 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Model-Based Approach on Learning Agile Motor Skills without Reinforcement
Mar 04, 2024



Learning-based methods have improved locomotion skills of quadruped robots through deep reinforcement learning. However, the sim-to-real gap and low sample efficiency still limit the skill transfer. To address this issue, we propose an efficient model-based learning framework that combines a world model with a policy network. We train a differentiable world model to predict future states and use it to directly supervise a Variational Autoencoder (VAE)-based policy network to imitate real animal behaviors. This significantly reduces the need for real interaction data and allows for rapid policy updates. We also develop a high-level network to track diverse commands and trajectories. Our simulated results show a tenfold sample efficiency increase compared to reinforcement learning methods such as PPO. In real-world testing, our policy achieves proficient command-following performance with only a two-minute data collection period and generalizes well to new speeds and paths.
Learning Highly Dynamic Behaviors for Quadrupedal Robots
Feb 21, 2024Learning highly dynamic behaviors for robots has been a longstanding challenge. Traditional approaches have demonstrated robust locomotion, but the exhibited behaviors lack diversity and agility. They employ approximate models, which lead to compromises in performance. Data-driven approaches have been shown to reproduce agile behaviors of animals, but typically have not been able to learn highly dynamic behaviors. In this paper, we propose a learning-based approach to enable robots to learn highly dynamic behaviors from animal motion data. The learned controller is deployed on a quadrupedal robot and the results show that the controller is able to reproduce highly dynamic behaviors including sprinting, jumping and sharp turning. Various behaviors can be activated through human interaction using a stick with markers attached to it. Based on the motion pattern of the stick, the robot exhibits walking, running, sitting and jumping, much like the way humans interact with a pet.
HyperAgent: A Simple, Scalable, Efficient and Provable Reinforcement Learning Framework for Complex Environments
Feb 05, 2024To solve complex tasks under resource constraints, reinforcement learning (RL) agents need to be simple, efficient, and scalable with (1) large state space and (2) increasingly accumulated data of interactions. We propose the HyperAgent, a RL framework with hypermodel, index sampling schemes and incremental update mechanism, enabling computation-efficient sequential posterior approximation and data-efficient action selection under general value function approximation beyond conjugacy. The implementation of \HyperAgent is simple as it only adds one module and one line of code additional to DDQN. Practically, HyperAgent demonstrates its robust performance in large-scale deep RL benchmarks with significant efficiency gain in terms of both data and computation. Theoretically, among the practically scalable algorithms, HyperAgent is the first method to achieve provably scalable per-step computational complexity as well as sublinear regret under tabular RL. The core of our theoretical analysis is the sequential posterior approximation argument, made possible by the first analytical tool for sequential random projection, a non-trivial martingale extension of the Johnson-Lindenstrauss lemma. This work bridges the theoretical and practical realms of RL, establishing a new benchmark for RL algorithm design.
Identification of Regulatory Requirements Relevant to Business Processes: A Comparative Study on Generative AI, Embedding-based Ranking, Crowd and Expert-driven Methods
Jan 02, 2024



Organizations face the challenge of ensuring compliance with an increasing amount of requirements from various regulatory documents. Which requirements are relevant depends on aspects such as the geographic location of the organization, its domain, size, and business processes. Considering these contextual factors, as a first step, relevant documents (e.g., laws, regulations, directives, policies) are identified, followed by a more detailed analysis of which parts of the identified documents are relevant for which step of a given business process. Nowadays the identification of regulatory requirements relevant to business processes is mostly done manually by domain and legal experts, posing a tremendous effort on them, especially for a large number of regulatory documents which might frequently change. Hence, this work examines how legal and domain experts can be assisted in the assessment of relevant requirements. For this, we compare an embedding-based NLP ranking method, a generative AI method using GPT-4, and a crowdsourced method with the purely manual method of creating relevancy labels by experts. The proposed methods are evaluated based on two case studies: an Australian insurance case created with domain experts and a global banking use case, adapted from SAP Signavio's workflow example of an international guideline. A gold standard is created for both BPMN2.0 processes and matched to real-world textual requirements from multiple regulatory documents. The evaluation and discussion provide insights into strengths and weaknesses of each method regarding applicability, automation, transparency, and reproducibility and provide guidelines on which method combinations will maximize benefits for given characteristics such as process usage, impact, and dynamics of an application scenario.
Topology-aware Debiased Self-supervised Graph Learning for Recommendation
Oct 24, 2023



