 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Sequence Learning for Cross-domain Recommendation
Apr 11, 2023Cross-domain recommendation (CDR) aims to leverage the users' behaviors in both source and target domains to improve the target domain's performance. Conventional CDR methods typically explore the dual relations between the source and target domains' behavior sequences. However, they ignore modeling the third sequence of mixed behaviors that naturally reflects the user's global preference. To address this issue, we present a novel and model-agnostic Triple sequence learning for cross-domain recommendation (Tri-CDR) framework to jointly model the source, target, and mixed behavior sequences in CDR. Specifically, Tri-CDR independently models the hidden user representations for the source, target, and mixed behavior sequences, and proposes a triple cross-domain attention (TCA) to emphasize the informative knowledge related to both user's target-domain preference and global interests in three sequences. To comprehensively learn the triple correlations, we design a novel triple contrastive learning (TCL) that jointly considers coarse-grained similarities and fine-grained distinctions among three sequences, ensuring the alignment while preserving the information diversity in multi-domain. We conduct extensive experiments and analyses on two real-world datasets with four domains. The significant improvements of Tri-CDR with different sequential encoders on all datasets verify the effectiveness and universality. The source code will be released in the future.
Improve Transformer Pre-Training with Decoupled Directional Relative Position Encoding and Representation Differentiations
Oct 09, 2022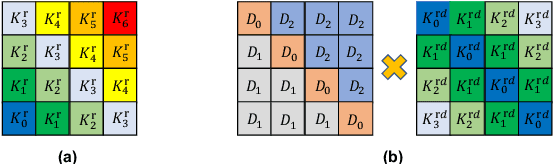
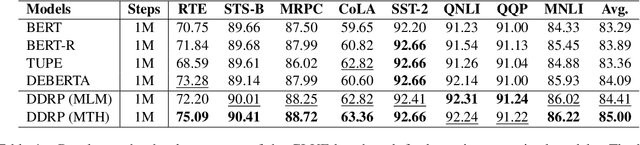
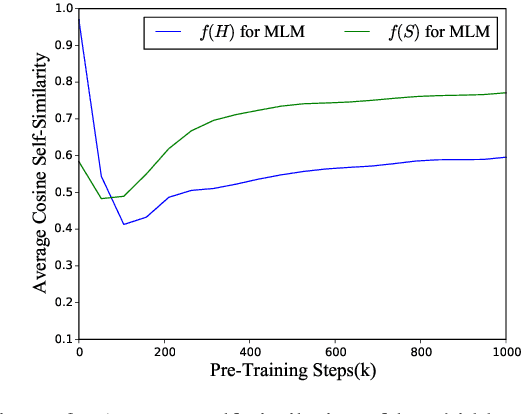
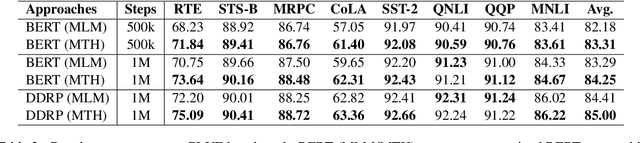
In this work, we revisit the Transformer-based pre-trained language models and identify two problems that may limit the expressiveness of the model. Firstly, existing relative position encoding models (e.g., T5 and DEBERTA) confuse two heterogeneous information: relative distance and direction. It may make the model unable to capture the associative semantics of the same direction or the same distance, which in turn affects the performance of downstream tasks. Secondly, we notice the pre-trained BERT with Mask Language Modeling (MLM) pre-training objective outputs similar token representations and attention weights of different heads, which may impose difficulties in capturing discriminative semantic representations. Motivated by the above investigation, we propose two novel techniques to improve pre-trained language models: Decoupled Directional Relative Position (DDRP) encoding and MTH pre-training objective. DDRP decouples the relative distance features and the directional features in classical relative position encoding for better position information understanding. MTH designs two novel auxiliary losses besides MLM to enlarge the dissimilarities between (a) last hidden states of different tokens, and (b) attention weights of different heads, alleviating homogenization and anisotropic problem in representation learning for better optimization. Extensive experiments and ablation studies on GLUE benchmark demonstrate the effectiveness of our proposed methods.
