 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsking Before Action: Gather Information in Embodied Decision Making with Language Models
May 25, 2023With strong capabilities of reasoning and a generic understanding of the world, Large Language Models (LLMs) have shown great potential in building versatile embodied decision making agents capable of performing diverse tasks. However, when deployed to unfamiliar environments, we show that LLM agents face challenges in efficiently gathering necessary information, leading to suboptimal performance. On the other hand, in unfamiliar scenarios, human individuals often seek additional information from their peers before taking action, leveraging external knowledge to avoid unnecessary trial and error. Building upon this intuition, we propose \textit{Asking Before Action} (ABA), a method that empowers the agent to proactively query external sources for pertinent information using natural language during their interactions in the environment. In this way, the agent is able to enhance its efficiency and performance by mitigating wasteful steps and circumventing the difficulties associated with exploration in unfamiliar environments. We empirically evaluate our method on an embodied decision making benchmark, ALFWorld, and demonstrate that despite modest modifications in prompts, our method exceeds baseline LLM agents by more than $40$%. Further experiments on two variants of ALFWorld illustrate that by imitation learning, ABA effectively retains and reuses queried and known information in subsequent tasks, mitigating the need for repetitive inquiries. Both qualitative and quantitative results exhibit remarkable performance on tasks that previous methods struggle to solve.
Pointerformer: Deep Reinforced Multi-Pointer Transformer for the Traveling Salesman Problem
Apr 19, 2023



Traveling Salesman Problem (TSP), as a classic routing optimization problem originally arising in the domain of transportation and logistics, has become a critical task in broader domains, such as manufacturing and biology. Recently, Deep Reinforcement Learning (DRL) has been increasingly employed to solve TSP due to its high inference efficiency. Nevertheless, most of existing end-to-end DRL algorithms only perform well on small TSP instances and can hardly generalize to large scale because of the drastically soaring memory consumption and computation time along with the enlarging problem scale. In this paper, we propose a novel end-to-end DRL approach, referred to as Pointerformer, based on multi-pointer Transformer. Particularly, Pointerformer adopts both reversible residual network in the encoder and multi-pointer network in the decoder to effectively contain memory consumption of the encoder-decoder architecture. To further improve the performance of TSP solutions, Pointerformer employs both a feature augmentation method to explore the symmetries of TSP at both training and inference stages as well as an enhanced context embedding approach to include more comprehensive context information in the query. Extensive experiments on a randomly generated benchmark and a public benchmark have shown that, while achieving comparative results on most small-scale TSP instances as SOTA DRL approaches do, Pointerformer can also well generalize to large-scale TSPs.
H-TSP: Hierarchically Solving the Large-Scale Travelling Salesman Problem
Apr 19, 2023



We propose an end-to-end learning framework based on hierarchical reinforcement learning, called H-TSP, for addressing the large-scale Travelling Salesman Problem (TSP). The proposed H-TSP constructs a solution of a TSP instance starting from the scratch relying on two components: the upper-level policy chooses a small subset of nodes (up to 200 in our experiment) from all nodes that are to be traversed, while the lower-level policy takes the chosen nodes as input and outputs a tour connecting them to the existing partial route (initially only containing the depot). After jointly training the upper-level and lower-level policies, our approach can directly generate solutions for the given TSP instances without relying on any time-consuming search procedures. To demonstrate effectiveness of the proposed approach, we have conducted extensive experiments on randomly generated TSP instances with different numbers of nodes. We show that H-TSP can achieve comparable results (gap 3.42% vs. 7.32%) as SOTA search-based approaches, and more importantly, we reduce the time consumption up to two orders of magnitude (3.32s vs. 395.85s). To the best of our knowledge, H-TSP is the first end-to-end deep reinforcement learning approach that can scale to TSP instances of up to 10000 nodes. Although there are still gaps to SOTA results with respect to solution quality, we believe that H-TSP will be useful for practical applications, particularly those that are time-sensitive e.g., on-call routing and ride hailing service.