In recommendation, graph-based Collaborative Filtering (CF) methods mitigate the data sparsity by introducing Graph Contrastive Learning (GCL). However, the random negative sampling strategy in these GCL-based CF models neglects the semantic structure of users (items), which not only introduces false negatives (negatives that are similar to anchor user (item)) but also ignores the potential positive samples. To tackle the above issues, we propose Topology-aware Debiased Self-supervised Graph Learning (TDSGL) for recommendation, which constructs contrastive pairs according to the semantic similarity between users (items). Specifically, since the original user-item interaction data commendably reflects the purchasing intent of users and certain characteristics of items, we calculate the semantic similarity between users (items) on interaction data. Then, given a user (item), we construct its negative pairs by selecting users (items) which embed different semantic structures to ensure the semantic difference between the given user (item) and its negatives. Moreover, for a user (item), we design a feature extraction module that converts other semantically similar users (items) into an auxiliary positive sample to acquire a more informative representation. Experimental results show that the proposed model outperforms the state-of-the-art models significantly on three public datasets. Our model implementation codes are available at https://github.com/malajikuai/TDSGL.
Towards Robust Offline Reinforcement Learning under Diverse Data Corruption
Oct 19, 2023



Offline reinforcement learning (RL) presents a promising approach for learning reinforced policies from offline datasets without the need for costly or unsafe interactions with the environment. However, datasets collected by humans in real-world environments are often noisy and may even be maliciously corrupted, which can significantly degrade the performance of offline RL. In this work, we first investigate the performance of current offline RL algorithms under comprehensive data corruption, including states, actions, rewards, and dynamics. Our extensive experiments reveal that implicit Q-learning (IQL) demonstrates remarkable resilience to data corruption among various offline RL algorithms. Furthermore, we conduct both empirical and theoretical analyses to understand IQL's robust performance, identifying its supervised policy learning scheme as the key factor. Despite its relative robustness, IQL still suffers from heavy-tail targets of Q functions under dynamics corruption. To tackle this challenge, we draw inspiration from robust statistics to employ the Huber loss to handle the heavy-tailedness and utilize quantile estimators to balance penalization for corrupted data and learning stability. By incorporating these simple yet effective modifications into IQL, we propose a more robust offline RL approach named Robust IQL (RIQL). Extensive experiments demonstrate that RIQL exhibits highly robust performance when subjected to diverse data corruption scenarios.
Terrain-Aware Quadrupedal Locomotion via Reinforcement Learning
Oct 11, 2023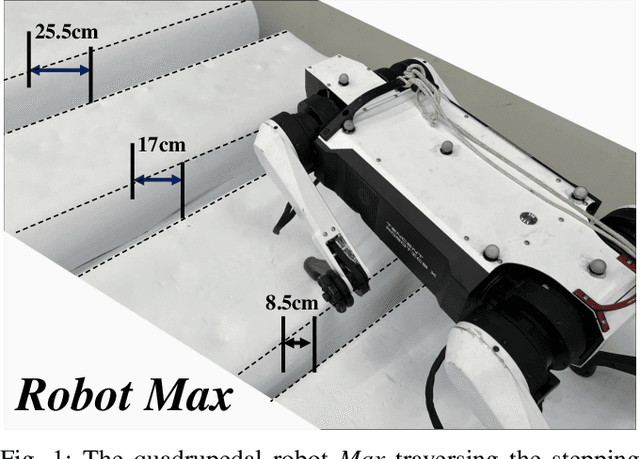
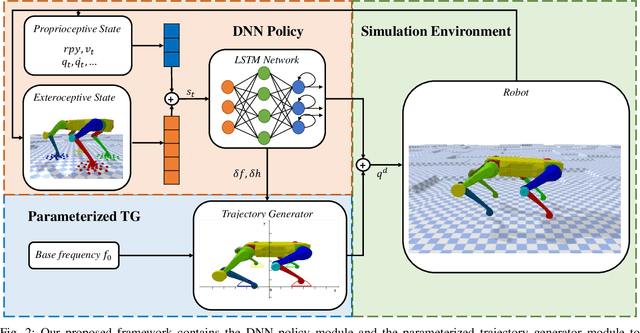
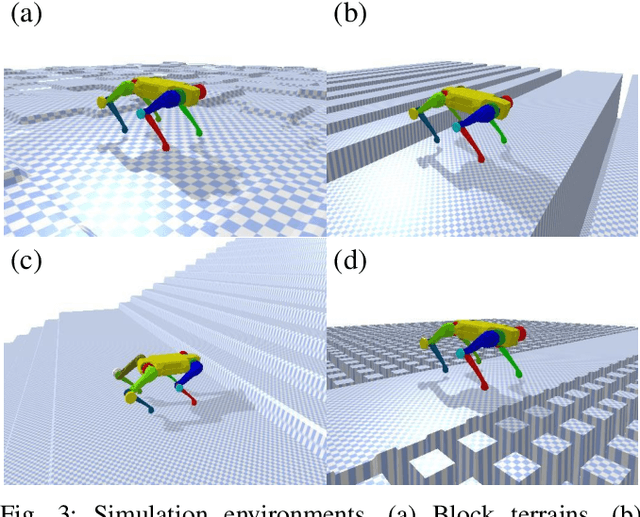
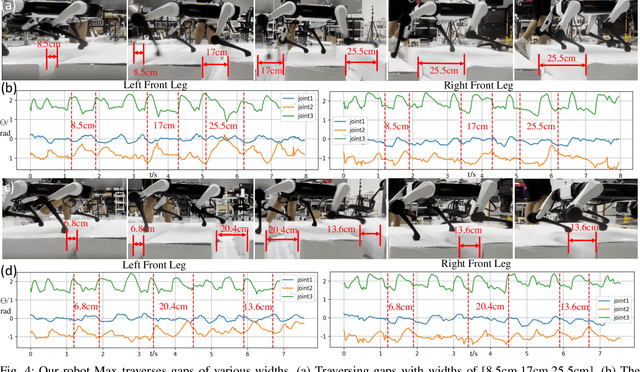
In nature, legged animals have developed the ability to adapt to challenging terrains through perception, allowing them to plan safe body and foot trajectories in advance, which leads to safe and energy-efficient locomotion. Inspired by this observation, we present a novel approach to train a Deep Neural Network (DNN) policy that integrates proprioceptive and exteroceptive states with a parameterized trajectory generator for quadruped robots to traverse rough terrains. Our key idea is to use a DNN policy that can modify the parameters of the trajectory generator, such as foot height and frequency, to adapt to different terrains. To encourage the robot to step on safe regions and save energy consumption, we propose foot terrain reward and lifting foot height reward, respectively. By incorporating these rewards, our method can learn a safer and more efficient terrain-aware locomotion policy that can move a quadruped robot flexibly in any direction. To evaluate the effectiveness of our approach, we conduct simulation experiments on challenging terrains, including stairs, stepping stones, and poles. The simulation results demonstrate that our approach can successfully direct the robot to traverse such tough terrains in any direction. Furthermore, we validate our method on a real legged robot, which learns to traverse stepping stones with gaps over 25.5cm.
Robust Quadrupedal Locomotion via Risk-Averse Policy Learning
Sep 01, 2023