Reweighting Clicks with Dwell Time in Recommendation
Sep 19, 2022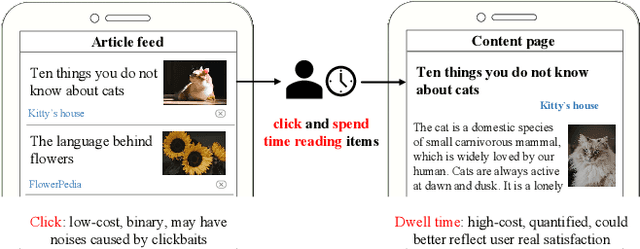

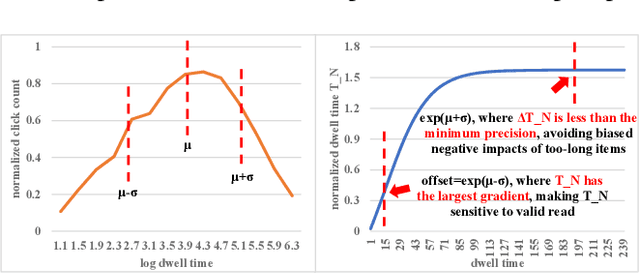
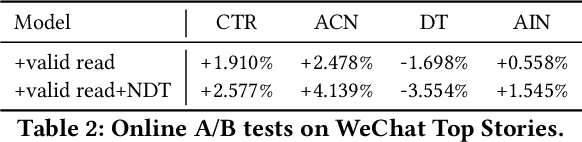
The click behavior is the most widely-used user positive feedback in recommendation. However, simply considering each click equally in training may suffer from clickbaits and title-content mismatching, and thus fail to precisely capture users' real satisfaction on items. Dwell time could be viewed as a high-quality quantitative indicator of user preferences on each click, while existing recommendation models do not fully explore the modeling of dwell time. In this work, we focus on reweighting clicks with dwell time in recommendation. Precisely, we first define a new behavior named valid read, which helps to select high-quality click instances for different users and items via dwell time. Next, we propose a normalized dwell time function to reweight click signals in training, which could better guide our model to provide a high-quality and efficient reading. The Click reweighting model achieves significant improvements on both offline and online evaluations in a real-world system.
UFNRec: Utilizing False Negative Samples for Sequential Recommendation
Aug 08, 2022



Sequential recommendation models are primarily optimized to distinguish positive samples from negative ones during training in which negative sampling serves as an essential component in learning the evolving user preferences through historical records. Except for randomly sampling negative samples from a uniformly distributed subset, many delicate methods have been proposed to mine negative samples with high quality. However, due to the inherent randomness of negative sampling, false negative samples are inevitably collected in model training. Current strategies mainly focus on removing such false negative samples, which leads to overlooking potential user interests, lack of recommendation diversity, less model robustness, and suffering from exposure bias. To this end, we propose a novel method that can Utilize False Negative samples for sequential Recommendation (UFNRec) to improve model performance. We first devise a simple strategy to extract false negative samples and then transfer these samples to positive samples in the following training process. Furthermore, we construct a teacher model to provide soft labels for false negative samples and design a consistency loss to regularize the predictions of these samples from the student model and the teacher model. To the best of our knowledge, this is the first work to utilize false negative samples instead of simply removing them for the sequential recommendation. Experiments on three benchmark public datasets are conducted using three widely applied SOTA models. The experiment results demonstrate that our proposed UFNRec can effectively draw information from false negative samples and further improve the performance of SOTA models. The code is available at https://github.com/UFNRec-code/UFNRec.
