 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Probabilistic Logic Reasoning with Graph Neural Networks
Feb 04, 2020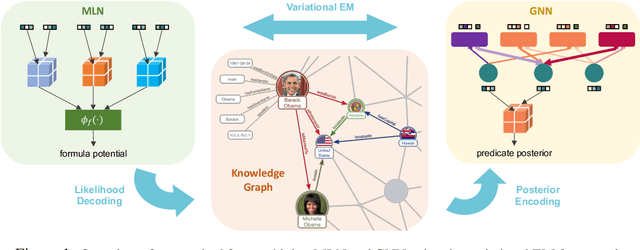
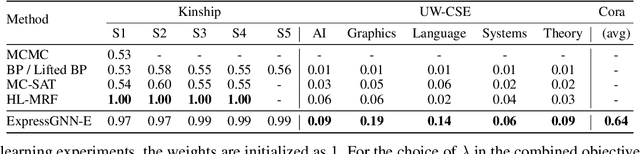
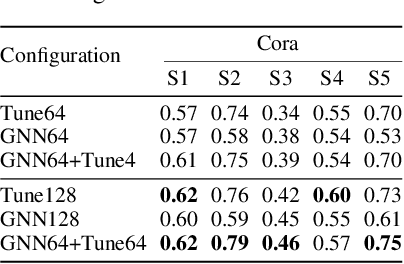
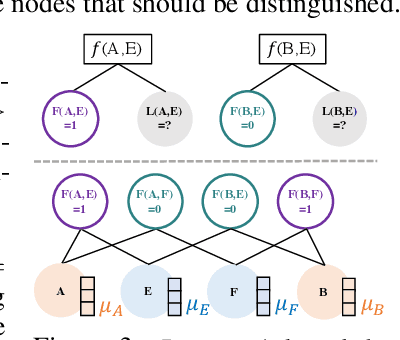
Markov Logic Networks (MLNs), which elegantly combine logic rules and probabilistic graphical models, can be used to address many knowledge graph problems. However, inference in MLN is computationally intensive, making the industrial-scale application of MLN very difficult. In recent years, graph neural networks (GNNs) have emerged as efficient and effective tools for large-scale graph problems. Nevertheless, GNNs do not explicitly incorporate prior logic rules into the models, and may require many labeled examples for a target task. In this paper, we explore the combination of MLNs and GNNs, and use graph neural networks for variational inference in MLN. We propose a GNN variant, named ExpressGNN, which strikes a nice balance between the representation power and the simplicity of the model. Our extensive experiments on several benchmark datasets demonstrate that ExpressGNN leads to effective and efficient probabilistic logic reasoning.
Retrosynthesis Prediction with Conditional Graph Logic Network
Jan 06, 2020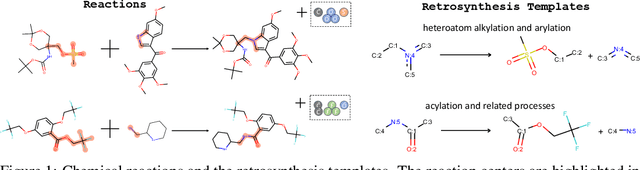
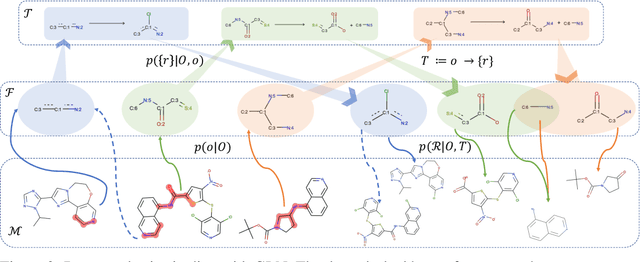
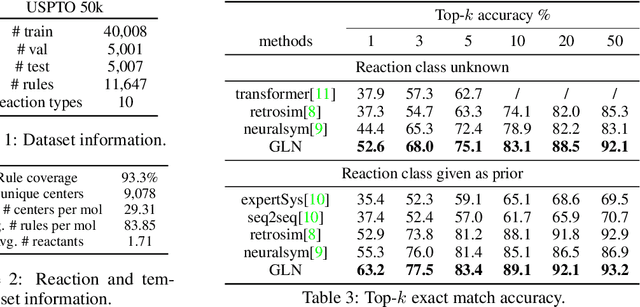
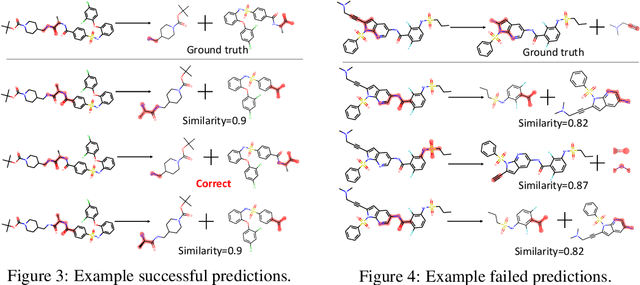
Retrosynthesis is one of the fundamental problems in organic chemistry. The task is to identify reactants that can be used to synthesize a specified product molecule. Recently, computer-aided retrosynthesis is finding renewed interest from both chemistry and computer science communities. Most existing approaches rely on template-based models that define subgraph matching rules, but whether or not a chemical reaction can proceed is not defined by hard decision rules. In this work, we propose a