 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Knowledge Conflicts in Domain-specific Data Selection: A Case Study on Medical Instruction-tuning
Paper and Code
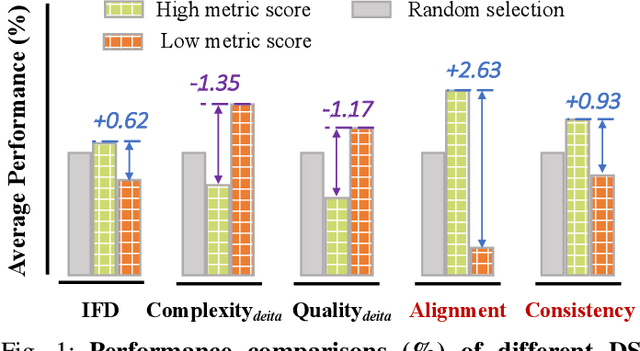
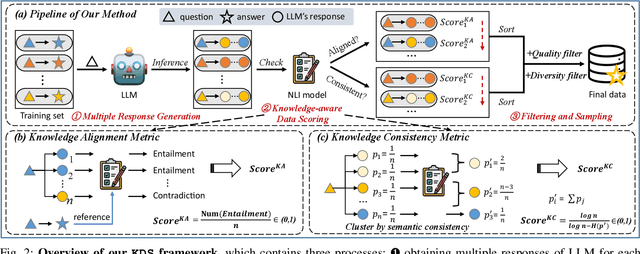
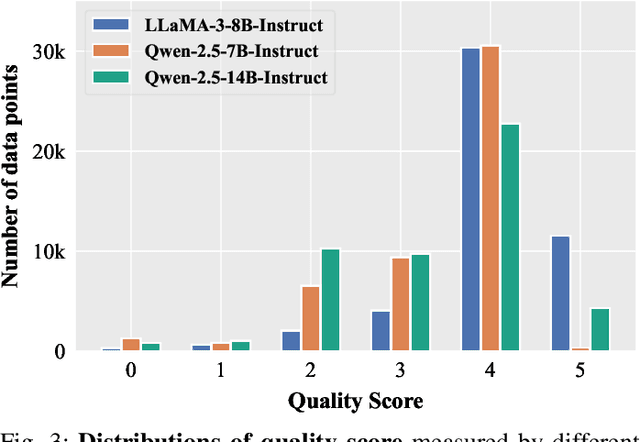
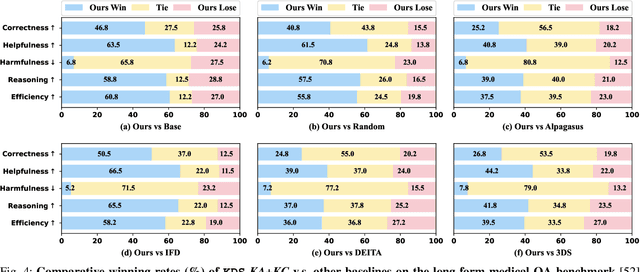
Domain-specific instruction-tuning has become the defacto standard for improving the performance of large language models (LLMs) in specialized applications, e.g., medical question answering. Since the instruction-tuning dataset might contain redundant or low-quality data, data selection (DS) is usually required to maximize the data efficiency. Despite the successes in the general domain, current DS methods often struggle to select the desired data for domain-specific instruction-tuning. One of the main reasons is that they neglect the impact of knowledge conflicts, i.e., the discrepancy between LLMs' pretrained knowledge and context knowledge of instruction data, which could damage LLMs' prior abilities and lead to hallucination. To this end, we propose a simple-yet-effective Knowledge-aware Data Selection (namely KDS) framework to select the domain-specific instruction-tuning data that meets LLMs' actual needs. The core of KDS is to leverage two knowledge-aware metrics for quantitatively measuring knowledge conflicts from two aspects: context-memory knowledge alignment and intra-memory knowledge consistency. By filtering the data with large knowledge conflicts and sampling the high-quality and diverse data, KDS can effectively stimulate the LLMs' abilities and achieve better domain-specific performance. Taking the medical domain as the testbed, we conduct extensive experiments and empirically prove that KDS surpasses the other baselines and brings significant and consistent performance gains among all LLMs. More encouragingly, KDS effectively improves the model generalization and alleviates the hallucination problem.