 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Dense, Not Long: Dynamic Decoupled Conditional Advantage for Efficient Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) can elicit strong multi-step reasoning, yet it often encourages overly verbose traces. Moreover, naive length penalties in group-relative optimization can severely hurt accuracy. We attribute this failure to two structural issues: (i) Dilution of Length Baseline, where incorrect responses (with zero length reward) depress the group baseline and over-penalize correct solutions; and (ii) Difficulty-Penalty Mismatch, where a static penalty cannot adapt to problem difficulty, suppressing necessary reasoning on hard instances while leaving redundancy on easy ones. We propose Dynamic Decoupled Conditional Advantage (DDCA) to decouple efficiency optimization from correctness. DDCA computes length advantages conditionally within the correct-response cluster to eliminate baseline dilution, and dynamically scales the penalty strength using the group pass rate as a proxy for difficulty. Experiments on GSM8K, MATH500, AMC23, and AIME25 show that DDCA consistently improves the efficiency--accuracy trade-off relative to adaptive baselines, reducing generated tokens by approximately 60% on simpler tasks (e.g., GSM8K) versus over 20% on harder benchmarks (e.g., AIME25), thereby maintaining or improving accuracy. Code is available at https://github.com/alphadl/DDCA.
The Bitter Lesson of Diffusion Language Models for Agentic Workflows: A Comprehensive Reality Check
Jan 19, 2026The pursuit of real-time agentic interaction has driven interest in Diffusion-based Large Language Models (dLLMs) as alternatives to auto-regressive backbones, promising to break the sequential latency bottleneck. However, does such efficiency gains translate into effective agentic behavior? In this work, we present a comprehensive evaluation of dLLMs (e.g., LLaDA, Dream) across two distinct agentic paradigms: Embodied Agents (requiring long-horizon planning) and Tool-Calling Agents (requiring precise formatting). Contrary to the efficiency hype, our results on Agentboard and BFCL reveal a "bitter lesson": current dLLMs fail to serve as reliable agentic backbones, frequently leading to systematically failure. (1) In Embodied settings, dLLMs suffer repeated attempts, failing to branch under temporal feedback. (2) In Tool-Calling settings, dLLMs fail to maintain symbolic precision (e.g. strict JSON schemas) under diffusion noise. To assess the potential of dLLMs in agentic workflows, we introduce DiffuAgent, a multi-agent evaluation framework that integrates dLLMs as plug-and-play cognitive cores. Our analysis shows that dLLMs are effective in non-causal roles (e.g., memory summarization and tool selection) but require the incorporation of causal, precise, and logically grounded reasoning mechanisms into the denoising process to be viable for agentic tasks.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025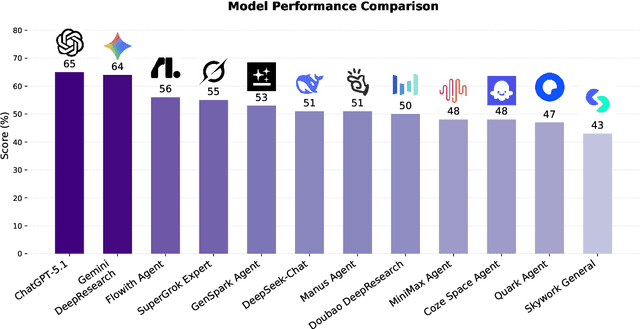
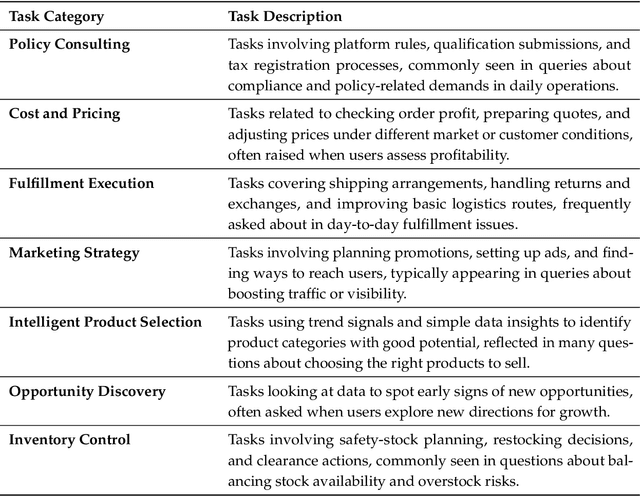

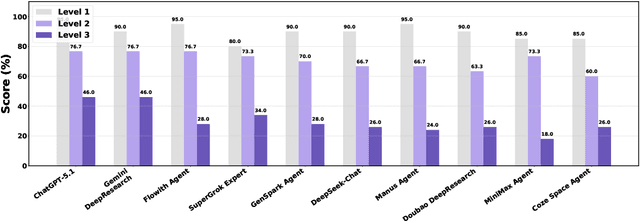
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Reason-KE++: Aligning the Process, Not Just the Outcome, for Faithful LLM Knowledge Editing
Nov 16, 2025