Deep Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Feb 17, 2023
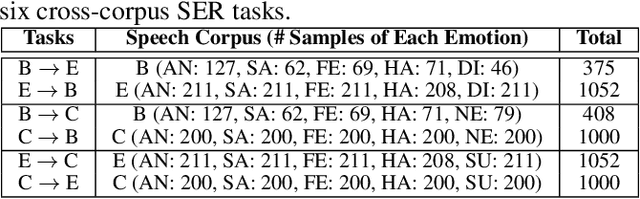
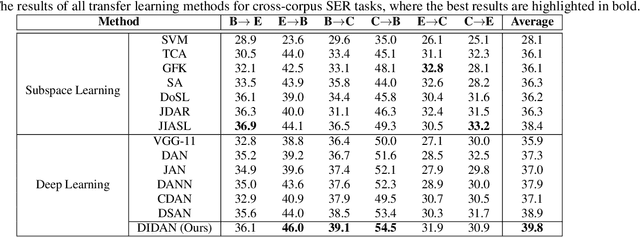
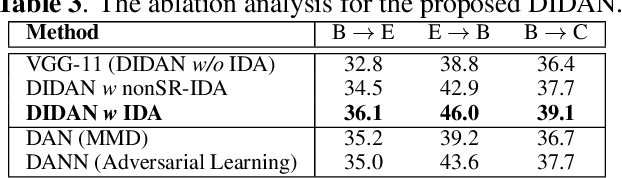
In this paper, we propose a novel deep transfer learning method called deep implicit distribution alignment networks (DIDAN) to deal with cross-corpus speech emotion recognition (SER) problem, in which the labeled training (source) and unlabeled testing (target) speech signals come from different corpora. Specifically, DIDAN first adopts a simple deep regression network consisting of a set of convolutional and fully connected layers to directly regress the source speech spectrums into the emotional labels such that the proposed DIDAN can own the emotion discriminative ability. Then, such ability is transferred to be also applicable to the target speech samples regardless of corpus variance by resorting to a well-designed regularization term called implicit distribution alignment (IDA). Unlike widely-used maximum mean discrepancy (MMD) and its variants, the proposed IDA absorbs the idea of sample reconstruction to implicitly align the distribution gap, which enables DIDAN to learn both emotion discriminative and corpus invariant features from speech spectrums. To evaluate the proposed DIDAN, extensive cross-corpus SER experiments on widely-used speech emotion corpora are carried out. Experimental results show that the proposed DIDAN can outperform lots of recent state-of-the-art methods in coping with the cross-corpus SER tasks.
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
Dec 24, 2022One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textit{\textbf{Se}gmented \textbf{C}ontext \textbf{B}elief \textbf{A}ugmented \textbf{D}eep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.
Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management
Dec 18, 2022



In this paper, we consider the inventory management (IM) problem where we need to make replenishment decisions for a large number of stock keeping units (SKUs) to balance their supply and demand. In our setting, the constraint on the shared resources (such as the inventory capacity) couples the otherwise independent control for each SKU. We formulate the problem with this structure as Shared-Resource Stochastic Game (SRSG)and propose an efficient algorithm called Context-aware Decentralized PPO (CD-PPO). Through extensive experiments, we demonstrate that CD-PPO can accelerate the learning procedure compared with standard MARL algorithms.
