 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Aug 10, 2025



Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge -- their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs' conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
EventRR: Event Referential Reasoning for Referring Video Object Segmentation
Aug 10, 2025Referring Video Object Segmentation (RVOS) aims to segment out the object in a video referred by an expression. Current RVOS methods view referring expressions as unstructured sequences, neglecting their crucial semantic structure essential for referent reasoning. Besides, in contrast to image-referring expressions whose semantics focus only on object attributes and object-object relations, video-referring expressions also encompass event attributes and event-event temporal relations. This complexity challenges traditional structured reasoning image approaches. In this paper, we propose the Event Referential Reasoning (EventRR) framework. EventRR decouples RVOS into object summarization part and referent reasoning part. The summarization phase begins by summarizing each frame into a set of bottleneck tokens, which are then efficiently aggregated in the video-level summarization step to exchange the global cross-modal temporal context. For reasoning part, EventRR extracts semantic eventful structure of a video-referring expression into highly expressive Referential Event Graph (REG), which is a single-rooted directed acyclic graph. Guided by topological traversal of REG, we propose Temporal Concept-Role Reasoning (TCRR) to accumulate the referring score of each temporal query from REG leaf nodes to root node. Each reasoning step can be interpreted as a question-answer pair derived from the concept-role relations in REG. Extensive experiments across four widely recognized benchmark datasets, show that EventRR quantitatively and qualitatively outperforms state-of-the-art RVOS methods. Code is available at https://github.com/bio-mlhui/EventRR
S2-UniSeg: Fast Universal Agglomerative Pooling for Scalable Segment Anything without Supervision
Aug 09, 2025Recent self-supervised image segmentation models have achieved promising performance on semantic segmentation and class-agnostic instance segmentation. However, their pretraining schedule is multi-stage, requiring a time-consuming pseudo-masks generation process between each training epoch. This time-consuming offline process not only makes it difficult to scale with training dataset size, but also leads to sub-optimal solutions due to its discontinuous optimization routine. To solve these, we first present a novel pseudo-mask algorithm, Fast Universal Agglomerative Pooling (UniAP). Each layer of UniAP can identify groups of similar nodes in parallel, allowing to generate both semantic-level and instance-level and multi-granular pseudo-masks within ens of milliseconds for one image. Based on the fast UniAP, we propose the Scalable Self-Supervised Universal Segmentation (S2-UniSeg), which employs a student and a momentum teacher for continuous pretraining. A novel segmentation-oriented pretext task, Query-wise Self-Distillation (QuerySD), is proposed to pretrain S2-UniSeg to learn the local-to-global correspondences. Under the same setting, S2-UniSeg outperforms the SOTA UnSAM model, achieving notable improvements of AP+6.9 on COCO, AR+11.1 on UVO, PixelAcc+4.5 on COCOStuff-27, RQ+8.0 on Cityscapes. After scaling up to a larger 2M-image subset of SA-1B, S2-UniSeg further achieves performance gains on all four benchmarks. Our code and pretrained models are available at https://github.com/bio-mlhui/S2-UniSeg
Unified modality separation: A vision-language framework for unsupervised domain adaptation
Aug 07, 2025



Unsupervised domain adaptation (UDA) enables models trained on a labeled source domain to handle new unlabeled domains. Recently, pre-trained vision-language models (VLMs) have demonstrated promising zero-shot performance by leveraging semantic information to facilitate target tasks. By aligning vision and text embeddings, VLMs have shown notable success in bridging domain gaps. However, inherent differences naturally exist between modalities, which is known as modality gap. Our findings reveal that direct UDA with the presence of modality gap only transfers modality-invariant knowledge, leading to suboptimal target performance. To address this limitation, we propose a unified modality separation framework that accommodates both modality-specific and modality-invariant components. During training, different modality components are disentangled from VLM features then handled separately in a unified manner. At test time, modality-adaptive ensemble weights are automatically determined to maximize the synergy of different components. To evaluate instance-level modality characteristics, we design a modality discrepancy metric to categorize samples into modality-invariant, modality-specific, and uncertain ones. The modality-invariant samples are exploited to facilitate cross-modal alignment, while uncertain ones are annotated to enhance model capabilities. Building upon prompt tuning techniques, our methods achieve up to 9% performance gain with 9 times of computational efficiencies. Extensive experiments and analysis across various backbones, baselines, datasets and adaptation settings demonstrate the efficacy of our design.
