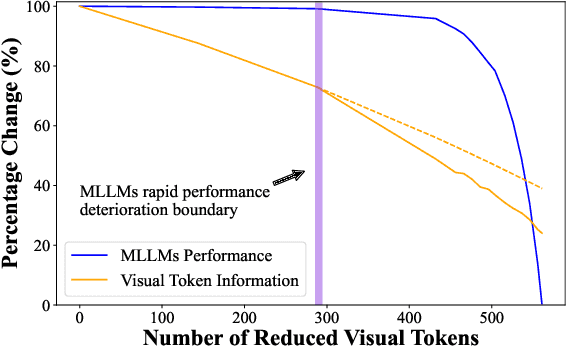
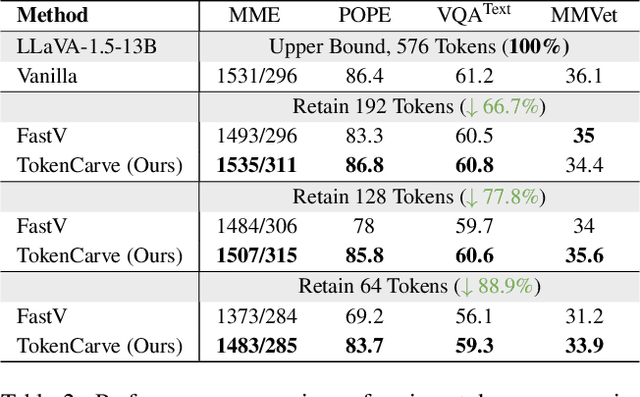
Multimodal Large Language Models (MLLMs) are becoming increasingly popular, while the high computational cost associated with multimodal data input, particularly from visual tokens, poses a significant challenge. Existing training-based token compression methods improve inference efficiency but require costly retraining, while training-free methods struggle to maintain performance when aggressively reducing token counts. In this study, we reveal that the performance degradation of MLLM closely correlates with the accelerated loss of information in the attention output matrix. This insight introduces a novel information-preserving perspective, making it possible to maintain performance even under extreme token compression. Based on this finding, we propose TokenCarve, a training-free, plug-and-play, two-stage token compression framework. The first stage employs an Information-Preservation-Guided Selection (IPGS) strategy to prune low-information tokens, while the second stage further leverages IPGS to guide token merging, minimizing information loss. Extensive experiments on 11 datasets and 2 model variants demonstrate the effectiveness of TokenCarve. It can even reduce the number of visual tokens to 22.2% of the original count, achieving a 1.23x speedup in inference, a 64% reduction in KV cache storage, and only a 1.54% drop in accuracy. Our code is available at https://github.com/ShawnTan86/TokenCarve.
GenAI for Simulation Model in Model-Based Systems Engineering
Mar 09, 2025Generative AI (GenAI) has demonstrated remarkable capabilities in code generation, and its integration into complex product modeling and simulation code generation can significantly enhance the efficiency of the system design phase in Model-Based Systems Engineering (MBSE). In this study, we introduce a generative system design methodology framework for MBSE, offering a practical approach for the intelligent generation of simulation models for system physical properties. First, we employ inference techniques, generative models, and integrated modeling and simulation languages to construct simulation models for system physical properties based on product design documents. Subsequently, we fine-tune the language model used for simulation model generation on an existing library of simulation models and additional datasets generated through generative modeling. Finally, we introduce evaluation metrics for the generated simulation models for system physical properties. Our proposed approach to simulation model generation presents the innovative concept of scalable templates for simulation models. Using these templates, GenAI generates simulation models for system physical properties through code completion. The experimental results demonstrate that, for mainstream open-source Transformer-based models, the quality of the simulation model is significantly improved using the simulation model generation method proposed in this paper.
Gradient-Driven Graph Neural Networks for Learning Digital and Hybrid Precoder
Mar 08, 2025The optimization of multi-user multi-input multi-output (MU-MIMO) precoders is a widely recognized challenging problem. Existing work has demonstrated the potential of graph neural networks (GNNs) in learning precoding policies. However, existing GNNs often exhibit poor generalizability for the numbers of users or antennas. In this paper, we develop a gradient-driven GNN design method for the learning of fully digital and hybrid precoding policies. The proposed GNNs leverage two kinds of knowledge, namely the gradient of signal-to-interference-plus-noise ratio (SINR) to the precoders and the permutation equivariant property of the precoding policy. To demonstrate the flexibility of the proposed method for accommodating different optimization objectives and different precoding policies, we first apply the proposed method to learn the fully digital precoding policies. We study two precoder optimization problems for spectral efficiency (SE) maximization and log-SE maximization to achieve proportional fairness. We then apply the proposed method to learn the hybrid precoding policy, where the gradients to analog and digital precoders are exploited for the design of the GNN. Simulation results show the effectiveness of the proposed methods for learning different precoding policies and better generalization performance to the numbers of both users and antennas compared to baseline GNNs.
DeRS: Towards Extremely Efficient Upcycled Mixture-of-Experts Models
Mar 03, 2025



Upcycled Mixture-of-Experts (MoE) models have shown great potential in various tasks by converting the original Feed-Forward Network (FFN) layers in pre-trained dense models into MoE layers. However, these models still suffer from significant parameter inefficiency due to the introduction of multiple experts. In this work, we propose a novel DeRS (Decompose, Replace, and Synthesis) paradigm to overcome this shortcoming, which is motivated by our observations about the unique redundancy mechanisms of upcycled MoE experts. Specifically, DeRS decomposes the experts into one expert-shared base weight and multiple expert-specific delta weights, and subsequently represents these delta weights in lightweight forms. Our proposed DeRS paradigm can be applied to enhance parameter efficiency in two different scenarios, including: 1) DeRS Compression for inference stage, using sparsification or quantization to compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage, employing lightweight sparse or low-rank matrixes to efficiently upcycle dense models into MoE models. Extensive experiments across three different tasks show that the proposed methods can achieve extreme parameter efficiency while maintaining the performance for both training and compression of upcycled MoE models.