Aligning Large Language Models (LLMs) to be faithful to new knowledge in complex, multi-hop reasoning tasks is a critical, yet unsolved, challenge. We find that SFT-based methods, e.g., Reason-KE, while state-of-the-art, suffer from a "faithfulness gap": they optimize for format mimicry rather than sound reasoning. This gap enables the LLM's powerful parametric priors to override new contextual facts, resulting in critical factual hallucinations (e.g., incorrectly reasoning "Houston" from "NASA" despite an explicit edit). To solve this core LLM alignment problem, we propose Reason-KE++, an SFT+RL framework that instills process-level faithfulness. Its core is a Stage-aware Reward mechanism that provides dense supervision for intermediate reasoning steps (e.g., Decomposition, Sub-answer Correctness). Crucially, we identify that naive outcome-only RL is a deceptive trap for LLM alignment: it collapses reasoning integrity (e.g., 19.00% Hop acc) while superficially boosting final accuracy. Our process-aware framework sets a new SOTA of 95.48% on MQUAKE-CF-3k (+5.28%), demonstrating that for complex tasks, aligning the reasoning process is essential for building trustworthy LLMs.
PegasusFlow: Parallel Rolling-Denoising Score Sampling for Robot Diffusion Planner Flow Matching
Sep 10, 2025Diffusion models offer powerful generative capabilities for robot trajectory planning, yet their practical deployment on robots is hindered by a critical bottleneck: a reliance on imitation learning from expert demonstrations. This paradigm is often impractical for specialized robots where data is scarce and creates an inefficient, theoretically suboptimal training pipeline. To overcome this, we introduce PegasusFlow, a hierarchical rolling-denoising framework that enables direct and parallel sampling of trajectory score gradients from environmental interaction, completely bypassing the need for expert data. Our core innovation is a novel sampling algorithm, Weighted Basis Function Optimization (WBFO), which leverages spline basis representations to achieve superior sample efficiency and faster convergence compared to traditional methods like MPPI. The framework is embedded within a scalable, asynchronous parallel simulation architecture that supports massively parallel rollouts for efficient data collection. Extensive experiments on trajectory optimization and robotic navigation tasks demonstrate that our approach, particularly Action-Value WBFO (AVWBFO) combined with a reinforcement learning warm-start, significantly outperforms baselines. In a challenging barrier-crossing task, our method achieved a 100% success rate and was 18% faster than the next-best method, validating its effectiveness for complex terrain locomotion planning. https://masteryip.github.io/pegasusflow.github.io/
Whole-Body Constrained Learning for Legged Locomotion via Hierarchical Optimization
Jun 05, 2025Reinforcement learning (RL) has demonstrated impressive performance in legged locomotion over various challenging environments. However, due to the sim-to-real gap and lack of explainability, unconstrained RL policies deployed in the real world still suffer from inevitable safety issues, such as joint collisions, excessive torque, or foot slippage in low-friction environments. These problems limit its usage in missions with strict safety requirements, such as planetary exploration, nuclear facility inspection, and deep-sea operations. In this paper, we design a hierarchical optimization-based whole-body follower, which integrates both hard and soft constraints into RL framework to make the robot move with better safety guarantees. Leveraging the advantages of model-based control, our approach allows for the definition of various types of hard and soft constraints during training or deployment, which allows for policy fine-tuning and mitigates the challenges of sim-to-real transfer. Meanwhile, it preserves the robustness of RL when dealing with locomotion in complex unstructured environments. The trained policy with introduced constraints was deployed in a hexapod robot and tested in various outdoor environments, including snow-covered slopes and stairs, demonstrating the great traversability and safety of our approach.
