 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edged-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Dec 10, 2025Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025
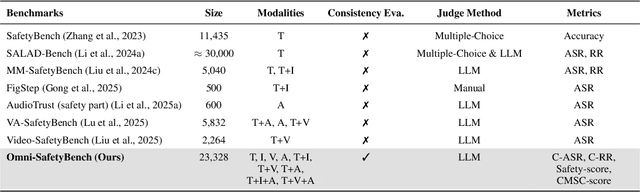

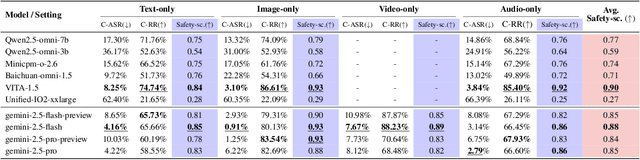
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
Efficiently Serving LLM Reasoning Programs with Certaindex
Dec 30, 2024



The rapid evolution of large language models (LLMs) has unlocked their capabilities in advanced reasoning tasks like mathematical problem-solving, code generation, and legal analysis. Central to this progress are inference-time reasoning algorithms, which refine outputs by exploring multiple solution paths, at the cost of increasing compute demands and response latencies. Existing serving systems fail to adapt to the scaling behaviors of these algorithms or the varying difficulty of queries, leading to inefficient resource use and unmet latency targets. We present Dynasor, a system that optimizes inference-time compute for LLM reasoning queries. Unlike traditional engines, Dynasor tracks and schedules requests within reasoning queries and uses Certaindex, a proxy that measures statistical reasoning progress based on model certainty, to guide compute allocation dynamically. Dynasor co-adapts scheduling with reasoning progress: it allocates more compute to hard queries, reduces compute for simpler ones, and terminates unpromising queries early, balancing accuracy, latency, and cost. On diverse datasets and algorithms, Dynasor reduces compute by up to 50% in batch processing and sustaining 3.3x higher query rates or 4.7x tighter latency SLOs in online serving.
Weakly Supervised Two-Stage Training Scheme for Deep Video Fight Detection Model
Sep 23, 2022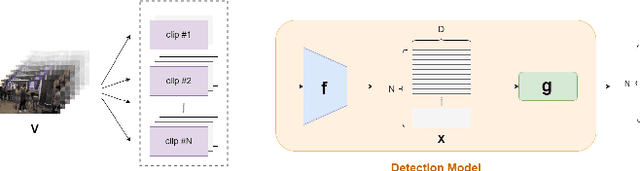
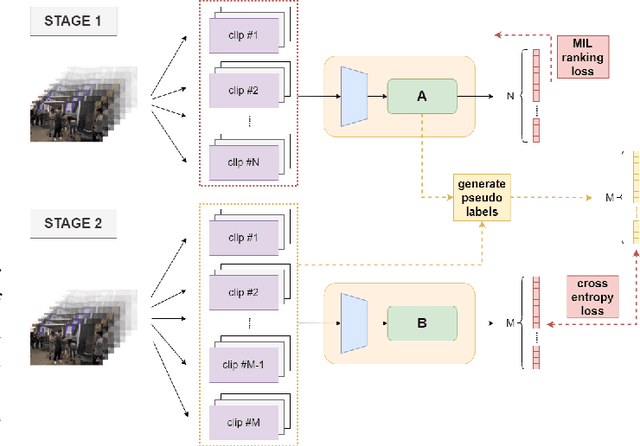

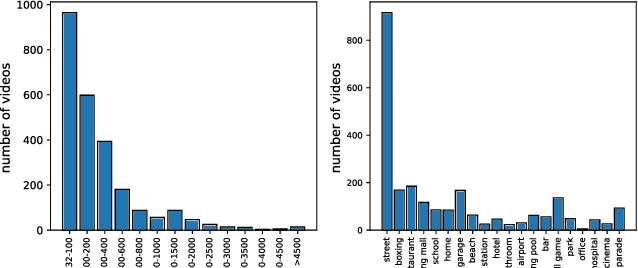
Fight detection in videos is an emerging deep learning application with today's prevalence of surveillance systems and streaming media. Previous work has largely relied on action recognition techniques to tackle this problem. In this paper, we propose a simple but effective method that solves the task from a new perspective: we design the fight detection model as a composition of an action-aware feature extractor and an anomaly score generator. Also, considering that collecting frame-level labels for videos is too laborious, we design a weakly supervised two-stage training scheme, where we utilize multiple-instance-learning loss calculated on video-level labels to train the score generator, and adopt the self-training technique to further improve its performance. Extensive experiments on a publicly available large-scale dataset, UBI-Fights, demonstrate the effectiveness of our method, and the performance on the dataset exceeds several previous state-of-the-art approaches. Furthermore, we collect a new dataset, VFD-2000, that specializes in video fight detection, with a larger scale and more scenarios than existing datasets. The implementation of our method and the proposed dataset will be publicly available at https://github.com/Hepta-Col/VideoFightDetection.