 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeniePath: Graph Neural Networks with Adaptive Receptive Paths
Nov 05, 2018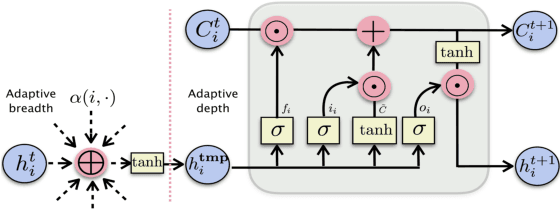

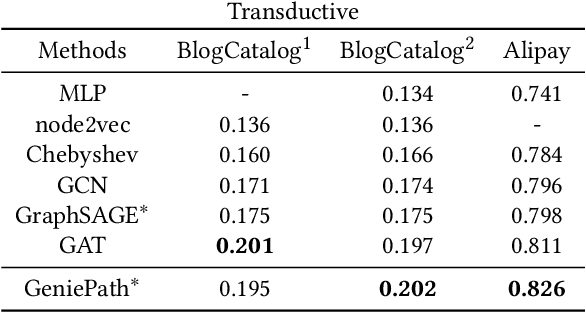
We present, GeniePath, a scalable approach for learning adaptive receptive fields of neural networks defined on permutation invariant graph data. In GeniePath, we propose an adaptive path layer consists of two complementary functions designed for breadth and depth exploration respectively, where the former learns the importance of different sized neighborhoods, while the latter extracts and filters signals aggregated from neighbors of different hops away. Our method works in both transductive and inductive settings, and extensive experiments compared with competitive methods show that our approaches yield state-of-the-art results on large graphs.
Learning towards Minimum Hyperspherical Energy
Oct 27, 2018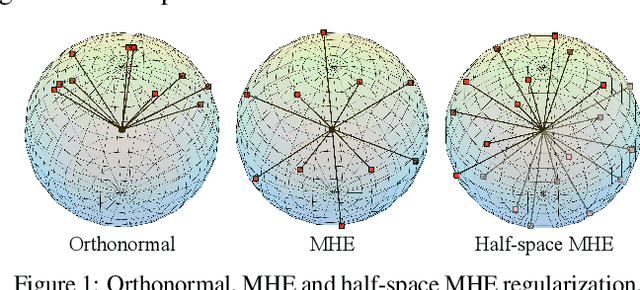
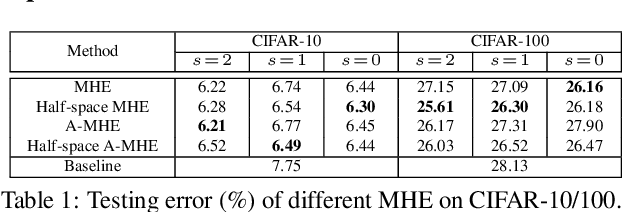
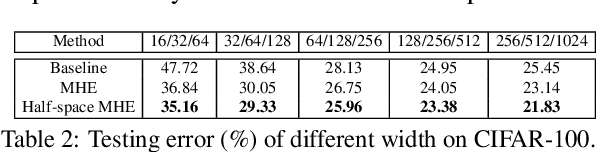
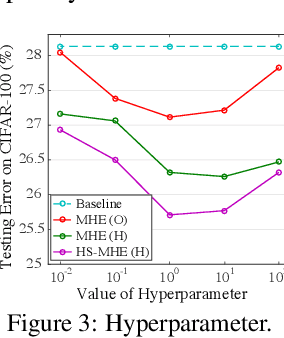
Neural networks are a powerful class of nonlinear functions that can be trained end-to-end on various applications. While the over-parametrization nature in many neural networks renders the ability to fit complex functions and the strong representation power to handle challenging tasks, it also leads to highly correlated neurons that can hurt the generalization ability and incur unnecessary computation cost. As a result, how to regularize the network to avoid undesired representation redundancy becomes an important issue. To this end, we draw inspiration from a well-known problem in physics -- Thomson problem, where one seeks to find a state that distributes N electrons on a unit sphere as evenly as possible with minimum potential energy. In light of this intuition, we reduce the redundancy regularization problem to generic energy minimization, and propose a minimum hyperspherical energy (MHE) objective as generic regularization for neural networks. We also propose a few novel variants of MHE, and provide some insights from a theoretical point of view. Finally, we apply neural networks with MHE regularization to several challenging tasks. Extensive experiments demonstrate the effectiveness of our intuition, by showing the superior performance with MHE regularization.