HRVVS: A High-resolution Video Vasculature Segmentation Network via Hierarchical Autoregressive Residual Priors
Jul 30, 2025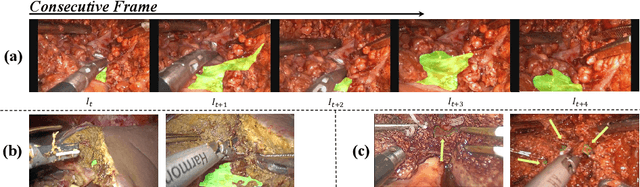
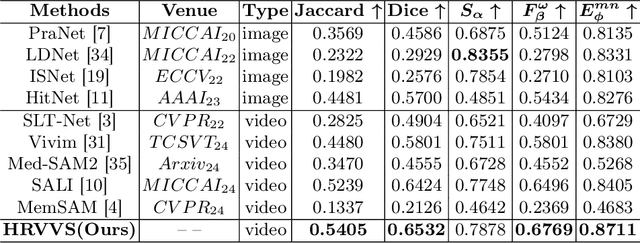
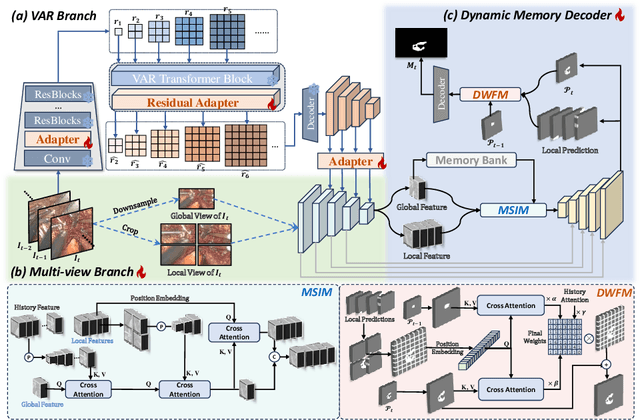
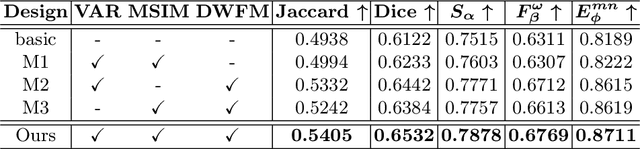
The segmentation of the hepatic vasculature in surgical videos holds substantial clinical significance in the context of hepatectomy procedures. However, owing to the dearth of an appropriate dataset and the inherently complex task characteristics, few researches have been reported in this domain. To address this issue, we first introduce a high quality frame-by-frame annotated hepatic vasculature dataset containing 35 long hepatectomy videos and 11442 high-resolution frames. On this basis, we propose a novel high-resolution video vasculature segmentation network, dubbed as HRVVS. We innovatively embed a pretrained visual autoregressive modeling (VAR) model into different layers of the hierarchical encoder as prior information to reduce the information degradation generated during the downsampling process. In addition, we designed a dynamic memory decoder on a multi-view segmentation network to minimize the transmission of redundant information while preserving more details between frames. Extensive experiments on surgical video datasets demonstrate that our proposed HRVVS significantly outperforms the state-of-the-art methods. The source code and dataset will be publicly available at \href{https://github.com/scott-yjyang/xx}{https://github.com/scott-yjyang/HRVVS}.
