 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025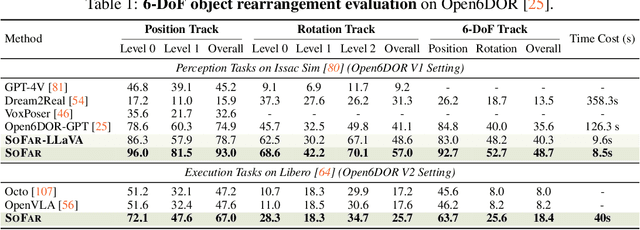

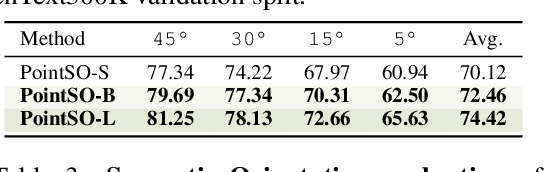
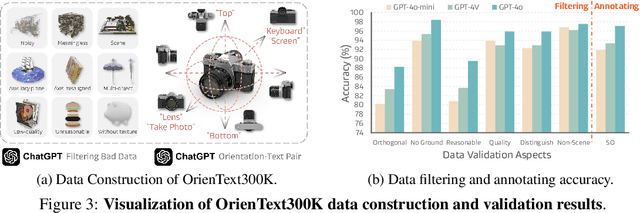
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
DexTrack: Towards Generalizable Neural Tracking Control for Dexterous Manipulation from Human References
Feb 13, 2025We address the challenge of developing a generalizable neural tracking controller for dexterous manipulation from human references. This controller aims to manage a dexterous robot hand to manipulate diverse objects for various purposes defined by kinematic human-object interactions. Developing such a controller is complicated by the intricate contact dynamics of dexterous manipulation and the need for adaptivity, generalizability, and robustness. Current reinforcement learning and trajectory optimization methods often fall short due to their dependence on task-specific rewards or precise system models. We introduce an approach that curates large-scale successful robot tracking demonstrations, comprising pairs of human references and robot actions, to train a neural controller. Utilizing a data flywheel, we iteratively enhance the controller's performance, as well as the number and quality of successful tracking demonstrations. We exploit available tracking demonstrations and carefully integrate reinforcement learning and imitation learning to boost the controller's performance in dynamic environments. At the same time, to obtain high-quality tracking demonstrations, we individually optimize per-trajectory tracking by leveraging the learned tracking controller in a homotopy optimization method. The homotopy optimization, mimicking chain-of-thought, aids in solving challenging trajectory tracking problems to increase demonstration diversity. We showcase our success by training a generalizable neural controller and evaluating it in both simulation and real world. Our method achieves over a 10% improvement in success rates compared to leading baselines. The project website with animated results is available at https://meowuu7.github.io/DexTrack/.
GaussianAvatar-Editor: Photorealistic Animatable Gaussian Head Avatar Editor
Jan 17, 2025We introduce GaussianAvatar-Editor, an innovative framework for text-driven editing of animatable Gaussian head avatars that can be fully controlled in expression, pose, and viewpoint. Unlike static 3D Gaussian editing, editing animatable 4D Gaussian avatars presents challenges related to motion occlusion and spatial-temporal inconsistency. To address these issues, we propose the Weighted Alpha Blending Equation (WABE). This function enhances the blending weight of visible Gaussians while suppressing the influence on non-visible Gaussians, effectively handling motion occlusion during editing. Furthermore, to improve editing quality and ensure 4D consistency, we incorporate conditional adversarial learning into the editing process. This strategy helps to refine the edited results and maintain consistency throughout the animation. By integrating these methods, our GaussianAvatar-Editor achieves photorealistic and consistent results in animatable 4D Gaussian editing. We conduct comprehensive experiments across various subjects to validate the effectiveness of our proposed techniques, which demonstrates the superiority of our approach over existing methods. More results and code are available at: [Project Link](https://xiangyueliu.github.io/GaussianAvatar-Editor/).