Multi-granularity Item-based Contrastive Recommendation
Jul 04, 2022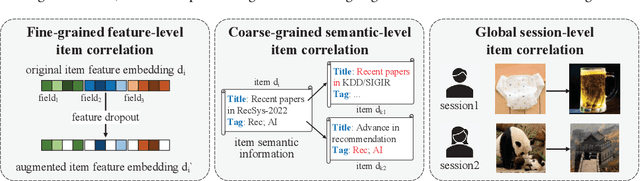

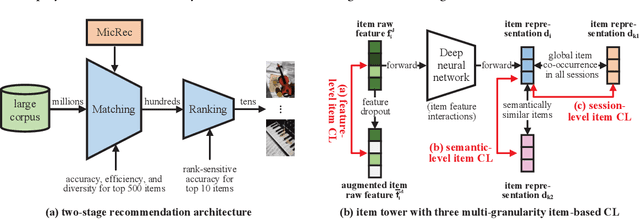
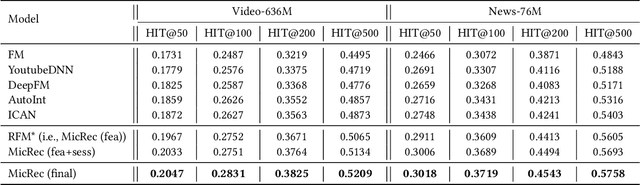
Contrastive learning (CL) has shown its power in recommendation. However, most CL-based recommendation models build their CL tasks merely focusing on the user's aspects, ignoring the rich diverse information in items. In this work, we propose a novel Multi-granularity item-based contrastive learning (MicRec) framework for the matching stage (i.e., candidate generation) in recommendation, which systematically introduces multi-aspect item-related information to representation learning with CL. Specifically, we build three item-based CL tasks as a set of plug-and-play auxiliary objectives to capture item correlations in feature, semantic and session levels. The feature-level item CL aims to learn the fine-grained feature-level item correlations via items and their augmentations. The semantic-level item CL focuses on the coarse-grained semantic correlations between semantically related items. The session-level item CL highlights the global behavioral correlations of items from users' sequential behaviors in all sessions. In experiments, we conduct both offline and online evaluations on real-world datasets, where MicRec achieves significant improvements over competitive baselines. Moreover, we further verify the effectiveness of three CL tasks as well as the universality of MicRec on different matching models. The proposed MicRec is effective, efficient, universal, and easy to deploy, which has been deployed on a real-world recommendation system, affecting millions of users. The source code will be released in the future.
Prompt Tuning for Discriminative Pre-trained Language Models
May 23, 2022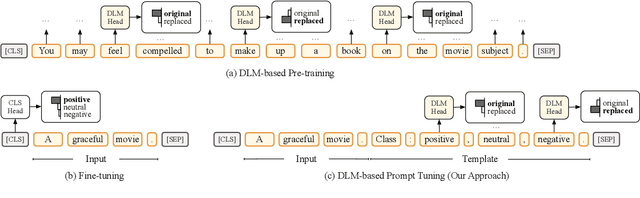
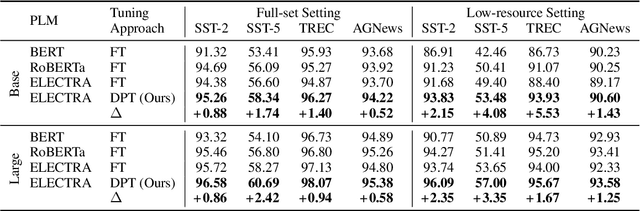
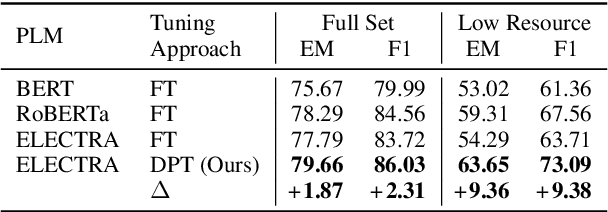
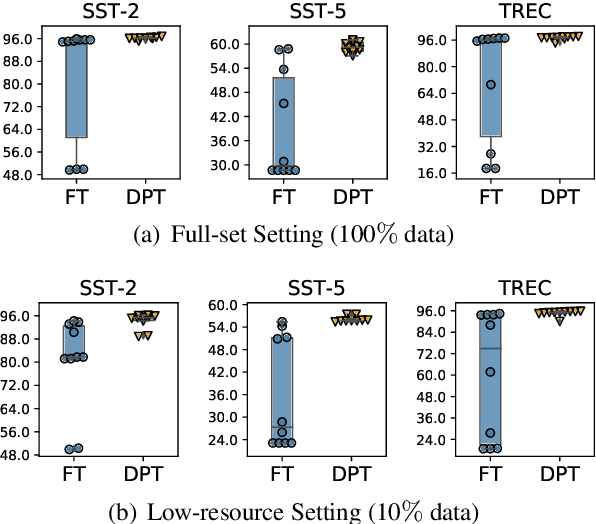
Recent works have shown promising results of prompt tuning in stimulating pre-trained language models (PLMs) for natural language processing (NLP) tasks. However, to the best of our knowledge, existing works focus on prompt-tuning generative PLMs that are pre-trained to generate target tokens, such as BERT. It is still unknown whether and how discriminative PLMs, e.g., ELECTRA, can be effectively prompt-tuned. In this work, we present DPT, the first prompt tuning framework for discriminative PLMs, which reformulates NLP tasks into a discriminative language modeling problem. Comprehensive experiments on text classification and question answering show that, compared with vanilla fine-tuning, DPT achieves significantly higher performance, and also prevents the unstable problem in tuning large PLMs in both full-set and low-resource settings. The source code and experiment details of this paper can be obtained from https://github.com/thunlp/DPT.