Latent Dirichlet Allocation for Internet Price War
Aug 23, 2018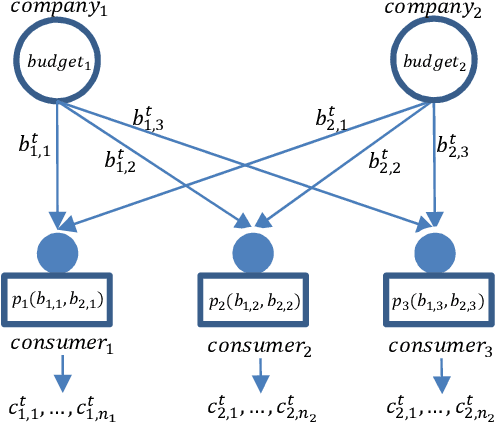
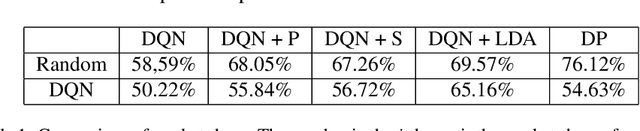
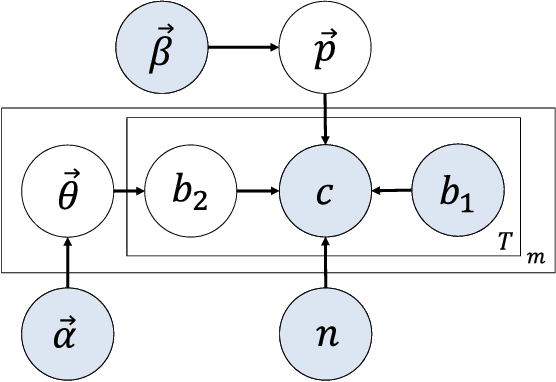

Internet market makers are always facing intense competitive environment, where personalized price reductions or discounted coupons are provided for attracting more customers. Participants in such a price war scenario have to invest a lot to catch up with other competitors. However, such a huge cost of money may not always lead to an improvement of market share. This is mainly due to a lack of information about others' strategies or customers' willingness when participants develop their strategies. In order to obtain this hidden information through observable data, we study the relationship between companies and customers in the Internet price war. Theoretically, we provide a formalization of the problem as a stochastic game with imperfect and incomplete information. Then we develop a variant of Latent Dirichlet Allocation (LDA) to infer latent variables under the current market environment, which represents the preferences of customers and strategies of competitors. To our best knowledge, it is the first time that LDA is applied to game scenario. We conduct simulated experiments where our LDA model exhibits a significant improvement on finding strategies in the Internet price war by including all available market information of the market maker's competitors. And the model is applied to an open dataset for real business. Through comparisons on the likelihood of prediction for users' behavior and distribution distance between inferred opponent's strategy and the real one, our model is shown to be able to provide a better understanding for the market environment. Our work marks a successful learning method to infer latent information in the environment of price war by the LDA modeling, and sets an example for related competitive applications to follow.