new approach to this task using the Conditional Graph Logic Network, a conditional graphical model built upon graph neural networks that learns when rules from reaction templates should be applied, implicitly considering whether the resulting reaction would be both chemically feasible and strategic. We also propose an efficient hierarchical sampling to alleviate the computation cost. While achieving a significant improvement of $8.1\%$ over current state-of-the-art methods on the benchmark dataset, our model also offers interpretations for the prediction.
Neural Similarity Learning
Dec 06, 2019



Inner product-based convolution has been the founding stone of convolutional neural networks (CNNs), enabling end-to-end learning of visual representation. By generalizing inner product with a bilinear matrix, we propose the neural similarity which serves as a learnable parametric similarity measure for CNNs. Neural similarity naturally generalizes the convolution and enhances flexibility. Further, we consider the neural similarity learning (NSL) in order to learn the neural similarity adaptively from training data. Specifically, we propose two different ways of learning the neural similarity: static NSL and dynamic NSL. Interestingly, dynamic neural similarity makes the CNN become a dynamic inference network. By regularizing the bilinear matrix, NSL can be viewed as learning the shape of kernel and the similarity measure simultaneously. We further justify the effectiveness of NSL with a theoretical viewpoint. Most importantly, NSL shows promising performance in visual recognition and few-shot learning, validating the superiority of NSL over the inner product-based convolution counterparts.
Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
Nov 13, 2019
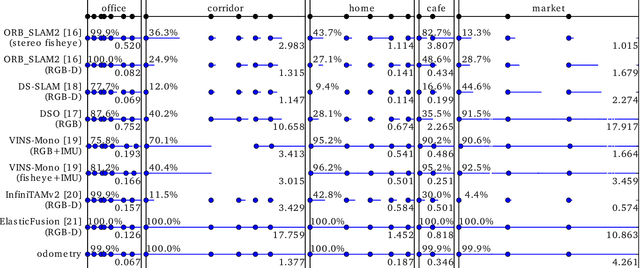
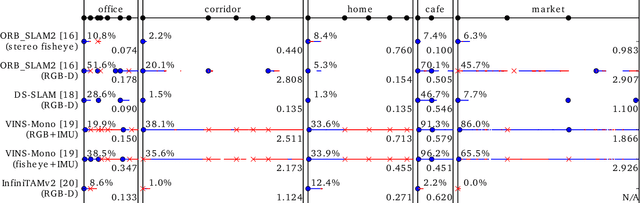
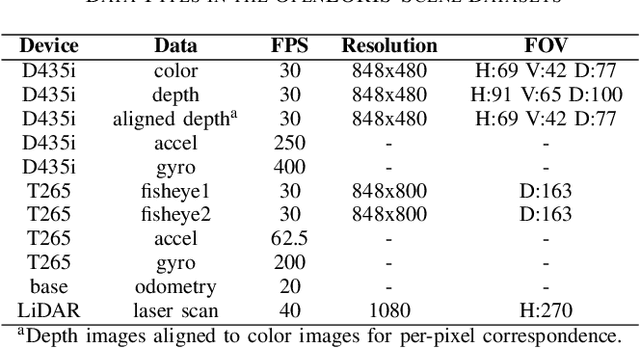
