 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does Transformer Learn Implicit Reasoning?
May 29, 2025



Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly -- producing correct answers without explicitly verbalizing intermediate steps -- but the underlying mechanisms remain poorly understood. In this paper, we study how such implicit reasoning emerges by training transformers from scratch in a controlled symbolic environment. Our analysis reveals a three-stage developmental trajectory: early memorization, followed by in-distribution generalization, and eventually cross-distribution generalization. We find that training with atomic triples is not necessary but accelerates learning, and that second-hop generalization relies on query-level exposure to specific compositional structures. To interpret these behaviors, we introduce two diagnostic tools: cross-query semantic patching, which identifies semantically reusable intermediate representations, and a cosine-based representational lens, which reveals that successful reasoning correlates with the cosine-base clustering in hidden space. This clustering phenomenon in turn provides a coherent explanation for the behavioral dynamics observed across training, linking representational structure to reasoning capability. These findings provide new insights into the interpretability of implicit multi-hop reasoning in LLMs, helping to clarify how complex reasoning processes unfold internally and offering pathways to enhance the transparency of such models.
Hard Negative Contrastive Learning for Fine-Grained Geometric Understanding in Large Multimodal Models
May 26, 2025Benefiting from contrastively trained visual encoders on large-scale natural scene images, Large Multimodal Models (LMMs) have achieved remarkable performance across various visual perception tasks. However, the inherent limitations of contrastive learning upon summarized descriptions fundamentally restrict the capabilities of models in meticulous reasoning, particularly in crucial scenarios of geometric problem-solving. To enhance geometric understanding, we propose a novel hard negative contrastive learning framework for the vision encoder, which combines image-based contrastive learning using generation-based hard negatives created by perturbing diagram generation code, and text-based contrastive learning using rule-based negatives derived from modified geometric descriptions and retrieval-based negatives selected based on caption similarity. We train CLIP using our strong negative learning method, namely MMCLIP (Multimodal Math CLIP), and subsequently train an LMM for geometric problem-solving. Experiments show that our trained model, MMGeoLM, significantly outperforms other open-source models on three geometric reasoning benchmarks. Even with a size of 7B, it can rival powerful closed-source models like GPT-4o. We further study the impact of different negative sample construction methods and the number of negative samples on the geometric reasoning performance of LMM, yielding fruitful conclusions. The code and dataset are available at https://github.com/THU-KEG/MMGeoLM.
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
May 22, 2025Large Language Models (LLMs) have demonstrated advanced capabilities in real-world agentic applications. Growing research efforts aim to develop LLM-based agents to address practical demands, introducing a new challenge: agentic scenarios often involve lengthy instructions with complex constraints, such as extended system prompts and detailed tool specifications. While adherence to such instructions is crucial for agentic applications, whether LLMs can reliably follow them remains underexplored. In this paper, we introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. To construct AgentIF, we collect 707 human-annotated instructions across 50 agentic tasks from industrial application agents and open-source agentic systems. For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation. We use AgentIF to systematically evaluate existing advanced LLMs. We observe that current models generally perform poorly, especially in handling complex constraint structures and tool specifications. We further conduct error analysis and analytical experiments on instruction length and meta constraints, providing some findings about the failure modes of existing LLMs. We have released the code and data to facilitate future research.
AdaptThink: Reasoning Models Can Learn When to Think
May 19, 2025Recently, large reasoning models have achieved impressive performance on various tasks by employing human-like deep thinking. However, the lengthy thinking process substantially increases inference overhead, making efficiency a critical bottleneck. In this work, we first demonstrate that NoThinking, which prompts the reasoning model to skip thinking and directly generate the final solution, is a better choice for relatively simple tasks in terms of both performance and efficiency. Motivated by this, we propose AdaptThink, a novel RL algorithm to teach reasoning models to choose the optimal thinking mode adaptively based on problem difficulty. Specifically, AdaptThink features two core components: (1) a constrained optimization objective that encourages the model to choose NoThinking while maintaining the overall performance; (2) an importance sampling strategy that balances Thinking and NoThinking samples during on-policy training, thereby enabling cold start and allowing the model to explore and exploit both thinking modes throughout the training process. Our experiments indicate that AdaptThink significantly reduces the inference costs while further enhancing performance. Notably, on three math datasets, AdaptThink reduces the average response length of DeepSeek-R1-Distill-Qwen-1.5B by 53% and improves its accuracy by 2.4%, highlighting the promise of adaptive thinking-mode selection for optimizing the balance between reasoning quality and efficiency. Our codes and models are available at https://github.com/THU-KEG/AdaptThink.
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
May 04, 2025Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025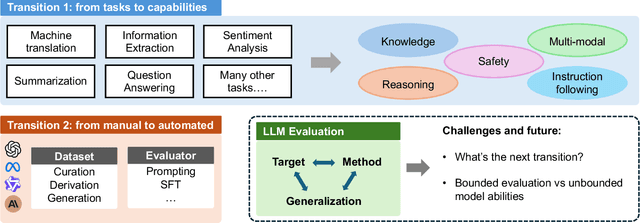
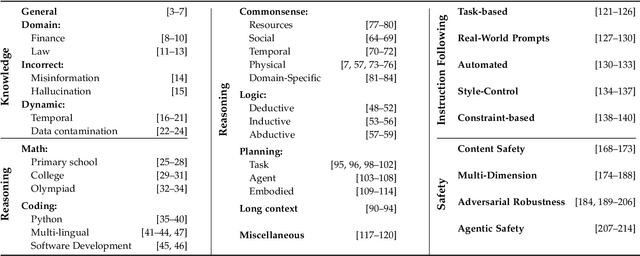
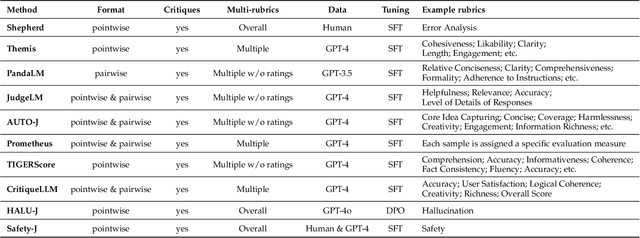
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation
Mar 27, 2025