L-Shapley and C-Shapley: Efficient Model Interpretation for Structured Data
Aug 08, 2018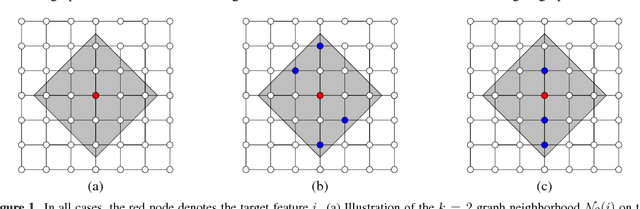

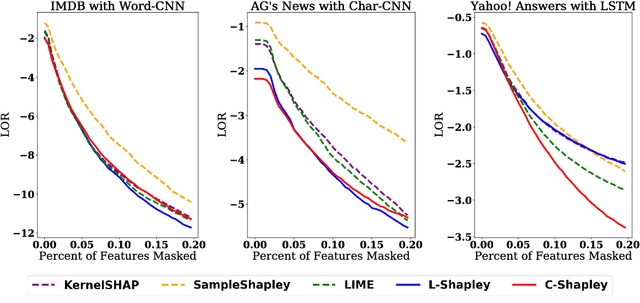

We study instancewise feature importance scoring as a method for model interpretation. Any such method yields, for each predicted instance, a vector of importance scores associated with the feature vector. Methods based on the Shapley score have been proposed as a fair way of computing feature attributions of this kind, but incur an exponential complexity in the number of features. This combinatorial explosion arises from the definition of the Shapley value and prevents these methods from being scalable to large data sets and complex models. We focus on settings in which the data have a graph structure, and the contribution of features to the target variable is well-approximated by a graph-structured factorization. In such settings, we develop two algorithms with linear complexity for instancewise feature importance scoring. We establish the relationship of our methods to the Shapley value and another closely related concept known as the Myerson value from cooperative game theory. We demonstrate on both language and image data that our algorithms compare favorably with other methods for model interpretation.
Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection
Jul 27, 2018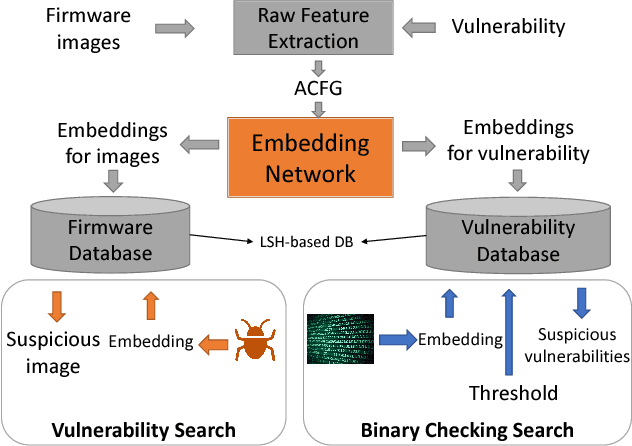
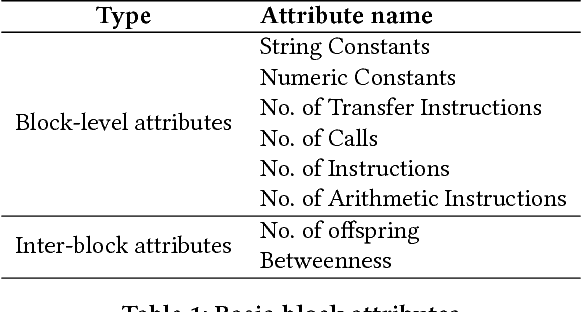
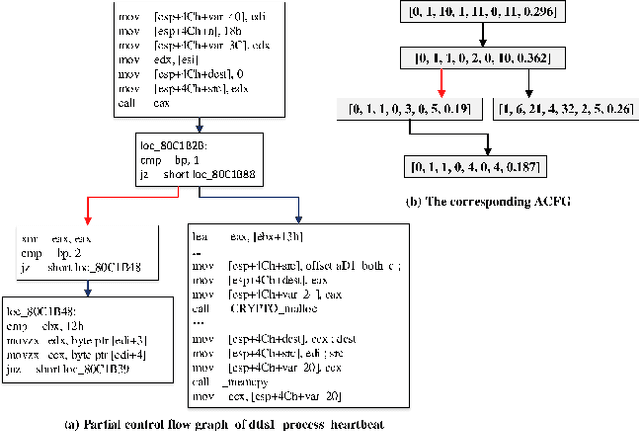
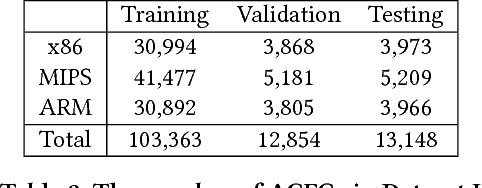
The problem of cross-platform binary code similarity detection aims at detecting whether two binary functions coming from different platforms are similar or not. It has many security applications, including plagiarism detection, malware detection, vulnerability search, etc. Existing approaches rely on approximate graph matching algorithms, which are inevitably slow and sometimes inaccurate, and hard to adapt to a new task. To address these issues, in this work, we propose a novel neural network-based approach to compute the embedding, i.e., a numeric vector, based on the control flow graph of each binary function, then the similarity detection can be done efficiently by measuring the distance between the embeddings for two functions. We implement a prototype called Gemini. Our extensive evaluation shows that Gemini outperforms the state-of-the-art approaches by large margins with respect to similarity detection accuracy. Further, Gemini can speed up prior art's embedding generation time by 3 to 4 orders of magnitude and reduce the required training time from more than 1 week down to 30 minutes to 10 hours. Our real world case studies demonstrate that Gemini can identify significantly more vulnerable firmware images than the state-of-the-art, i.e., Genius. Our research showcases a successful application of deep learning on computer security problems.
