 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LMM for Precisely Grounding Elements in Documents
Jun 23, 2026Visual grounding in documents is a crucial ability for Large Multimodal Models (LMMs) in areas such as document understanding, deep research and document error detection. However, existing approaches exhibit poor grounding precision in text-rich document images, often failing to accurately locate the critical document elements needed for reliable reasoning. To address this gap, we introduce PreciseDoc, an LMM specifically designed for precise element grounding and can be further optimized for Document VQA tasks. Specifically, to enhance the basic localization capability, we construct challenging training data by two pipelines capable of mass-producing high-quality documents with paired metadata of fine-grained coordinates, including synthetic hand-filled documents with camera effects. The model develops more real-world functions beyond straightforward localization of single text, such as locating personal information from CVs. Furthermore, we introduce a training paradigm for visual grounded reasoning where the grounding and reasoning are supervised jointly with reinforcement learning to improve the contribution of the grounded evidence. A comprehensive evaluation on various benchmarks demonstrates the advantage of the proposed data and methods in document spatial grounding and document understanding.
Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?
Feb 17, 2025The radioactive nature of Large Language Model (LLM) watermarking enables the detection of watermarks inherited by student models when trained on the outputs of watermarked teacher models, making it a promising tool for preventing unauthorized knowledge distillation. However, the robustness of watermark radioactivity against adversarial actors remains largely unexplored. In this paper, we investigate whether student models can acquire the capabilities of teacher models through knowledge distillation while avoiding watermark inheritance. We propose two categories of watermark removal approaches: pre-distillation removal through untargeted and targeted training data paraphrasing (UP and TP), and post-distillation removal through inference-time watermark neutralization (WN). Extensive experiments across multiple model pairs, watermarking schemes and hyper-parameter settings demonstrate that both TP and WN thoroughly eliminate inherited watermarks, with WN achieving this while maintaining knowledge transfer efficiency and low computational overhead. Given the ongoing deployment of watermarking techniques in production LLMs, these findings emphasize the urgent need for more robust defense strategies. Our code is available at https://github.com/THU-BPM/Watermark-Radioactivity-Attack.
WaterSeeker: Efficient Detection of Watermarked Segments in Large Documents
Sep 08, 2024



Watermarking algorithms for large language models (LLMs) have attained high accuracy in detecting LLM-generated text. However, existing methods primarily focus on distinguishing fully watermarked text from non-watermarked text, overlooking real-world scenarios where LLMs generate only small sections within large documents. In this scenario, balancing time complexity and detection performance poses significant challenges. This paper presents WaterSeeker, a novel approach to efficiently detect and locate watermarked segments amid extensive natural text. It first applies an efficient anomaly extraction method to preliminarily locate suspicious watermarked regions. Following this, it conducts a local traversal and performs full-text detection for more precise verification. Theoretical analysis and experimental results demonstrate that WaterSeeker achieves a superior balance between detection accuracy and computational efficiency. Moreover, WaterSeeker's localization ability supports the development of interpretable AI detection systems. This work pioneers a new direction in watermarked segment detection, facilitating more reliable AI-generated content identification.
MarkLLM: An Open-Source Toolkit for LLM Watermarking