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Jan 08, 2025



This paper introduces MobileH2R, a framework for learning generalizable vision-based human-to-mobile-robot (H2MR) handover skills. Unlike traditional fixed-base handovers, this task requires a mobile robot to reliably receive objects in a large workspace enabled by its mobility. Our key insight is that generalizable handover skills can be developed in simulators using high-quality synthetic data, without the need for real-world demonstrations. To achieve this, we propose a scalable pipeline for generating diverse synthetic full-body human motion data, an automated method for creating safe and imitation-friendly demonstrations, and an efficient 4D imitation learning method for distilling large-scale demonstrations into closed-loop policies with base-arm coordination. Experimental evaluations in both simulators and the real world show significant improvements (at least +15% success rate) over baseline methods in all cases. Experiments also validate that large-scale and diverse synthetic data greatly enhances robot learning, highlighting our scalable framework.
SyncDiff: Synchronized Motion Diffusion for Multi-Body Human-Object Interaction Synthesis
Dec 28, 2024



Synthesizing realistic human-object interaction motions is a critical problem in VR/AR and human animation. Unlike the commonly studied scenarios involving a single human or hand interacting with one object, we address a more generic multi-body setting with arbitrary numbers of humans, hands, and objects. This complexity introduces significant challenges in synchronizing motions due to the high correlations and mutual influences among bodies. To address these challenges, we introduce SyncDiff, a novel method for multi-body interaction synthesis using a synchronized motion diffusion strategy. SyncDiff employs a single diffusion model to capture the joint distribution of multi-body motions. To enhance motion fidelity, we propose a frequency-domain motion decomposition scheme. Additionally, we introduce a new set of alignment scores to emphasize the synchronization of different body motions. SyncDiff jointly optimizes both data sample likelihood and alignment likelihood through an explicit synchronization strategy. Extensive experiments across four datasets with various multi-body configurations demonstrate the superiority of SyncDiff over existing state-of-the-art motion synthesis methods.
Mimicking-Bench: A Benchmark for Generalizable Humanoid-Scene Interaction Learning via Human Mimicking
Dec 23, 2024Learning generic skills for humanoid robots interacting with 3D scenes by mimicking human data is a key research challenge with significant implications for robotics and real-world applications. However, existing methodologies and benchmarks are constrained by the use of small-scale, manually collected demonstrations, lacking the general dataset and benchmark support necessary to explore scene geometry generalization effectively. To address this gap, we introduce Mimicking-Bench, the first comprehensive benchmark designed for generalizable humanoid-scene interaction learning through mimicking large-scale human animation references. Mimicking-Bench includes six household full-body humanoid-scene interaction tasks, covering 11K diverse object shapes, along with 20K synthetic and 3K real-world human interaction skill references. We construct a complete humanoid skill learning pipeline and benchmark approaches for motion retargeting, motion tracking, imitation learning, and their various combinations. Extensive experiments highlight the value of human mimicking for skill learning, revealing key challenges and research directions.
UniHOI: Learning Fast, Dense and Generalizable 4D Reconstruction for Egocentric Hand Object Interaction Videos
Nov 14, 2024Egocentric Hand Object Interaction (HOI) videos provide valuable insights into human interactions with the physical world, attracting growing interest from the computer vision and robotics communities. A key task in fully understanding the geometry and dynamics of HOI scenes is dense pointclouds sequence reconstruction. However, the inherent motion of both hands and the camera makes this challenging. Current methods often rely on time-consuming test-time optimization, making them impractical for reconstructing internet-scale videos. To address this, we introduce UniHOI, a model that unifies the estimation of all variables necessary for dense 4D reconstruction, including camera intrinsic, camera poses, and video depth, for egocentric HOI scene in a fast feed-forward manner. We end-to-end optimize all these variables to improve their consistency in 3D space. Furthermore, our model could be trained solely on large-scale monocular video dataset, overcoming the limitation of scarce labeled HOI data. We evaluate UniHOI with both in-domain and zero-shot generalization setting, surpassing all baselines in pointclouds sequence reconstruction and long-term 3D scene flow recovery. UniHOI is the first approach to offer fast, dense, and generalizable monocular egocentric HOI scene reconstruction in the presence of motion. Code and trained model will be released in the future.