Learning to Explain: An Information-Theoretic Perspective on Model Interpretation
Jun 14, 2018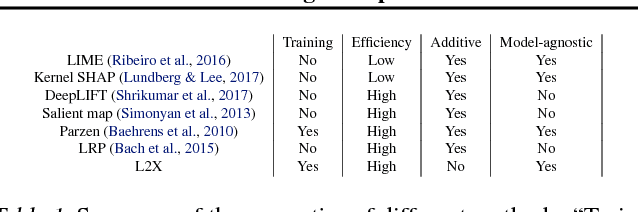
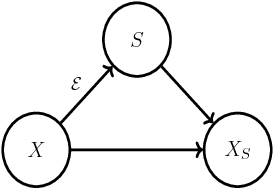
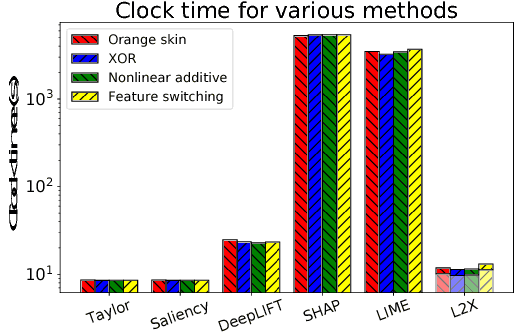

We introduce instancewise feature selection as a methodology for model interpretation. Our method is based on learning a function to extract a subset of features that are most informative for each given example. This feature selector is trained to maximize the mutual information between selected features and the response variable, where the conditional distribution of the response variable given the input is the model to be explained. We develop an efficient variational approximation to the mutual information, and show the effectiveness of our method on a variety of synthetic and real data sets using both quantitative metrics and human evaluation.
Adversarial Attack on Graph Structured Data
Jun 06, 2018
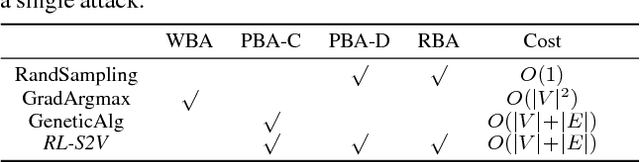
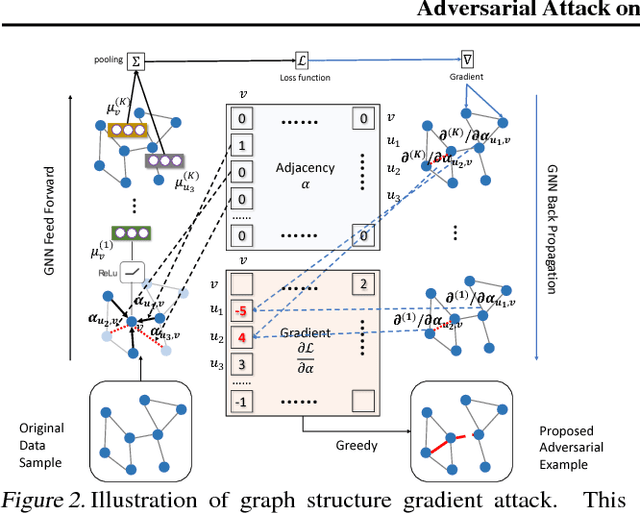
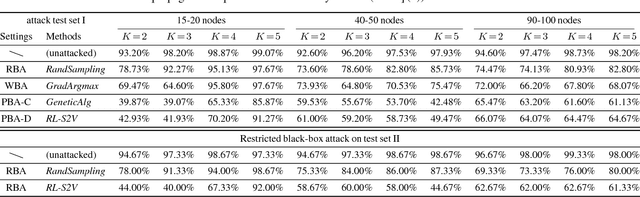
Deep learning on graph structures has shown exciting results in various applications. However, few attentions have been paid to the robustness of such models, in contrast to numerous research work for image or text adversarial attack and defense. In this paper, we focus on the adversarial attacks that fool the model by modifying the