 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Using a Kernel-Based Method Over Foundation Models
Dec 20, 2024Continual learning (CL) learns a sequence of tasks incrementally. This paper studies the challenging CL setting of class-incremental learning (CIL). CIL has two key challenges: catastrophic forgetting (CF) and inter-task class separation (ICS). Despite numerous proposed methods, these issues remain persistent obstacles. This paper proposes a novel CIL method, called Kernel Linear Discriminant Analysis (KLDA), that can effectively avoid CF and ICS problems. It leverages only the powerful features learned in a foundation model (FM). However, directly using these features proves suboptimal. To address this, KLDA incorporates the Radial Basis Function (RBF) kernel and its Random Fourier Features (RFF) to enhance the feature representations from the FM, leading to improved performance. When a new task arrives, KLDA computes only the mean for each class in the task and updates a shared covariance matrix for all learned classes based on the kernelized features. Classification is performed using Linear Discriminant Analysis. Our empirical evaluation using text and image classification datasets demonstrates that KLDA significantly outperforms baselines. Remarkably, without relying on replay data, KLDA achieves accuracy comparable to joint training of all classes, which is considered the upper bound for CIL performance. The KLDA code is available at https://github.com/salehmomeni/klda.
In-context Continual Learning Assisted by an External Continual Learner
Dec 20, 2024Existing continual learning (CL) methods mainly rely on fine-tuning or adapting large language models (LLMs). They still suffer from catastrophic forgetting (CF). Little work has been done to exploit in-context learning (ICL) to leverage the extensive knowledge within LLMs for CL without updating any parameters. However, incrementally learning each new task in ICL necessitates adding training examples from each class of the task to the prompt, which hampers scalability as the prompt length increases. This issue not only leads to excessively long prompts that exceed the input token limit of the underlying LLM but also degrades the model's performance due to the overextended context. To address this, we introduce InCA, a novel approach that integrates an external continual learner (ECL) with ICL to enable scalable CL without CF. The ECL is built incrementally to pre-select a small subset of likely classes for each test instance. By restricting the ICL prompt to only these selected classes, InCA prevents prompt lengths from becoming excessively long, while maintaining high performance. Experimental results demonstrate that InCA significantly outperforms existing CL baselines, achieving substantial performance gains.
Decoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models
Aug 07, 2024



Large Language Models (LLMs) have excelled at language understanding and generating human-level text. However, even with supervised training and human alignment, these LLMs are susceptible to adversarial attacks where malicious users can prompt the model to generate undesirable text. LLMs also inherently encode potential biases that can cause various harmful effects during interactions. Bias evaluation metrics lack standards as well as consensus and existing methods often rely on human-generated templates and annotations which are expensive and labor intensive. In this work, we train models to automatically create adversarial prompts to elicit biased responses from target LLMs. We present LLM- based bias evaluation metrics and also analyze several existing automatic evaluation methods and metrics. We analyze the various nuances of model responses, identify the strengths and weaknesses of model families, and assess where evaluation methods fall short. We compare these metrics to human evaluation and validate that the LLM-as-a-Judge metric aligns with human judgement on bias in response generation.
Safety through Permissibility: Shield Construction for Fast and Safe Reinforcement Learning
May 29, 2024Designing Reinforcement Learning (RL) solutions for real-life problems remains a significant challenge. A major area of concern is safety. "Shielding" is a popular technique to enforce safety in RL by turning user-defined safety specifications into safe agent behavior. However, these methods either suffer from extreme learning delays, demand extensive human effort in designing models and safe domains in the problem, or require pre-computation. In this paper, we propose a new permissibility-based framework to deal with safety and shield construction. Permissibility was originally designed for eliminating (non-permissible) actions that will not lead to an optimal solution to improve RL training efficiency. This paper shows that safety can be naturally incorporated into this framework, i.e. extending permissibility to include safety, and thereby we can achieve both safety and improved efficiency. Experimental evaluation using three standard RL applications shows the effectiveness of the approach.
Sample Efficient Multimodal Semantic Augmentation for Incremental Summarization
Mar 08, 2023



In this work, we develop a prompting approach for incremental summarization of task videos. We develop a sample-efficient few-shot approach for extracting semantic concepts as an intermediate step. We leverage an existing model for extracting the concepts from the images and extend it to videos and introduce a clustering and querying approach for sample efficiency, motivated by the recent advances in perceiver-based architectures. Our work provides further evidence that an approach with richer input context with relevant entities and actions from the videos and using these as prompts could enhance the summaries generated by the model. We show the results on a relevant dataset and discuss possible directions for the work.
Position Matters! Empirical Study of Order Effect in Knowledge-grounded Dialogue
Feb 12, 2023



With the power of large pretrained language models, various research works have integrated knowledge into dialogue systems. The traditional techniques treat knowledge as part of the input sequence for the dialogue system, prepending a set of knowledge statements in front of dialogue history. However, such a mechanism forces knowledge sets to be concatenated in an ordered manner, making models implicitly pay imbalanced attention to the sets during training. In this paper, we first investigate how the order of the knowledge set can influence autoregressive dialogue systems' responses. We conduct experiments on two commonly used dialogue datasets with two types of transformer-based models and find that models view the input knowledge unequally. To this end, we propose a simple and novel technique to alleviate the order effect by modifying the position embeddings of knowledge input in these models. With the proposed position embedding method, the experimental results show that each knowledge statement is uniformly considered to generate responses.
Lifelong and Continual Learning Dialogue Systems
Nov 12, 2022