Large Reasoning Models (LRMs) exhibit remarkable reasoning abilities but rely primarily on parametric knowledge, limiting factual accuracy. While recent works equip reinforcement learning (RL)-based LRMs with retrieval capabilities, they suffer from overthinking and lack robustness in reasoning, reducing their effectiveness in question answering (QA) tasks. To address this, we propose ReaRAG, a factuality-enhanced reasoning model that explores diverse queries without excessive iterations. Our solution includes a novel data construction framework with an upper bound on the reasoning chain length. Specifically, we first leverage an LRM to generate deliberate thinking, then select an action from a predefined action space (Search and Finish). For Search action, a query is executed against the RAG engine, where the result is returned as observation to guide reasoning steps later. This process iterates until a Finish action is chosen. Benefiting from ReaRAG's strong reasoning capabilities, our approach outperforms existing baselines on multi-hop QA. Further analysis highlights its strong reflective ability to recognize errors and refine its reasoning trajectory. Our study enhances LRMs' factuality while effectively integrating robust reasoning for Retrieval-Augmented Generation (RAG).
Invertible Koopman neural operator for data-driven modeling of partial differential equations
Mar 25, 2025



Koopman operator theory is a popular candidate for data-driven modeling because it provides a global linearization representation for nonlinear dynamical systems. However, existing Koopman operator-based methods suffer from shortcomings in constructing the well-behaved observable function and its inverse and are inefficient enough when dealing with partial differential equations (PDEs). To address these issues, this paper proposes the Invertible Koopman Neural Operator (IKNO), a novel data-driven modeling approach inspired by the Koopman operator theory and neural operator. IKNO leverages an Invertible Neural Network to parameterize observable function and its inverse simultaneously under the same learnable parameters, explicitly guaranteeing the reconstruction relation, thus eliminating the dependency on the reconstruction loss, which is an essential improvement over the original Koopman Neural Operator (KNO). The structured linear matrix inspired by the Koopman operator theory is parameterized to learn the evolution of observables' low-frequency modes in the frequency space rather than directly in the observable space, sustaining IKNO is resolution-invariant like other neural operators. Moreover, with preprocessing such as interpolation and dimension expansion, IKNO can be extended to operator learning tasks defined on non-Cartesian domains. We fully support the above claims based on rich numerical and real-world examples and demonstrate the effectiveness of IKNO and superiority over other neural operators.
MRCEval: A Comprehensive, Challenging and Accessible Machine Reading Comprehension Benchmark
Mar 10, 2025Machine Reading Comprehension (MRC) is an essential task in evaluating natural language understanding. Existing MRC datasets primarily assess specific aspects of reading comprehension (RC), lacking a comprehensive MRC benchmark. To fill this gap, we first introduce a novel taxonomy that categorizes the key capabilities required for RC. Based on this taxonomy, we construct MRCEval, an MRC benchmark that leverages advanced Large Language Models (LLMs) as both sample generators and selection judges. MRCEval is a comprehensive, challenging and accessible benchmark designed to assess the RC capabilities of LLMs thoroughly, covering 13 distinct RC skills with a total of 2.1K high-quality multi-choice questions. We perform an extensive evaluation of 28 widely used open-source and proprietary models, highlighting that MRC continues to present significant challenges even in the era of LLMs.
Sparse Auto-Encoder Interprets Linguistic Features in Large Language Models
Feb 27, 2025Large language models (LLMs) excel in tasks that require complex linguistic abilities, such as reference disambiguation and metaphor recognition/generation. Although LLMs possess impressive capabilities, their internal mechanisms for processing and representing linguistic knowledge remain largely opaque. Previous work on linguistic mechanisms has been limited by coarse granularity, insufficient causal analysis, and a narrow focus. In this study, we present a systematic and comprehensive causal investigation using sparse auto-encoders (SAEs). We extract a wide range of linguistic features from six dimensions: phonetics, phonology, morphology, syntax, semantics, and pragmatics. We extract, evaluate, and intervene on these features by constructing minimal contrast datasets and counterfactual sentence datasets. We introduce two indices-Feature Representation Confidence (FRC) and Feature Intervention Confidence (FIC)-to measure the ability of linguistic features to capture and control linguistic phenomena. Our results reveal inherent representations of linguistic knowledge in LLMs and demonstrate the potential for controlling model outputs. This work provides strong evidence that LLMs possess genuine linguistic knowledge and lays the foundation for more interpretable and controllable language modeling in future research.