 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs See Without Pixels? Benchmarking Spatial Intelligence from Textual Descriptions
Jan 07, 2026Recent advancements in Spatial Intelligence (SI) have predominantly relied on Vision-Language Models (VLMs), yet a critical question remains: does spatial understanding originate from visual encoders or the fundamental reasoning backbone? Inspired by this question, we introduce SiT-Bench, a novel benchmark designed to evaluate the SI performance of Large Language Models (LLMs) without pixel-level input, comprises over 3,800 expert-annotated items across five primary categories and 17 subtasks, ranging from egocentric navigation and perspective transformation to fine-grained robotic manipulation. By converting single/multi-view scenes into high-fidelity, coordinate-aware textual descriptions, we challenge LLMs to perform symbolic textual reasoning rather than visual pattern matching. Evaluation results of state-of-the-art (SOTA) LLMs reveals that while models achieve proficiency in localized semantic tasks, a significant "spatial gap" remains in global consistency. Notably, we find that explicit spatial reasoning significantly boosts performance, suggesting that LLMs possess latent world-modeling potential. Our proposed dataset SiT-Bench serves as a foundational resource to foster the development of spatially-grounded LLM backbones for future VLMs and embodied agents. Our code and benchmark will be released at https://github.com/binisalegend/SiT-Bench .
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025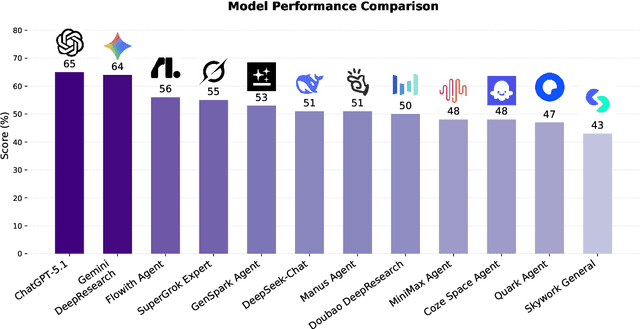
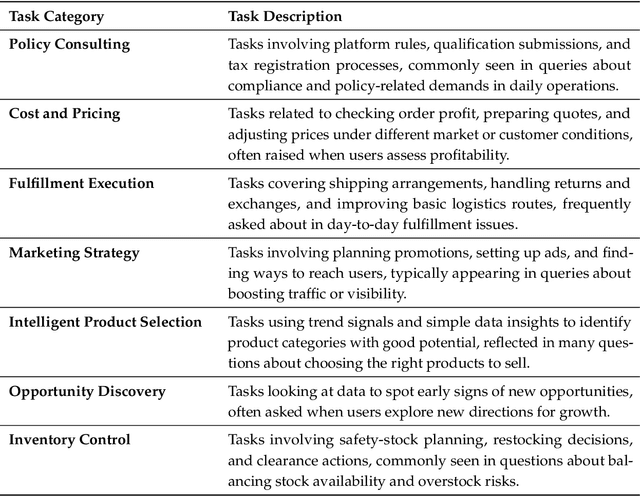

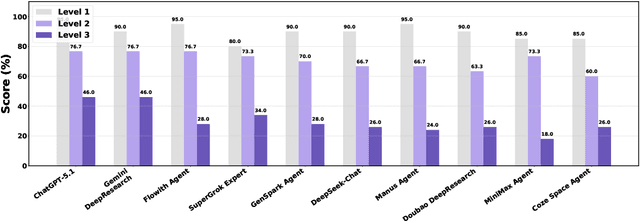
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Beyond Flatlands: Unlocking Spatial Intelligence by Decoupling 3D Reasoning from Numerical Regression
Nov 18, 2025



Existing Vision Language Models (VLMs) architecturally rooted in "flatland" perception, fundamentally struggle to comprehend real-world 3D spatial intelligence. This failure stems from a dual-bottleneck: input-stage conflict between computationally exorbitant geometric-aware encoders and superficial 2D-only features, and output-stage misalignment where discrete tokenizers are structurally incapable of producing precise, continuous numerical values. To break this impasse, we introduce GEODE (Geometric-Output and Decoupled-Input Engine), a novel architecture that resolves this dual-bottleneck by decoupling 3D reasoning from numerical generation. GEODE augments main VLM with two specialized, plug-and-play modules: Decoupled Rationale Module (DRM) that acts as spatial co-processor, aligning explicit 3D data with 2D visual features via cross-attention and distilling spatial Chain-of-Thought (CoT) logic into injectable Rationale Tokens; and Direct Regression Head (DRH), an "Embedding-as-Value" paradigm which routes specialized control tokens to a lightweight MLP for precise, continuous regression of scalars and 3D bounding boxes. The synergy of these modules allows our 1.5B parameter model to function as a high-level semantic dispatcher, achieving state-of-the-art spatial reasoning performance that rivals 7B+ models.