Personalized Prompts for Sequential Recommendation
May 19, 2022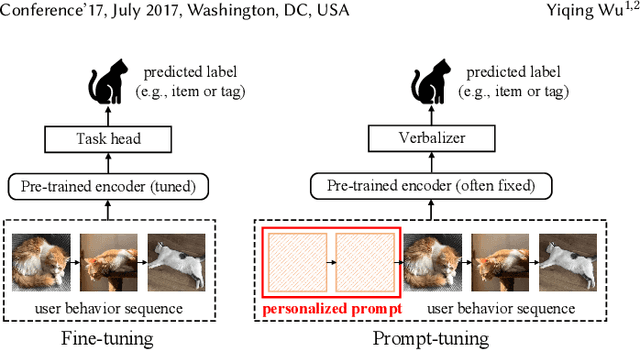
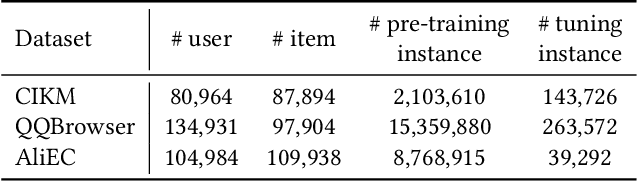
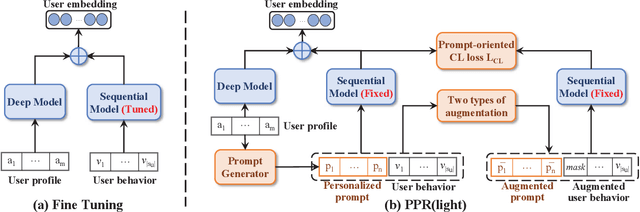
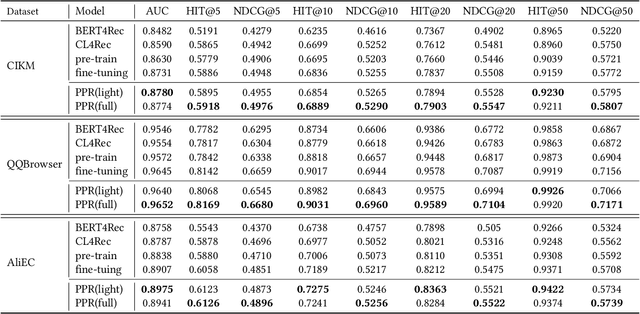
Pre-training models have shown their power in sequential recommendation. Recently, prompt has been widely explored and verified for tuning in NLP pre-training, which could help to more effectively and efficiently extract useful knowledge from pre-training models for downstream tasks, especially in cold-start scenarios. However, it is challenging to bring prompt-tuning from NLP to recommendation, since the tokens in recommendation (i.e., items) do not have explicit explainable semantics, and the sequence modeling should be personalized. In this work, we first introduces prompt to recommendation and propose a novel Personalized prompt-based recommendation (PPR) framework for cold-start recommendation. Specifically, we build the personalized soft prefix prompt via a prompt generator based on user profiles and enable a sufficient training of prompts via a prompt-oriented contrastive learning with both prompt- and behavior-based augmentations. We conduct extensive evaluations on various tasks. In both few-shot and zero-shot recommendation, PPR models achieve significant improvements over baselines on various metrics in three large-scale open datasets. We also conduct ablation tests and sparsity analysis for a better understanding of PPR. Moreover, We further verify PPR's universality on different pre-training models, and conduct explorations on PPR's other promising downstream tasks including cross-domain recommendation and user profile prediction.