AMIA: Automatic Masking and Joint Intention Analysis Makes LVLMs Robust Jailbreak Defenders
May 30, 2025We introduce AMIA, a lightweight, inference-only defense for Large Vision-Language Models (LVLMs) that (1) Automatically Masks a small set of text-irrelevant image patches to disrupt adversarial perturbations, and (2) conducts joint Intention Analysis to uncover and mitigate hidden harmful intents before response generation. Without any retraining, AMIA improves defense success rates across diverse LVLMs and jailbreak benchmarks from an average of 52.4% to 81.7%, preserves general utility with only a 2% average accuracy drop, and incurs only modest inference overhead. Ablation confirms both masking and intention analysis are essential for a robust safety-utility trade-off.
Revisiting Overthinking in Long Chain-of-Thought from the Perspective of Self-Doubt
May 29, 2025Reasoning Large Language Models (RLLMs) have demonstrated impressive performance on complex tasks, largely due to the adoption of Long Chain-of-Thought (Long CoT) reasoning. However, they often exhibit overthinking -- performing unnecessary reasoning steps even after arriving at the correct answer. Prior work has largely focused on qualitative analyses of overthinking through sample-based observations of long CoTs. In contrast, we present a quantitative analysis of overthinking from the perspective of self-doubt, characterized by excessive token usage devoted to re-verifying already-correct answer. We find that self-doubt significantly contributes to overthinking. In response, we introduce a simple and effective prompting method to reduce the model's over-reliance on input questions, thereby avoiding self-doubt. Specifically, we first prompt the model to question the validity of the input question, and then respond concisely based on the outcome of that evaluation. Experiments on three mathematical reasoning tasks and four datasets with missing premises demonstrate that our method substantially reduces answer length and yields significant improvements across nearly all datasets upon 4 widely-used RLLMs. Further analysis demonstrates that our method effectively minimizes the number of reasoning steps and reduces self-doubt.
Resolving Knowledge Conflicts in Domain-specific Data Selection: A Case Study on Medical Instruction-tuning
May 28, 2025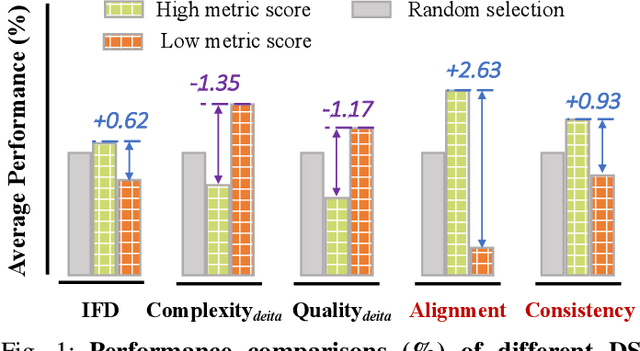
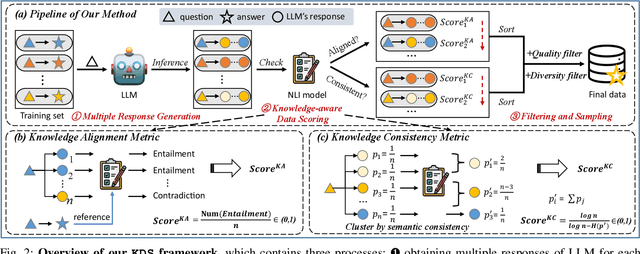
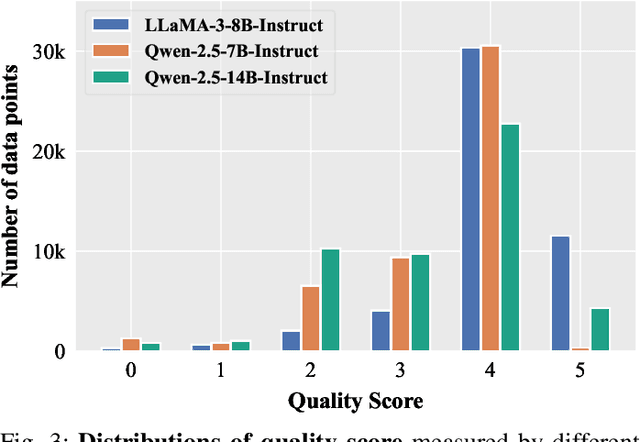
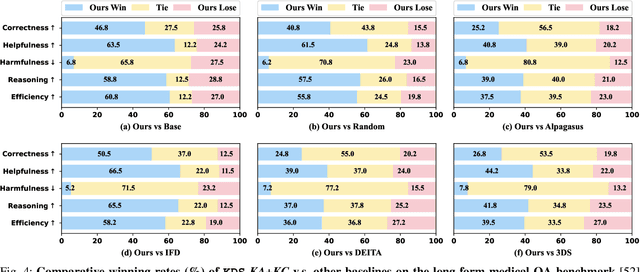