MaskedCLIP: Bridging the Masked and CLIP Space for Semi-Supervised Medical Vision-Language Pre-training
Jul 23, 2025Foundation models have recently gained tremendous popularity in medical image analysis. State-of-the-art methods leverage either paired image-text data via vision-language pre-training or unpaired image data via self-supervised pre-training to learn foundation models with generalizable image features to boost downstream task performance. However, learning foundation models exclusively on either paired or unpaired image data limits their ability to learn richer and more comprehensive image features. In this paper, we investigate a novel task termed semi-supervised vision-language pre-training, aiming to fully harness the potential of both paired and unpaired image data for foundation model learning. To this end, we propose MaskedCLIP, a synergistic masked image modeling and contrastive language-image pre-training framework for semi-supervised vision-language pre-training. The key challenge in combining paired and unpaired image data for learning a foundation model lies in the incompatible feature spaces derived from these two types of data. To address this issue, we propose to connect the masked feature space with the CLIP feature space with a bridge transformer. In this way, the more semantic specific CLIP features can benefit from the more general masked features for semantic feature extraction. We further propose a masked knowledge distillation loss to distill semantic knowledge of original image features in CLIP feature space back to the predicted masked image features in masked feature space. With this mutually interactive design, our framework effectively leverages both paired and unpaired image data to learn more generalizable image features for downstream tasks. Extensive experiments on retinal image analysis demonstrate the effectiveness and data efficiency of our method.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025



Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
AdvMIM: Adversarial Masked Image Modeling for Semi-Supervised Medical Image Segmentation
Jun 25, 2025Vision Transformer has recently gained tremendous popularity in medical image segmentation task due to its superior capability in capturing long-range dependencies. However, transformer requires a large amount of labeled data to be effective, which hinders its applicability in annotation scarce semi-supervised learning scenario where only limited labeled data is available. State-of-the-art semi-supervised learning methods propose combinatorial CNN-Transformer learning to cross teach a transformer with a convolutional neural network, which achieves promising results. However, it remains a challenging task to effectively train the transformer with limited labeled data. In this paper, we propose an adversarial masked image modeling method to fully unleash the potential of transformer for semi-supervised medical image segmentation. The key challenge in semi-supervised learning with transformer lies in the lack of sufficient supervision signal. To this end, we propose to construct an auxiliary masked domain from original domain with masked image modeling and train the transformer to predict the entire segmentation mask with masked inputs to increase supervision signal. We leverage the original labels from labeled data and pseudo-labels from unlabeled data to learn the masked domain. To further benefit the original domain from masked domain, we provide a theoretical analysis of our method from a multi-domain learning perspective and devise a novel adversarial training loss to reduce the domain gap between the original and masked domain, which boosts semi-supervised learning performance. We also extend adversarial masked image modeling to CNN network. Extensive experiments on three public medical image segmentation datasets demonstrate the effectiveness of our method, where our method outperforms existing methods significantly. Our code is publicly available at https://github.com/zlheui/AdvMIM.
Surgery-R1: Advancing Surgical-VQLA with Reasoning Multimodal Large Language Model via Reinforcement Learning
Jun 24, 2025In recent years, significant progress has been made in the field of surgical scene understanding, particularly in the task of Visual Question Localized-Answering in robotic surgery (Surgical-VQLA). However, existing Surgical-VQLA models lack deep reasoning capabilities and interpretability in surgical scenes, which limits their reliability and potential for development in clinical applications. To address this issue, inspired by the development of Reasoning Multimodal Large Language Models (MLLMs), we first build the Surgery-R1-54k dataset, including paired data for Visual-QA, Grounding-QA, and Chain-of-Thought (CoT). Then, we propose the first Reasoning MLLM for Surgical-VQLA (Surgery-R1). In our Surgery-R1, we design a two-stage fine-tuning mechanism to enable the basic MLLM with complex reasoning abilities by utilizing supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). Furthermore, for an efficient and high-quality rule-based reward system in our RFT, we design a Multimodal Coherence reward mechanism to mitigate positional illusions that may arise in surgical scenarios. Experiment results demonstrate that Surgery-R1 outperforms other existing state-of-the-art (SOTA) models in the Surgical-VQLA task and widely-used MLLMs, while also validating its reasoning capabilities and the effectiveness of our approach. The code and dataset will be organized in https://github.com/FiFi-HAO467/Surgery-R1.
PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Jun 12, 2025



Generating aesthetic posters is more challenging than simple design images: it requires not only precise text rendering but also the seamless integration of abstract artistic content, striking layouts, and overall stylistic harmony. To address this, we propose PosterCraft, a unified framework that abandons prior modular pipelines and rigid, predefined layouts, allowing the model to freely explore coherent, visually compelling compositions. PosterCraft employs a carefully designed, cascaded workflow to optimize the generation of high-aesthetic posters: (i) large-scale text-rendering optimization on our newly introduced Text-Render-2M dataset; (ii) region-aware supervised fine-tuning on HQ-Poster100K; (iii) aesthetic-text-reinforcement learning via best-of-n preference optimization; and (iv) joint vision-language feedback refinement. Each stage is supported by a fully automated data-construction pipeline tailored to its specific needs, enabling robust training without complex architectural modifications. Evaluated on multiple experiments, PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal-approaching the quality of SOTA commercial systems. Our code, models, and datasets can be found in the Project page: https://ephemeral182.github.io/PosterCraft