 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing digital core image resolution using optimal upscaling algorithm: with application to paired SEM images
Sep 05, 2024



The porous media community extensively utilizes digital rock images for core analysis. High-resolution digital rock images that possess sufficient quality are essential but often challenging to acquire. Super-resolution (SR) approaches enhance the resolution of digital rock images and provide improved visualization of fine features and structures, aiding in the analysis and interpretation of rock properties, such as pore connectivity and mineral distribution. However, there is a current shortage of real paired microscopic images for super-resolution training. In this study, we used two types of Scanning Electron Microscopes (SEM) to obtain the images of shale samples in five regions, with 1X, 2X, 4X, 8X and 16X magnifications. We used these real scanned paired images as a reference to select the optimal method of image generation and validated it using Enhanced Deep Super Resolution (EDSR) and Very Deep Super Resolution (VDSR) methods. Our experiments show that the bilinear algorithm is more suitable than the commonly used bicubic method, for establishing low-resolution datasets in the SR approaches, which is partially attributed to the mechanism of Scanning Electron Microscopes (SEM).
Q-TOD: A Query-driven Task-oriented Dialogue System
Oct 14, 2022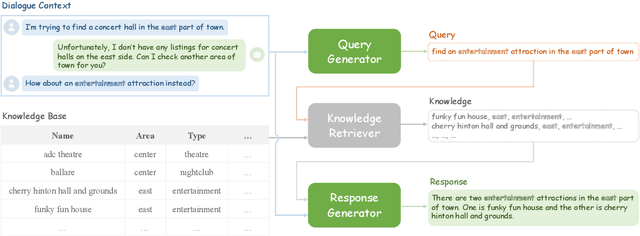
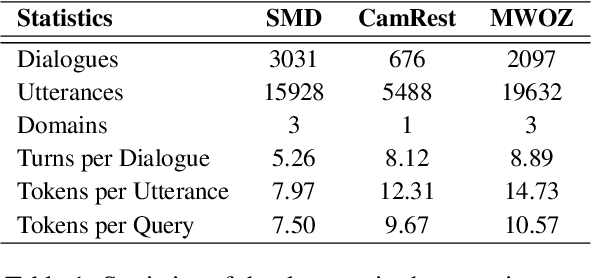
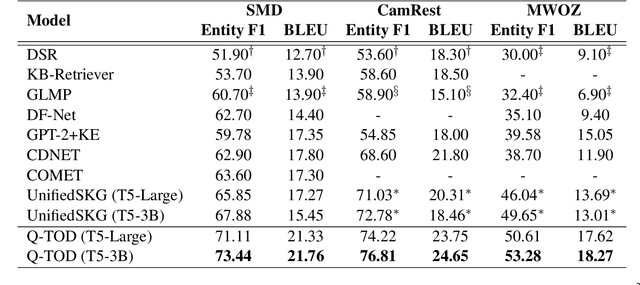
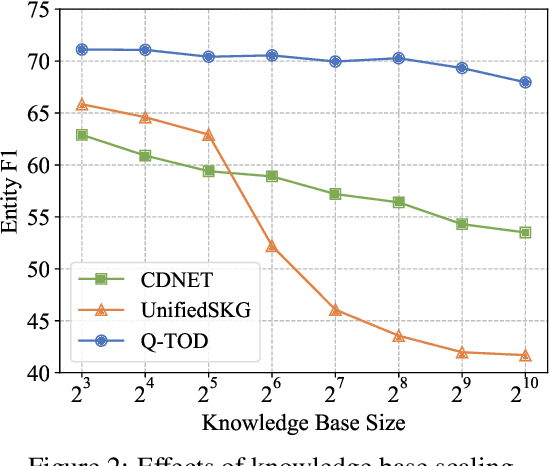
Existing pipelined task-oriented dialogue systems usually have difficulties adapting to unseen domains, whereas end-to-end systems are plagued by large-scale knowledge bases in practice. In this paper, we introduce a novel query-driven task-oriented dialogue system, namely Q-TOD. The essential information from the dialogue context is extracted into a query, which is further employed to retrieve relevant knowledge records for response generation. Firstly, as the query is in the form of natural language and not confined to the schema of the knowledge base, the issue of domain adaption is alleviated remarkably in Q-TOD. Secondly, as the query enables the decoupling of knowledge retrieval from the generation, Q-TOD gets rid of the issue of knowledge base scalability. To evaluate the effectiveness of the proposed Q-TOD, we collect query annotations for three publicly available task-oriented dialogue datasets. Comprehensive experiments verify that Q-TOD outperforms strong baselines and establishes a new state-of-the-art performance on these datasets.
TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021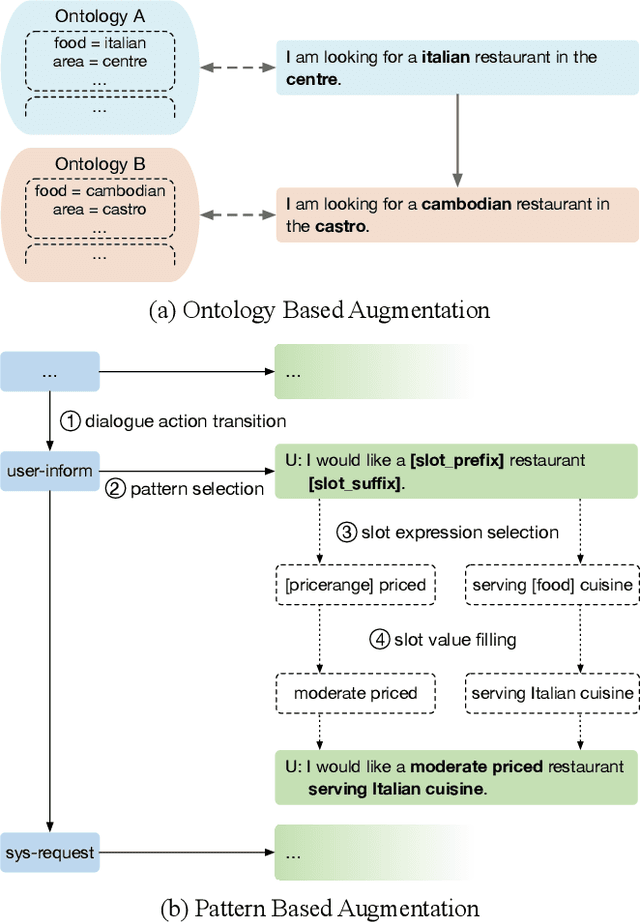
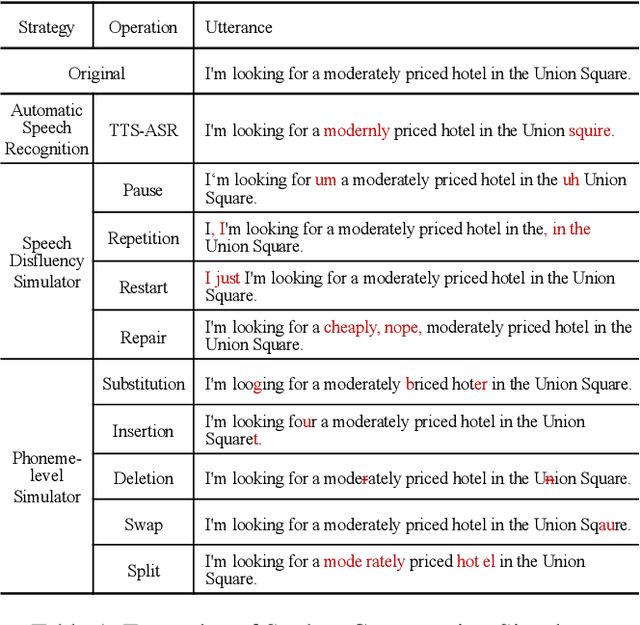
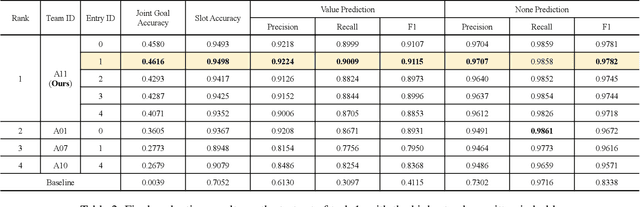
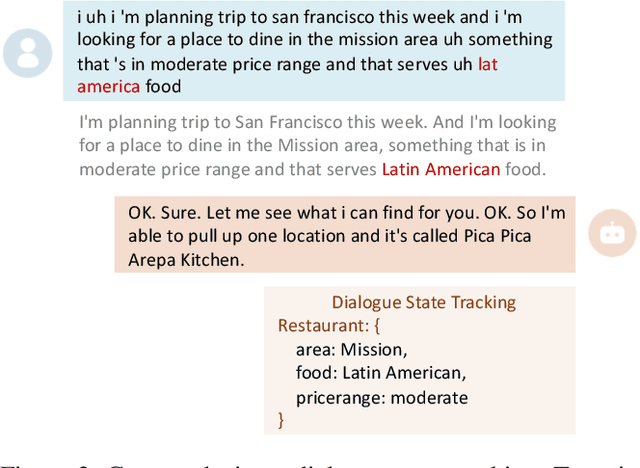
Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.