combinatorial structure of data. We first propose a reinforcement learning based attack method that learns the generalizable attack policy, while only requiring prediction labels from the target classifier. Also, variants of genetic algorithms and gradient methods are presented in the scenario where prediction confidence or gradients are available. We use both synthetic and real-world data to show that, a family of Graph Neural Network models are vulnerable to these attacks, in both graph-level and node-level classification tasks. We also show such attacks can be used to diagnose the learned classifiers.
Towards Black-box Iterative Machine Teaching
Jun 05, 2018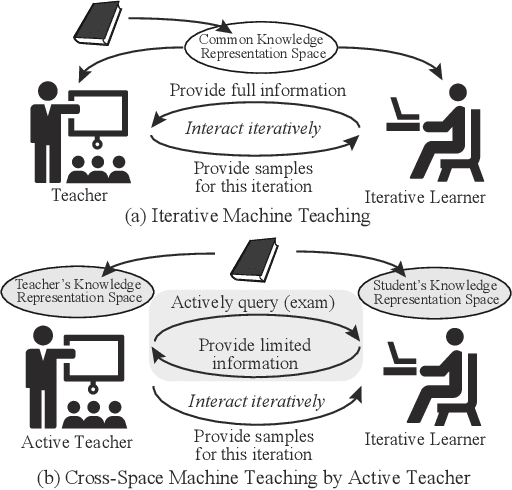

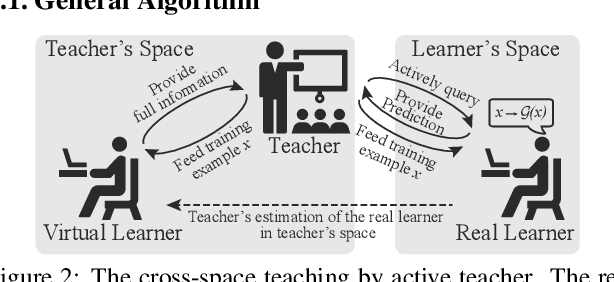
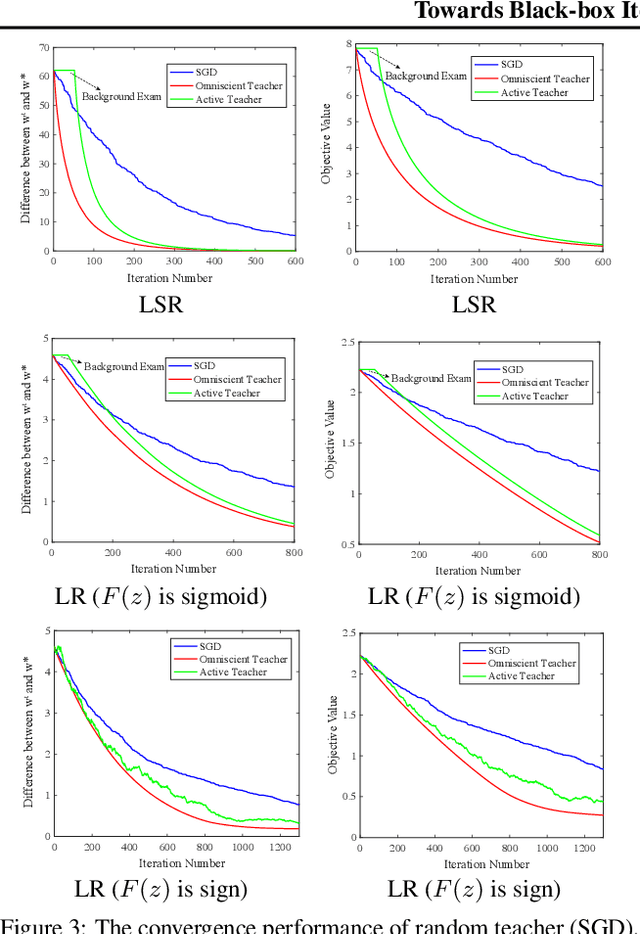
In this paper, we make an important step towards the black-box machine teaching by considering the cross-space machine teaching, where the teacher and the learner use different feature representations and the teacher can not fully observe the learner's model. In such scenario, we study how the teacher is still able to teach the learner to achieve faster convergence rate than the traditional passive learning. We propose an active teacher model that can actively query the learner (i.e., make the learner take exams) for estimating the learner's status and provably guide the learner to achieve faster