Selective Fairness in Recommendation via Prompts
May 10, 2022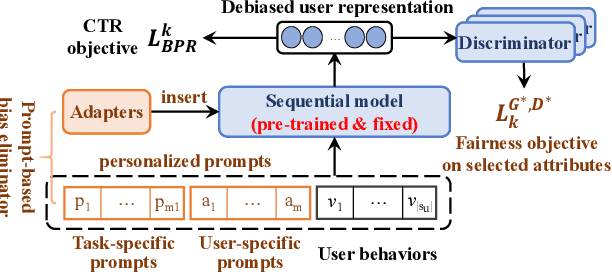

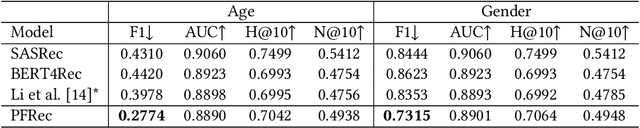
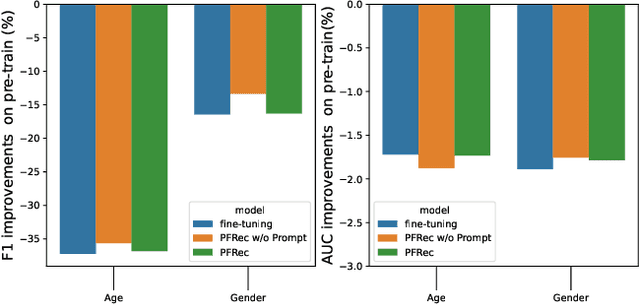
Recommendation fairness has attracted great attention recently. In real-world systems, users usually have multiple sensitive attributes (e.g. age, gender, and occupation), and users may not want their recommendation results influenced by those attributes. Moreover, which of and when these user attributes should be considered in fairness-aware modeling should depend on users' specific demands. In this work, we define the selective fairness task, where users can flexibly choose which sensitive attributes should the recommendation model be bias-free. We propose a novel parameter-efficient prompt-based fairness-aware recommendation (PFRec) framework, which relies on attribute-specific prompt-based bias eliminators with adversarial training, enabling selective fairness with different attribute combinations on sequential recommendation. Both task-specific and user-specific prompts are considered. We conduct extensive evaluations to verify PFRec's superiority in selective fairness. The source codes are released in \url{https://github.com/wyqing20/PFRec}.
Multi-view Multi-behavior Contrastive Learning in Recommendation
Mar 20, 2022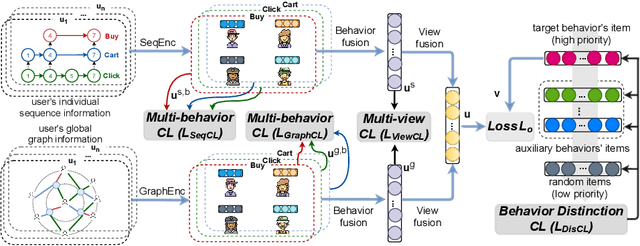
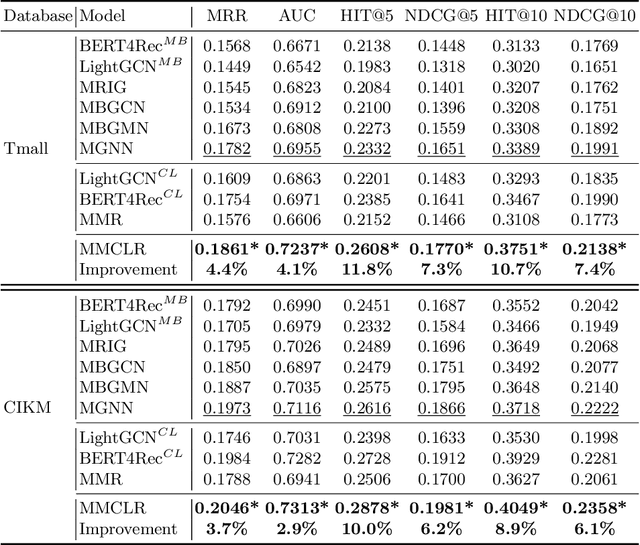
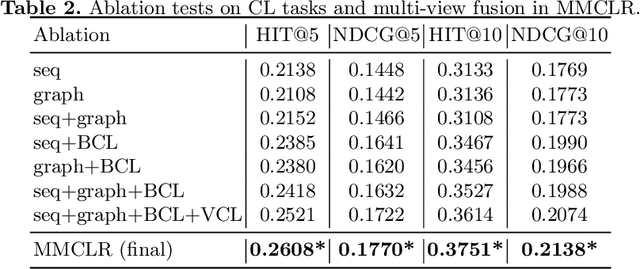
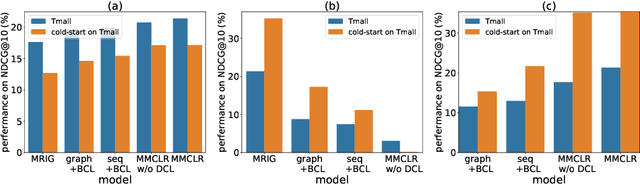
Multi-behavior recommendation (MBR) aims to jointly consider multiple behaviors to improve the target behavior's performance. We argue that MBR models should: (1) model the coarse-grained commonalities between different behaviors of a user, (2) consider both individual sequence view and global graph view in multi-behavior modeling, and (3) capture the fine-grained differences between multiple behaviors of a user. In this work, we propose a novel Multi-behavior Multi-view Contrastive Learning Recommendation (MMCLR) framework, including three new CL tasks to solve the above challenges, respectively. The multi-behavior CL aims to make different user