TD3 with Reverse KL Regularizer for Offline Reinforcement Learning from Mixed Datasets
Dec 05, 2022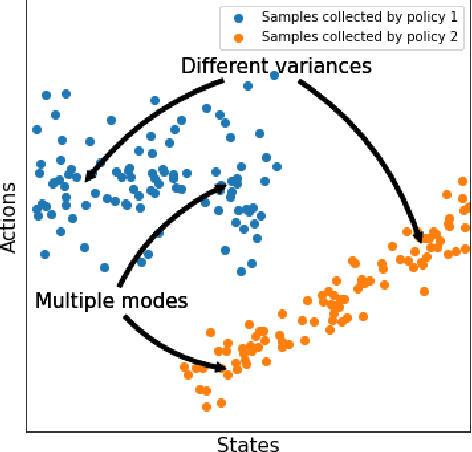
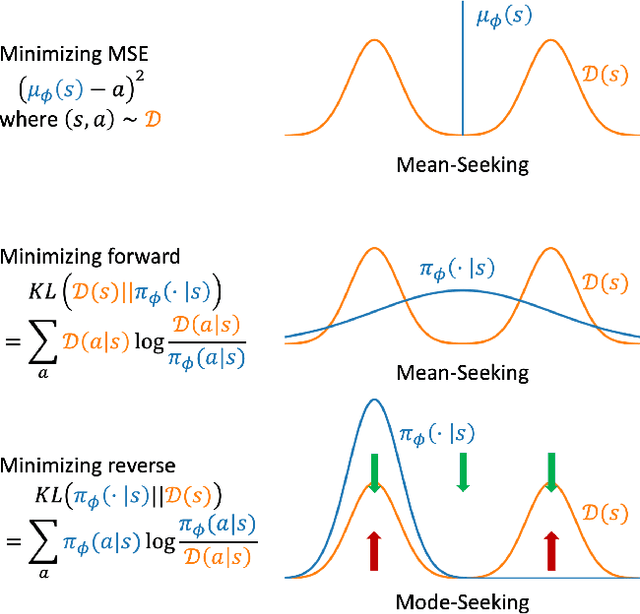
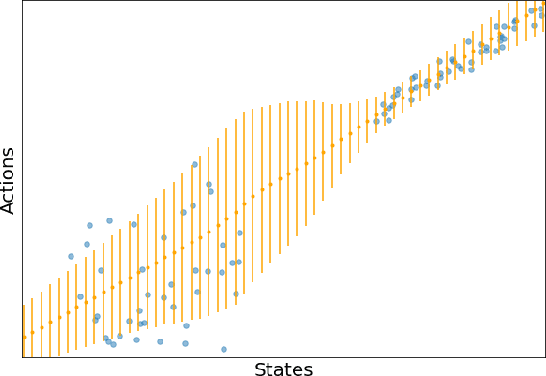
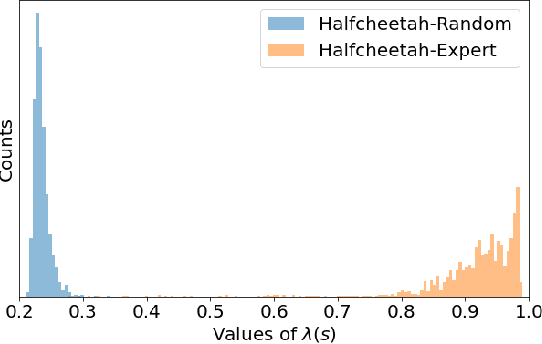
We consider an offline reinforcement learning (RL) setting where the agent need to learn from a dataset collected by rolling out multiple behavior policies. There are two challenges for this setting: 1) The optimal trade-off between optimizing the RL signal and the behavior cloning (BC) signal changes on different states due to the variation of the action coverage induced by different behavior policies. Previous methods fail to handle this by only controlling the global trade-off. 2) For a given state, the action distribution generated by different behavior policies may have multiple modes. The BC regularizers in many previous methods are mean-seeking, resulting in policies that select out-of-distribution (OOD) actions in the middle of the modes. In this paper, we address both challenges by using adaptively weighted reverse Kullback-Leibler (KL) divergence as the BC regularizer based on the TD3 algorithm. Our method not only trades off the RL and BC signals with per-state weights (i.e., strong BC regularization on the states with narrow action coverage, and vice versa) but also avoids selecting OOD actions thanks to the mode-seeking property of reverse KL. Empirically, our algorithm can outperform existing offline RL algorithms in the MuJoCo locomotion tasks with the standard D4RL datasets as well as the mixed datasets that combine the standard datasets.