Dialogue systems, commonly known as chatbots, have gained escalating popularity in recent times due to their wide-spread applications in carrying out chit-chat conversations with users and task-oriented dialogues to accomplish various user tasks. Existing chatbots are usually trained from pre-collected and manually-labeled data and/or written with handcrafted rules. Many also use manually-compiled knowledge bases (KBs). Their ability to understand natural language is still limited, and they tend to produce many errors resulting in poor user satisfaction. Typically, they need to be constantly improved by engineers with more labeled data and more manually compiled knowledge. This book introduces the new paradigm of lifelong learning dialogue systems to endow chatbots the ability to learn continually by themselves through their own self-initiated interactions with their users and working environments to improve themselves. As the systems chat more and more with users or learn more and more from external sources, they become more and more knowledgeable and better and better at conversing. The book presents the latest developments and techniques for building such continual learning dialogue systems that continuously learn new language expressions and lexical and factual knowledge during conversation from users and off conversation from external sources, acquire new training examples during conversation, and learn conversational skills. Apart from these general topics, existing works on continual learning of some specific aspects of dialogue systems are also surveyed. The book concludes with a discussion of open challenges for future research.
Semantic Novelty Detection and Characterization in Factual Text Involving Named Entities
Oct 31, 2022



Much of the existing work on text novelty detection has been studied at the topic level, i.e., identifying whether the topic of a document or a sentence is novel or not. Little work has been done at the fine-grained semantic level (or contextual level). For example, given that we know Elon Musk is the CEO of a technology company, the sentence "Elon Musk acted in the sitcom The Big Bang Theory" is novel and surprising because normally a CEO would not be an actor. Existing topic-based novelty detection methods work poorly on this problem because they do not perform semantic reasoning involving relations between named entities in the text and their background knowledge. This paper proposes an effective model (called PAT-SND) to solve the problem, which can also characterize the novelty. An annotated dataset is also created. Evaluation shows that PAT-SND outperforms 10 baselines by large margins.
Knowledge-Guided Exploration in Deep Reinforcement Learning
Oct 26, 2022



This paper proposes a new method to drastically speed up deep reinforcement learning (deep RL) training for problems that have the property of state-action permissibility (SAP). Two types of permissibility are defined under SAP. The first type says that after an action $a_t$ is performed in a state $s_t$ and the agent has reached the new state $s_{t+1}$, the agent can decide whether $a_t$ is permissible or not permissible in $s_t$. The second type says that even without performing $a_t$ in $s_t$, the agent can already decide whether $a_t$ is permissible or not in $s_t$. An action is not permissible in a state if the action can never lead to an optimal solution and thus should not be tried (over and over again). We incorporate the proposed SAP property and encode action permissibility knowledge into two state-of-the-art deep RL algorithms to guide their state-action exploration together with a virtual stopping strategy. Results show that the SAP-based guidance can markedly speed up RL training.
AI Autonomy: Self-Initiation, Adaptation and Continual Learning
Mar 19, 2022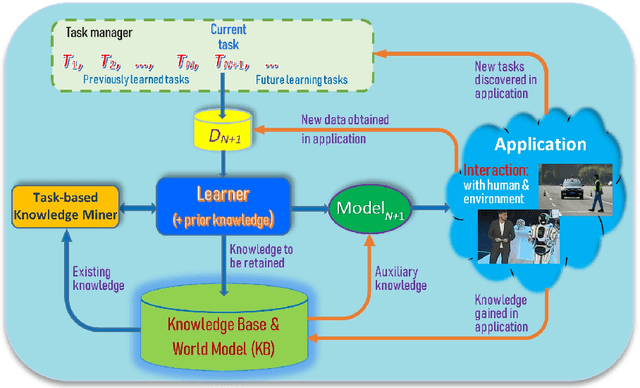
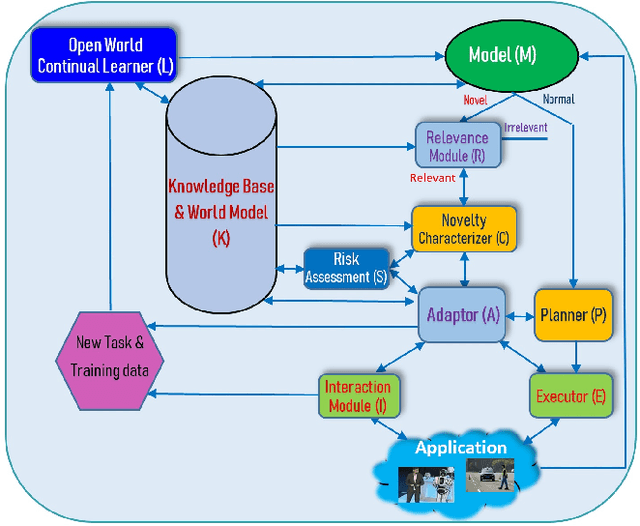
As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can (1) learn by themselves continually in a self-motivated and self-initiated manner rather than being retrained offline periodically on the initiation of human engineers and (2) accommodate or adapt to unexpected or novel circumstances. As the real-world is an open environment that is full of unknowns or novelties, detecting novelties, characterizing them, accommodating or adapting to them, and gathering ground-truth training data and incrementally learning the unknowns/novelties are critical to making the AI agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out continually on the agent's own initiative and through its own interactions with humans, other agents and the environment just like human on-the-job learning. This paper proposes a framework (called SOLA) for this learning paradigm to promote the research of building autonomous and continual learning enabled AI agents. To show feasibility, an implemented agent is also described.