Amendable Generation for Dialogue State Tracking
Oct 29, 2021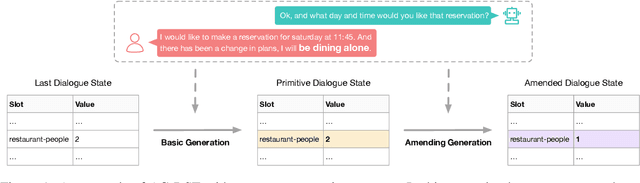
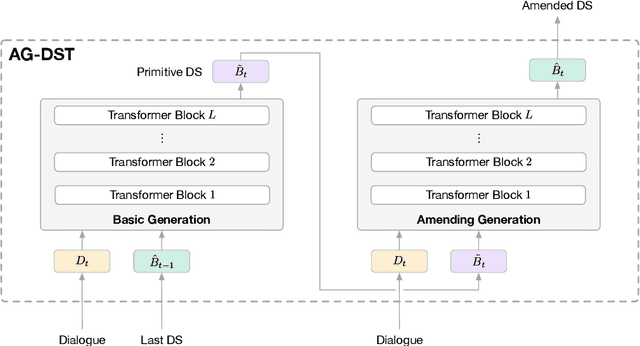
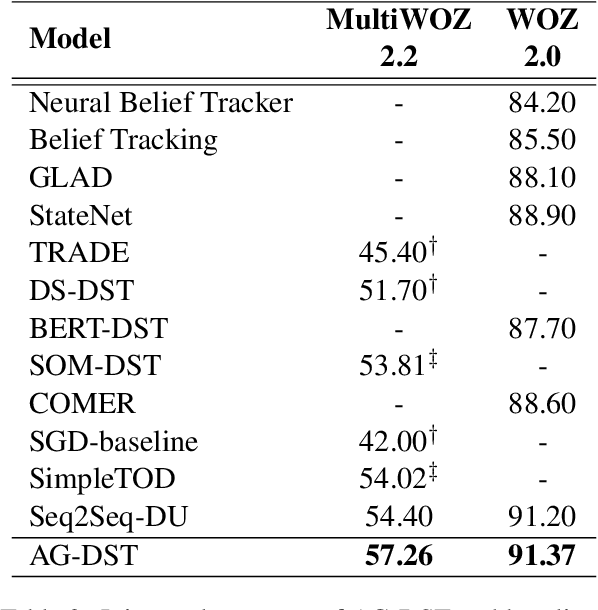
In task-oriented dialogue systems, recent dialogue state tracking methods tend to perform one-pass generation of the dialogue state based on the previous dialogue state. The mistakes of these models made at the current turn are prone to be carried over to the next turn, causing error propagation. In this paper, we propose a novel Amendable Generation for Dialogue State Tracking (AG-DST), which contains a two-pass generation process: (1) generating a primitive dialogue state based on the dialogue of the current turn and the previous dialogue state, and (2) amending the primitive dialogue state from the first pass. With the additional amending generation pass, our model is tasked to learn more robust dialogue state tracking by amending the errors that still exist in the primitive dialogue state, which plays the role of reviser in the double-checking process and alleviates unnecessary error propagation. Experimental results show that AG-DST significantly outperforms previous works in two active DST datasets (MultiWOZ 2.2 and WOZ 2.0), achieving new state-of-the-art performances.
Chinese Lexical Analysis with Deep Bi-GRU-CRF Network
Jul 05, 2018
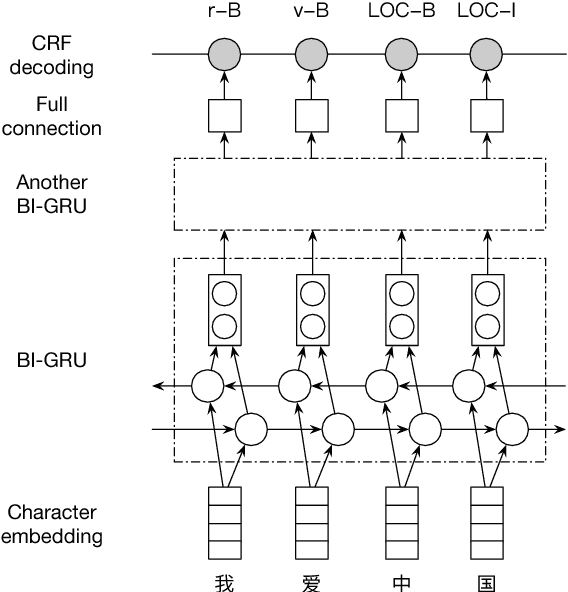


Lexical analysis is believed to be a crucial step towards natural language understanding and has been widely studied. Recent years, end-to-end lexical analysis models with recurrent neural networks have gained increasing attention. In this report, we introduce a deep Bi-GRU-CRF network that jointly models word segmentation, part-of-speech tagging and named entity recognition tasks. We trained the model using several massive corpus pre-tagged by our best Chinese lexical analysis tool, together with a small, yet high-quality human annotated corpus. We conducted balanced sampling between different corpora to guarantee the influence of human annotations, and fine-tune the CRF decoding layer regularly during the training progress. As evaluated by linguistic experts, the model achieved a 95.5% accuracy on the test set, roughly 13% relative error reduction over our (previously) best Chinese lexical analysis tool. The model is computationally efficient, achieving the speed of 2.3K characters per second with one thread.