single-behavior representations of the same user in each view to be similar. The multi-view CL attempts to bridge the gap between a user's sequence-view and graph-view representations. The behavior distinction CL focuses on modeling fine-grained differences of different behaviors. In experiments, we conduct extensive evaluations and ablation tests to verify the effectiveness of MMCLR and various CL tasks on two real-world datasets, achieving SOTA performance over existing baselines. Our code will be available on \url{https://github.com/wyqing20/MMCLR}
C$^2$-Rec: An Effective Consistency Constraint for Sequential Recommendation
Dec 13, 2021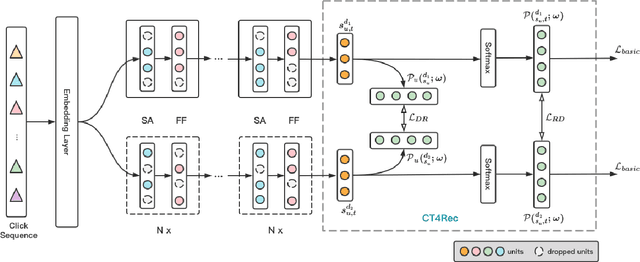
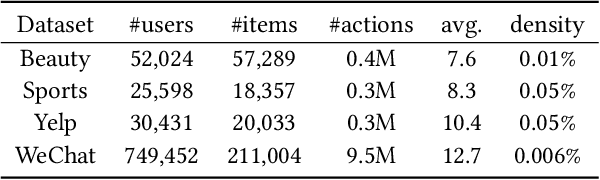
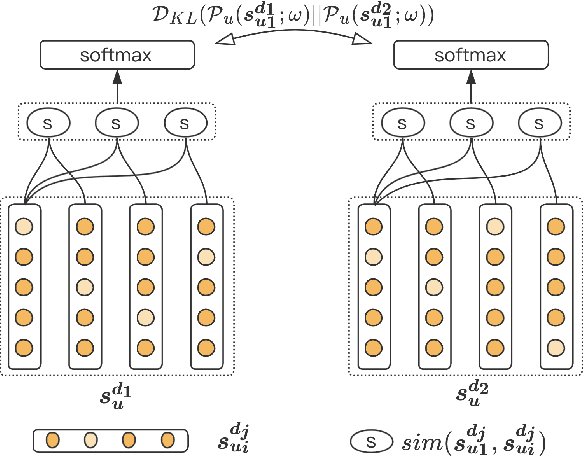

Sequential recommendation methods play an important role in real-world recommender systems. These systems are able to catch user preferences by taking advantage of historical records and then performing recommendations. Contrastive learning(CL) is a cutting-edge technology that can assist us in obtaining informative user representations, but these CL-based models need subtle negative sampling strategies, tedious data augmentation methods, and heavy hyper-parameters tuning work. In this paper, we introduce another way to generate better user representations and recommend more attractive items to users. Particularly, we put forward an effective \textbf{C}onsistency \textbf{C}onstraint for sequential \textbf{Rec}ommendation(C$^2$-Rec) in which only two extra training objectives are used without any structural modifications and data augmentation strategies. Substantial experiments have been conducted on three benchmark datasets and one real industrial dataset, which proves that our proposed method outperforms SOTA models substantially. Furthermore, our method needs much less training time than those CL-based models. Online AB-test on real-world recommendation systems also achieves 10.141\% improvement on the click-through rate and 10.541\% increase on the average click number per capita. The code is available at \url{https://github.com/zhengrongqin/C2-Rec}.