The robustness of legged locomotion is crucial for quadrupedal robots in challenging terrains. Recently, Reinforcement Learning (RL) has shown promising results in legged locomotion and various methods try to integrate privileged distillation, scene modeling, and external sensors to improve the generalization and robustness of locomotion policies. However, these methods are hard to handle uncertain scenarios such as abrupt terrain changes or unexpected external forces. In this paper, we consider a novel risk-sensitive perspective to enhance the robustness of legged locomotion. Specifically, we employ a distributional value function learned by quantile regression to model the aleatoric uncertainty of environments, and perform risk-averse policy learning by optimizing the worst-case scenarios via a risk distortion measure. Extensive experiments in both simulation environments and a real Aliengo robot demonstrate that our method is efficient in handling various external disturbances, and the resulting policy exhibits improved robustness in harsh and uncertain situations in legged locomotion. Videos are available at https://risk-averse-locomotion.github.io/.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Collaborative Route Planning of UAVs, Workers and Cars for Crowdsensing in Disaster Response
Aug 21, 2023



Efficiently obtaining the up-to-date information in the disaster-stricken area is the key to successful disaster response. Unmanned aerial vehicles (UAVs), workers and cars can collaborate to accomplish sensing tasks, such as data collection, in disaster-stricken areas. In this paper, we explicitly address the route planning for a group of agents, including UAVs, workers, and cars, with the goal of maximizing the task completion rate. We propose MANF-RL-RP, a heterogeneous multi-agent route planning algorithm that incorporates several efficient designs, including global-local dual information processing and a tailored model structure for heterogeneous multi-agent systems. Global-local dual information processing encompasses the extraction and dissemination of spatial features from global information, as well as the partitioning and filtering of local information from individual agents. Regarding the construction of the model structure for heterogeneous multi-agent, we perform the following work. We design the same data structure to represent the states of different agents, prove the Markovian property of the decision-making process of agents to simplify the model structure, and also design a reasonable reward function to train the model. Finally, we conducted detailed experiments based on the rich simulation data. In comparison to the baseline algorithms, namely Greedy-SC-RP and MANF-DNN-RP, MANF-RL-RP has exhibited a significant improvement in terms of task completion rate.