ImOV3D: Learning Open-Vocabulary Point Clouds 3D Object Detection from Only 2D Images
Oct 31, 2024Open-vocabulary 3D object detection (OV-3Det) aims to generalize beyond the limited number of base categories labeled during the training phase. The biggest bottleneck is the scarcity of annotated 3D data, whereas 2D image datasets are abundant and richly annotated. Consequently, it is intuitive to leverage the wealth of annotations in 2D images to alleviate the inherent data scarcity in OV-3Det. In this paper, we push the task setup to its limits by exploring the potential of using solely 2D images to learn OV-3Det. The major challenges for this setup is the modality gap between training images and testing point clouds, which prevents effective integration of 2D knowledge into OV-3Det. To address this challenge, we propose a novel framework ImOV3D to leverage pseudo multimodal representation containing both images and point clouds (PC) to close the modality gap. The key of ImOV3D lies in flexible modality conversion where 2D images can be lifted into 3D using monocular depth estimation and can also be derived from 3D scenes through rendering. This allows unifying both training images and testing point clouds into a common image-PC representation, encompassing a wealth of 2D semantic information and also incorporating the depth and structural characteristics of 3D spatial data. We carefully conduct such conversion to minimize the domain gap between training and test cases. Extensive experiments on two benchmark datasets, SUNRGBD and ScanNet, show that ImOV3D significantly outperforms existing methods, even in the absence of ground truth 3D training data. With the inclusion of a minimal amount of real 3D data for fine-tuning, the performance also significantly surpasses previous state-of-the-art. Codes and pre-trained models are released on the https://github.com/yangtiming/ImOV3D.
MAP: Unleashing Hybrid Mamba-Transformer Vision Backbone's Potential with Masked Autoregressive Pretraining
Oct 01, 2024Mamba has achieved significant advantages in long-context modeling and autoregressive tasks, but its scalability with large parameters remains a major limitation in vision applications. pretraining is a widely used strategy to enhance backbone model performance. Although the success of Masked Autoencoder in Transformer pretraining is well recognized, it does not significantly improve Mamba's visual learning performance. We found that using the correct autoregressive pretraining can significantly boost the performance of the Mamba architecture. Based on this analysis, we propose Masked Autoregressive Pretraining (MAP) to pretrain a hybrid Mamba-Transformer vision backbone network. This strategy combines the strengths of both MAE and Autoregressive pretraining, improving the performance of Mamba and Transformer modules within a unified paradigm. Additionally, in terms of integrating Mamba and Transformer modules, we empirically found that inserting Transformer layers at regular intervals within Mamba layers can significantly enhance downstream task performance. Experimental results show that both the pure Mamba architecture and the hybrid Mamba-Transformer vision backbone network pretrained with MAP significantly outperform other pretraining strategies, achieving state-of-the-art performance. We validate the effectiveness of the method on both 2D and 3D datasets and provide detailed ablation studies to support the design choices for each component.
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Sep 06, 2024



VILA-U is a Unified foundation model that integrates Video, Image, Language understanding and generation. Traditional visual language models (VLMs) use separate modules for understanding and generating visual content, which can lead to misalignment and increased complexity. In contrast, VILA-U employs a single autoregressive next-token prediction framework for both tasks, eliminating the need for additional components like diffusion models. This approach not only simplifies the model but also achieves near state-of-the-art performance in visual language understanding and generation. The success of VILA-U is attributed to two main factors: the unified vision tower that aligns discrete visual tokens with textual inputs during pretraining, which enhances visual perception, and autoregressive image generation can achieve similar quality as diffusion models with high-quality dataset. This allows VILA-U to perform comparably to more complex models using a fully token-based autoregressive framework.