Inspector: Pixel-Based Automated Game Testing via Exploration, Detection, and Investigation
Jul 18, 2022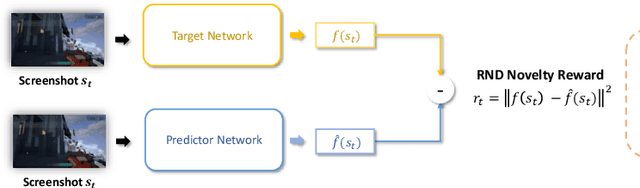
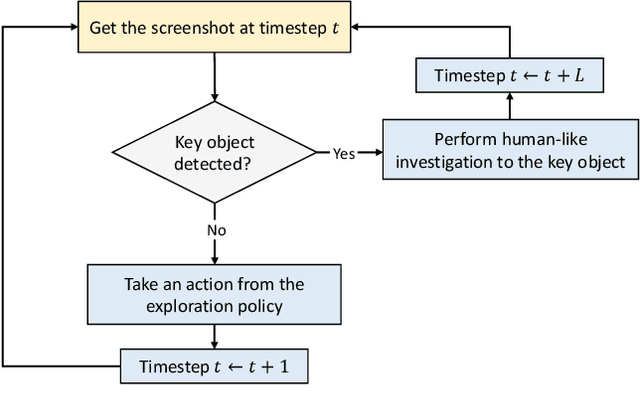

Deep reinforcement learning (DRL) has attracted much attention in automated game testing. Early attempts rely on game internal information for game space exploration, thus requiring deep integration with games, which is inconvenient for practical applications. In this work, we propose using only screenshots/pixels as input for automated game testing and build a general game testing agent, Inspector, that can be easily applied to different games without deep integration with games. In addition to covering all game space for testing, our agent tries to take human-like behaviors to interact with key objects in a game, since some bugs usually happen in player-object interactions. Inspector is based on purely pixel inputs and comprises three key modules: game space explorer, key object detector, and human-like object investigator. Game space explorer aims to explore the whole game space by using a curiosity-based reward function with pixel inputs. Key object detector aims to detect key objects in a game, based on a small number of labeled screenshots. Human-like object investigator aims to mimic human behaviors for investigating key objects via imitation learning. We conduct experiments on two popular video games: Shooter Game and Action RPG Game. Experiment results demonstrate the effectiveness of Inspector in exploring game space, detecting key objects, and investigating objects. Moreover, Inspector successfully discovers two potential bugs in those two games. The demo video of Inspector is available at https://github.com/Inspector-GameTesting/Inspector-GameTesting.
Tiered Reinforcement Learning: Pessimism in the Face of Uncertainty and Constant Regret
May 25, 2022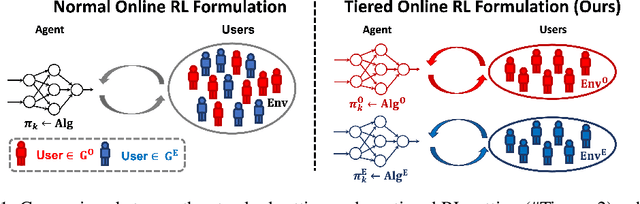
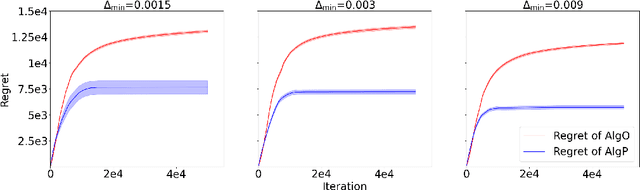
We propose a new learning framework that captures the tiered structure of many real-world user-interaction applications, where the users can be divided into two groups based on their different tolerance on exploration risks and should be treated separately. In this setting, we simultaneously maintain two policies $\pi^{\text{O}}$ and $\pi^{\text{E}}$: $\pi^{\text{O}}$ ("O" for "online") interacts with more risk-tolerant users from the first tier and minimizes regret by balancing exploration and exploitation as usual, while $\pi^{\text{E}}$ ("E" for "exploit") exclusively focuses on exploitation for risk-averse users from the second tier utilizing the data collected so far. An important question is whether such a separation yields advantages over the standard online setting (i.e., $\pi^{\text{E}}=\pi^{\text{O}}$) for the risk-averse users. We individually consider the gap-independent vs.~gap-dependent settings. For the former, we prove that the separation is indeed not beneficial from a minimax perspective. For the latter, we show that if choosing Pessimistic Value Iteration as the exploitation algorithm to produce $\pi^{\text{E}}$, we can achieve a constant regret for risk-averse users independent of the number of episodes $K$, which is in sharp contrast to the $\Omega(\log K)$ regret for any online RL algorithms in the same setting, while the regret of $\pi^{\text{O}}$ (almost) maintains its online regret optimality and does not need to compromise for the success of $\pi^{\text{E}}$.