Domain-specific instruction-tuning has become the defacto standard for improving the performance of large language models (LLMs) in specialized applications, e.g., medical question answering. Since the instruction-tuning dataset might contain redundant or low-quality data, data selection (DS) is usually required to maximize the data efficiency. Despite the successes in the general domain, current DS methods often struggle to select the desired data for domain-specific instruction-tuning. One of the main reasons is that they neglect the impact of knowledge conflicts, i.e., the discrepancy between LLMs' pretrained knowledge and context knowledge of instruction data, which could damage LLMs' prior abilities and lead to hallucination. To this end, we propose a simple-yet-effective Knowledge-aware Data Selection (namely KDS) framework to select the domain-specific instruction-tuning data that meets LLMs' actual needs. The core of KDS is to leverage two knowledge-aware metrics for quantitatively measuring knowledge conflicts from two aspects: context-memory knowledge alignment and intra-memory knowledge consistency. By filtering the data with large knowledge conflicts and sampling the high-quality and diverse data, KDS can effectively stimulate the LLMs' abilities and achieve better domain-specific performance. Taking the medical domain as the testbed, we conduct extensive experiments and empirically prove that KDS surpasses the other baselines and brings significant and consistent performance gains among all LLMs. More encouragingly, KDS effectively improves the model generalization and alleviates the hallucination problem.
Runaway is Ashamed, But Helpful: On the Early-Exit Behavior of Large Language Model-based Agents in Embodied Environments
May 23, 2025Agents powered by large language models (LLMs) have demonstrated strong planning and decision-making capabilities in complex embodied environments. However, such agents often suffer from inefficiencies in multi-turn interactions, frequently trapped in repetitive loops or issuing ineffective commands, leading to redundant computational overhead. Instead of relying solely on learning from trajectories, we take a first step toward exploring the early-exit behavior for LLM-based agents. We propose two complementary approaches: 1. an $\textbf{intrinsic}$ method that injects exit instructions during generation, and 2. an $\textbf{extrinsic}$ method that verifies task completion to determine when to halt an agent's trial. To evaluate early-exit mechanisms, we introduce two metrics: one measures the reduction of $\textbf{redundant steps}$ as a positive effect, and the other evaluates $\textbf{progress degradation}$ as a negative effect. Experiments with 4 different LLMs across 5 embodied environments show significant efficiency improvements, with only minor drops in agent performance. We also validate a practical strategy where a stronger agent assists after an early-exit agent, achieving better performance with the same total steps. We will release our code to support further research.