convergence. The sample complexities for both teaching and query are provided. In the experiments, we compare the proposed active teacher with the omniscient teacher and verify the effectiveness of the active teacher model.
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
Jun 05, 2018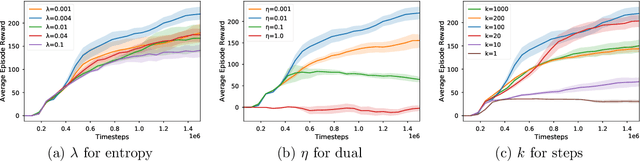
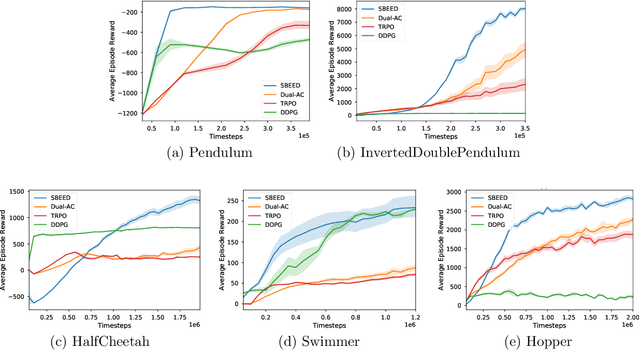
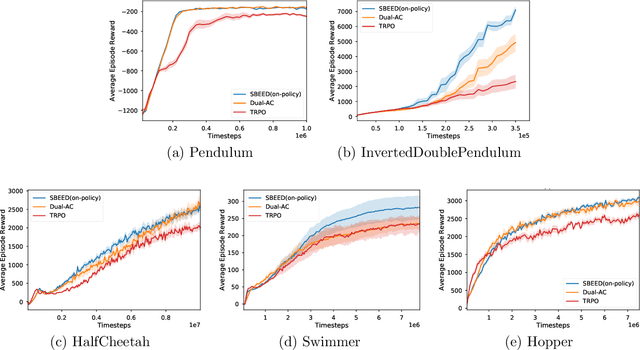
When function approximation is used, solving the Bellman optimality equation with stability guarantees has remained a major open problem in reinforcement learning for decades. The fundamental difficulty is that the Bellman operator may become an expansion in general, resulting in oscillating and even divergent behavior of popular algorithms like Q-learning. In this paper, we revisit the Bellman equation, and reformulate it into a novel primal-dual optimization problem using Nesterov's smoothing technique and the Legendre-Fenchel transformation. We then develop a new algorithm, called Smoothed Bellman Error Embedding, to solve this optimization problem where any differentiable function class may be used. We provide what we believe to be the first convergence guarantee for general nonlinear function approximation, and analyze the algorithm's sample complexity. Empirically, our algorithm compares favorably to state-of-the-art baselines in several benchmark control problems.
