 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentJet: A Flexible Swarm Training Framework for Agentic Reinforcement Learning
Jun 03, 2026We present AgentJet, a distributed swarm training framework for large language model (LLM) agent reinforcement learning. Unlike centralized frameworks that tightly couple agent rollouts with model optimization, AgentJet adopts a decoupled multi-node architecture in which swarm server nodes host trainable models and run optimization on GPU clusters, whereas swarm client nodes execute arbitrary agents on arbitrary devices. This design provides capabilities that are difficult to support in centralized frameworks: (1) heterogeneous multi-model reinforcement learning, enabling the training of heterogeneous multi-agent teams with multiple LLM as brains; (2) multi-task cocktail training with isolated agent runtimes; (3) fault-tolerant execution that prevents external environment failures from interrupting the training process; and (4) live code iteration, which allows agents to be edited during training by replacing swarm client nodes. To support efficient RL in multi-model, multi-turn, and multi-agent settings, AgentJet introduces a context tracking module with timeline merging, which consolidates redundant context and achieves a 1.5-10x training speedup. Finally, AgentJet introduces an automated research system that takes a research topic as input and autonomously conducts long-horizon, multi-day RL studies on large-scale clusters. By leveraging the swarm architecture, this system reproduces key exploratory workflows of RL researchers without human intervention during execution.
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Dec 10, 2025Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.
AgentEvolver: Towards Efficient Self-Evolving Agent System
Nov 13, 2025Autonomous agents powered by large language models (LLMs) have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025
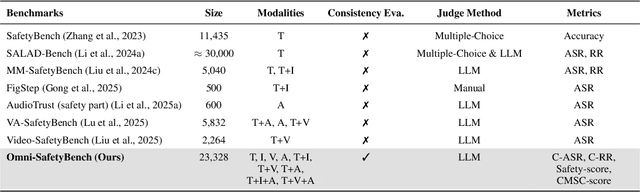

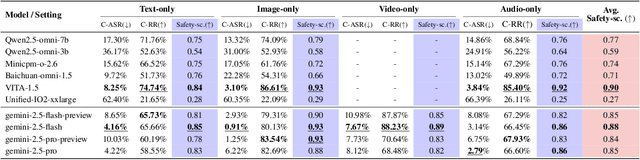
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
Incentivizing Strong Reasoning from Weak Supervision
May 28, 2025



Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/w2sr.
Inference-time Alignment in Continuous Space
May 26, 2025Aligning large language models with human feedback at inference time has received increasing attention due to its flexibility. Existing methods rely on generating multiple responses from the base policy for search using a reward model, which can be considered as searching in a discrete response space. However, these methods struggle to explore informative candidates when the base policy is weak or the candidate set is small, resulting in limited effectiveness. In this paper, to address this problem, we propose Simple Energy Adaptation ($\textbf{SEA}$), a simple yet effective algorithm for inference-time alignment. In contrast to expensive search over the discrete space, SEA directly adapts original responses from the base policy toward the optimal one via gradient-based sampling in continuous latent space. Specifically, SEA formulates inference as an iterative optimization procedure on an energy function over actions in the continuous space defined by the optimal policy, enabling simple and effective alignment. For instance, despite its simplicity, SEA outperforms the second-best baseline with a relative improvement of up to $ \textbf{77.51%}$ on AdvBench and $\textbf{16.36%}$ on MATH. Our code is publicly available at https://github.com/yuanyige/SEA
Incentivizing Reasoning from Weak Supervision
May 26, 2025Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/W2SR.
Revisiting Robust RAG: Do We Still Need Complex Robust Training in the Era of Powerful LLMs?
Feb 17, 2025Retrieval-augmented generation (RAG) systems often suffer from performance degradation when encountering noisy or irrelevant documents, driving researchers to develop sophisticated training strategies to enhance their robustness against such retrieval noise. However, as large language models (LLMs) continue to advance, the necessity of these complex training methods is increasingly questioned. In this paper, we systematically investigate whether complex robust training strategies remain necessary as model capacity grows. Through comprehensive experiments spanning multiple model architectures and parameter scales, we evaluate various document selection methods and adversarial training techniques across diverse datasets. Our extensive experiments consistently demonstrate that as models become more powerful, the performance gains brought by complex robust training methods drop off dramatically. We delve into the rationale and find that more powerful models inherently exhibit superior confidence calibration, better generalization across datasets (even when trained with randomly selected documents), and optimal attention mechanisms learned with simpler strategies. Our findings suggest that RAG systems can benefit from simpler architectures and training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
Feb 17, 2025



Tool learning has emerged as a crucial capability for large language models (LLMs) to solve complex real-world tasks through interaction with external tools. Existing approaches face significant challenges, including reliance on hand-crafted prompts, difficulty in multi-step planning, and lack of precise error diagnosis and reflection mechanisms. We propose ToolCoder, a novel framework that reformulates tool learning as a code generation task. Inspired by software engineering principles, ToolCoder transforms natural language queries into structured Python function scaffold and systematically breaks down tasks with descriptive comments, enabling LLMs to leverage coding paradigms for complex reasoning and planning. It then generates and executes function implementations to obtain final responses. Additionally, ToolCoder stores successfully executed functions in a repository to promote code reuse, while leveraging error traceback mechanisms for systematic debugging, optimizing both execution efficiency and robustness. Experiments demonstrate that ToolCoder achieves superior performance in task completion accuracy and execution reliability compared to existing approaches, establishing the effectiveness of code-centric approaches in tool learning.
Accelerating the Surrogate Retraining for Poisoning Attacks against Recommender Systems
Aug 20, 2024



Recent studies have demonstrated the vulnerability of recommender systems to data poisoning attacks, where adversaries inject carefully crafted fake user interactions into the training data of recommenders to promote target items. Current attack methods involve iteratively retraining a surrogate recommender on the poisoned data with the latest fake users to optimize the attack. However, this repetitive retraining is highly time-consuming, hindering the efficient assessment and optimization of fake users. To mitigate this computational bottleneck and develop a more effective attack in an affordable time, we analyze the retraining process and find that a change in the representation of one user/item will cause a cascading effect through the user-item interaction graph. Under theoretical guidance, we introduce \emph{Gradient Passing} (GP), a novel technique that explicitly passes gradients between interacted user-item pairs during backpropagation, thereby approximating the cascading effect and accelerating retraining. With just a single update, GP can achieve effects comparable to multiple original training iterations. Under the same number of retraining epochs, GP enables a closer approximation of the surrogate recommender to the victim. This more accurate approximation provides better guidance for optimizing fake users, ultimately leading to enhanced data poisoning attacks. Extensive experiments on real-world datasets demonstrate the efficiency and effectiveness of our proposed GP.