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022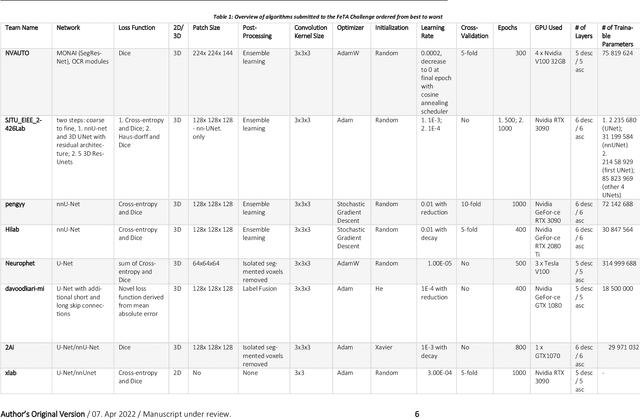
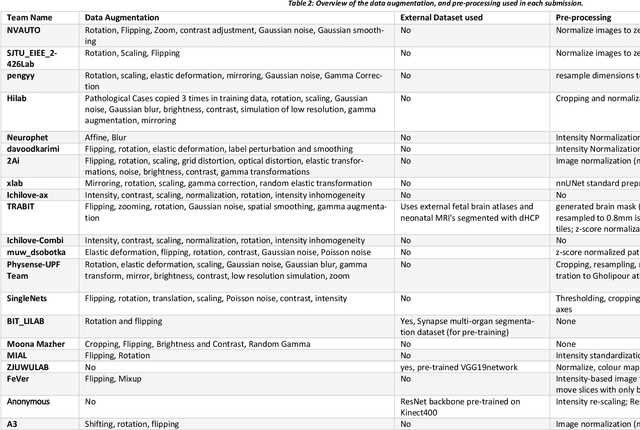
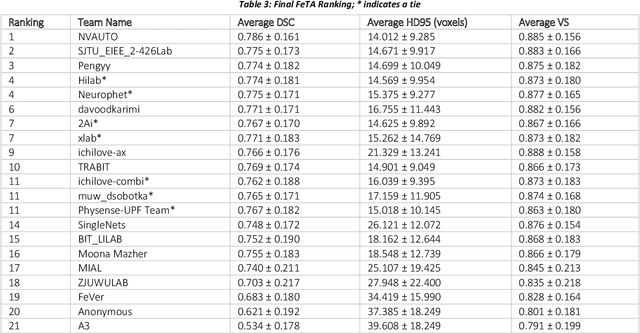
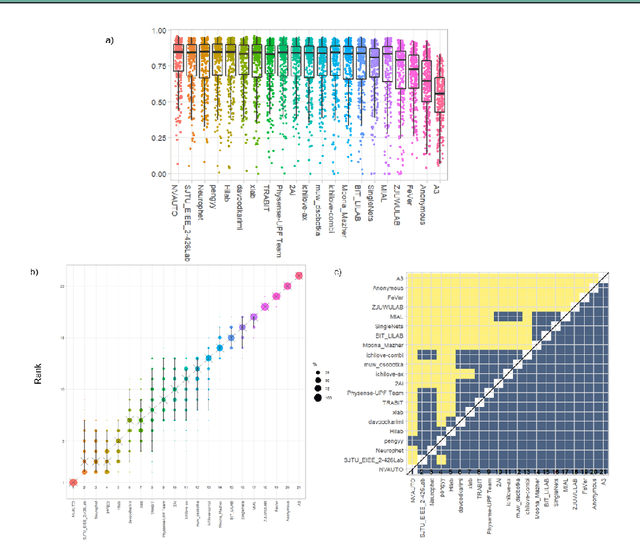
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.