Can Predominant Credible Information Suppress Misinformation in Crises? Empirical Studies of Tweets Related to Prevention Measures during COVID-19
Feb 01, 2021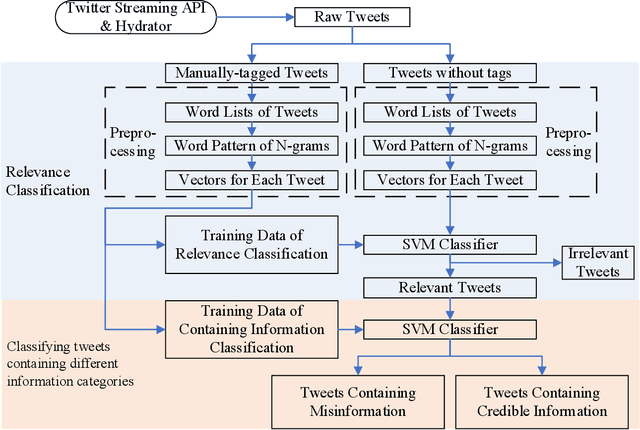
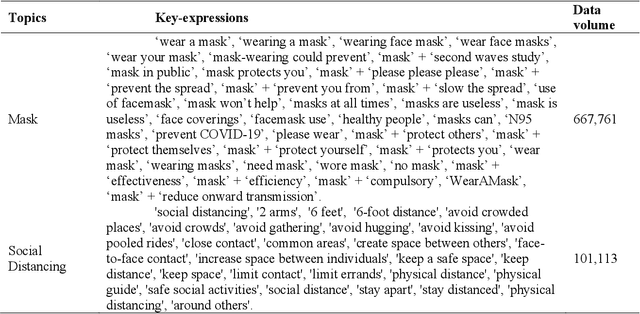
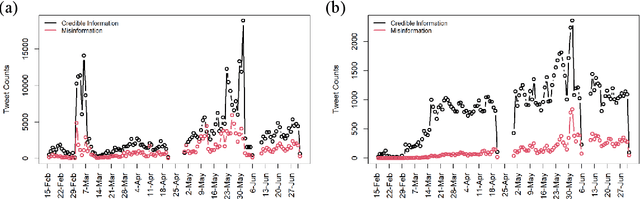
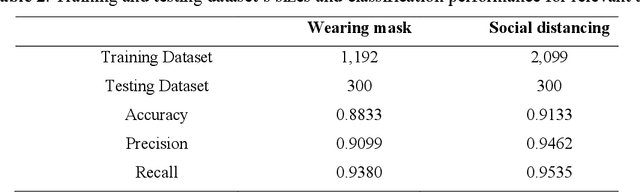
During COVID-19, misinformation on social media affects the adoption of appropriate prevention behaviors. It is urgent to suppress the misinformation to prevent negative public health consequences. Although an array of studies has proposed misinformation suppression strategies, few have investigated the role of predominant credible information during crises. None has examined its effect quantitatively using longitudinal social media data. Therefore, this research investigates the temporal correlations between credible information and misinformation, and whether predominant credible information can suppress misinformation for two prevention measures (i.e. topics), i.e. wearing masks and social distancing using tweets collected from February 15 to June 30, 2020. We trained Support Vector Machine classifiers to retrieve relevant tweets and classify tweets containing credible information and misinformation for each topic. Based on cross-correlation analyses of credible and misinformation time series for both topics, we find that the previously predominant credible information can lead to the decrease of misinformation (i.e. suppression) with a time lag. The research findings provide empirical evidence for suppressing misinformation with credible information in complex online environments and suggest practical strategies for future information management during crises and emergencies.