May 16, 2024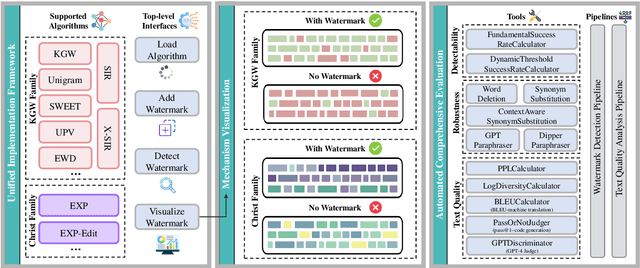
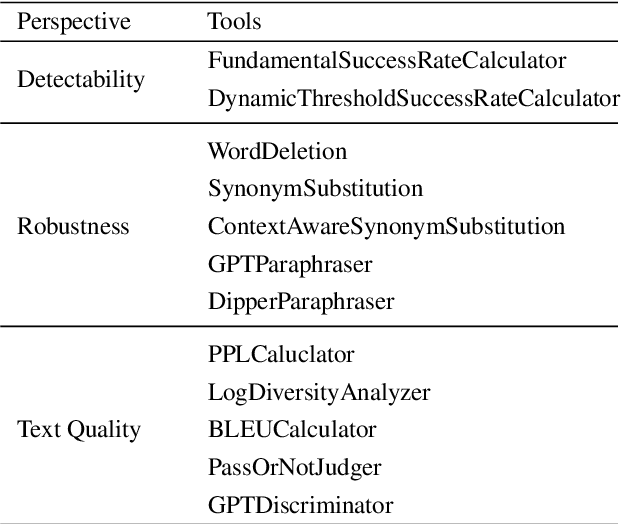
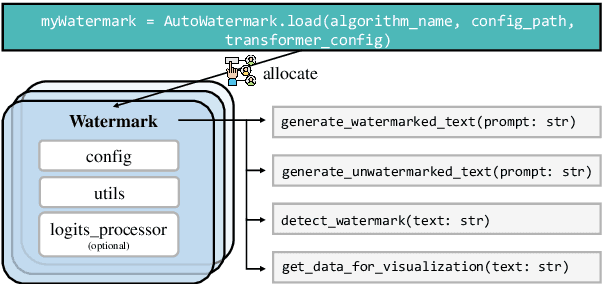
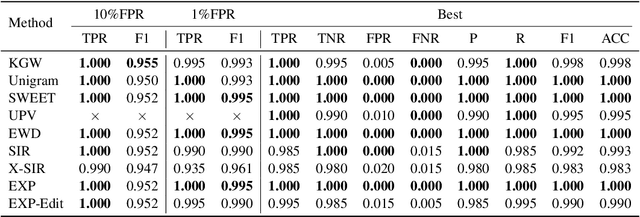
LLM watermarking, which embeds imperceptible yet algorithmically detectable signals in model outputs to identify LLM-generated text, has become crucial in mitigating the potential misuse of large language models. However, the abundance of LLM watermarking algorithms, their intricate mechanisms, and the complex evaluation procedures and perspectives pose challenges for researchers and the community to easily experiment with, understand, and assess the latest advancements. To address these issues, we introduce MarkLLM, an open-source toolkit for LLM watermarking. MarkLLM offers a unified and extensible framework for implementing LLM watermarking algorithms, while providing user-friendly interfaces to ensure ease of access. Furthermore, it enhances understanding by supporting automatic visualization of the underlying mechanisms of these algorithms. For evaluation, MarkLLM offers a comprehensive suite of 12 tools spanning three perspectives, along with two types of automated evaluation pipelines. Through MarkLLM, we aim to support researchers while improving the comprehension and involvement of the general public in LLM watermarking technology, fostering consensus and driving further advancements in research and application. Our code is available at https://github.com/THU-BPM/MarkLLM.
An Entropy-based Text Watermarking Detection Method
Mar 20, 2024Currently, text watermarking algorithms for large language models (LLMs) can embed hidden features to texts generated by LLMs to facilitate subsequent detection, thus alleviating the problem of misuse of LLMs. Although the current text watermarking algorithms perform well in most high-entropy scenarios, its performance in low-entropy scenarios still needs to be improved. In this work, we proposed that the influence of token entropy should be fully considered in the watermark detection process, that is, the weight of each token should be adjusted according to its entropy during watermark detection, rather than setting the weight of all tokens to the same value as in previous methods. Specifically, we proposed an Entropy-based Watermark Detection (EWD) that gives higher-entropy tokens higher weights during watermark detection, so as to better reflect the degree of watermarking. Furthermore, the proposed detection process is training-free and fully automated. %In actual detection, we use a proxy-LLM to calculate the entropy of each token, without the need to use the original LLM. In the experiment, we found that our method can achieve better detection performance in low-entropy scenarios, and our method is also general and can be applied to texts with different entropy distributions. Our code and data will be available online.
A Survey of Text Watermarking in the Era of Large Language Models
Jan 03, 2024



Text watermarking algorithms play a crucial role in the copyright protection of textual content, yet their capabilities and application scenarios have been limited historically. The recent developments in large language models (LLMs) have opened new opportunities for the advancement of text watermarking techniques. LLMs not only enhance the capabilities of text watermarking algorithms through their text understanding and generation abilities but also necessitate the use of text watermarking algorithms for their own copyright protection. This paper conducts a comprehensive survey of the current state of text watermarking technology, covering four main aspects: (1) an overview and comparison of different text watermarking techniques; (2) evaluation methods for text watermarking algorithms, including their success rates, impact on text quality, robustness, and unforgeability; (3) potential application scenarios for text watermarking technology; (4) current challenges and future directions for development. This survey aims to provide researchers with a thorough understanding of text watermarking technology, thereby promoting its further advancement.