KG^2: Learning to Reason Science Exam Questions with Contextual Knowledge Graph Embeddings
May 31, 2018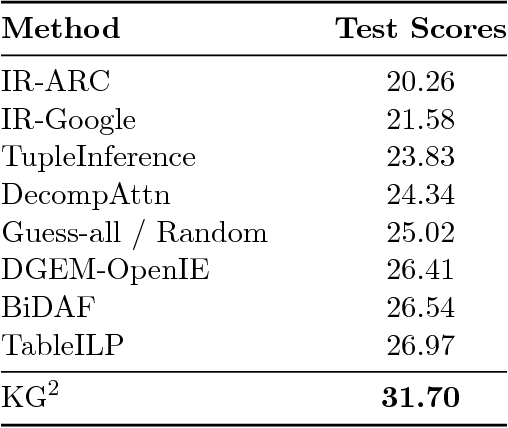
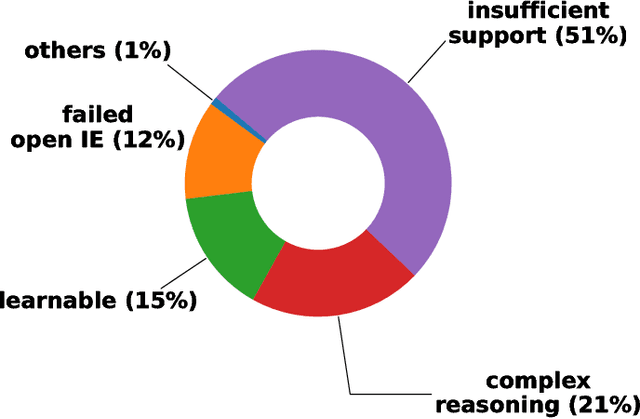
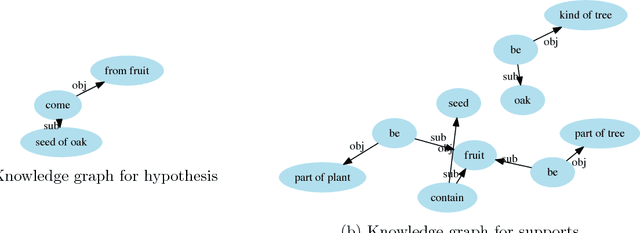
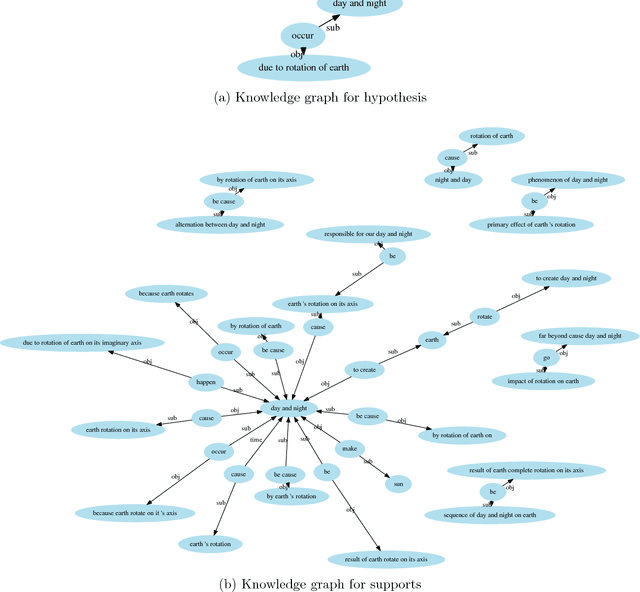
The AI2 Reasoning Challenge (ARC), a new benchmark dataset for question answering (QA) has been recently released. ARC only contains natural science questions authored for human exams, which are hard to answer and require advanced logic reasoning. On the ARC Challenge Set, existing state-of-the-art QA systems fail to significantly outperform random baseline, reflecting the difficult nature of this task. In this paper, we propose a novel framework for answering science exam questions, which mimics human solving process in an open-book exam. To address the reasoning challenge, we construct contextual knowledge graphs respectively for the question itself and supporting sentences. Our model learns to reason with neural embeddings of both knowledge graphs. Experiments on the ARC Challenge Set show that our model outperforms the previous state-of-the-art QA systems.