Service robots should be able to operate autonomously in dynamic and daily changing environments over an extended period of time. While Simultaneous Localization And Mapping (SLAM) is one of the most fundamental problems for robotic autonomy, most existing SLAM works are evaluated with data sequences that are recorded in a short period of time. In real-world deployment, there can be out-of-sight scene changes caused by both natural factors and human activities. For example, in home scenarios, most objects may be movable, replaceable or deformable, and the visual features of the same place may be significantly different in some successive days. Such out-of-sight dynamics pose great challenges to the robustness of pose estimation, and hence a robot's long-term deployment and operation. To differentiate the forementioned problem from the conventional works which are usually evaluated in a static setting in a single run, the term lifelong SLAM is used here to address SLAM problems in an ever-changing environment over a long period of time. To accelerate lifelong SLAM research, we release the OpenLORIS-Scene datasets. The data are collected in real-world indoor scenes, for multiple times in each place to include scene changes in real life. We also design benchmarking metrics for lifelong SLAM, with which the robustness and accuracy of pose estimation are evaluated separately. The datasets and benchmark are available online at https://lifelong-robotic-vision.github.io/dataset/scene.
Learn to Explain Efficiently via Neural Logic Inductive Learning
Oct 06, 2019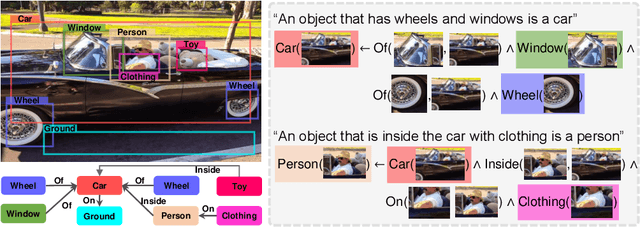
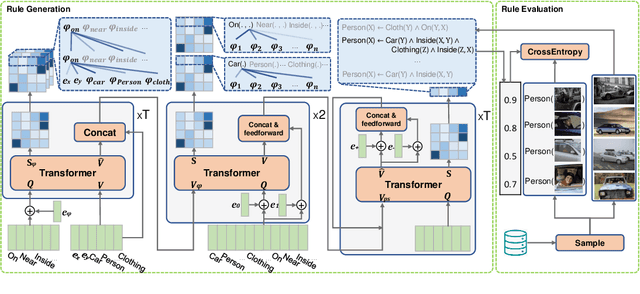
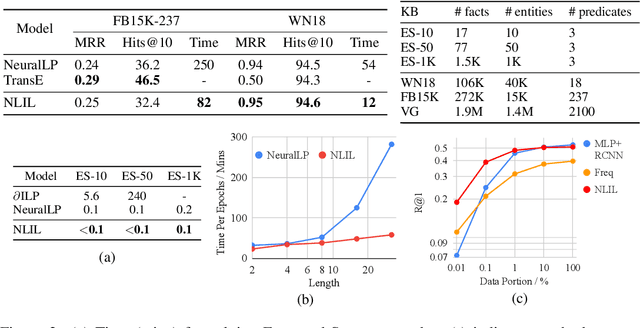
The capability of making interpretable and self-explanatory decisions is essential for developing responsible machine learning systems. In this work, we study the learning to explain problem in the scope of inductive logic programming (ILP). We propose Neural Logic Inductive Learning (NLIL), an efficient differentiable ILP framework that learns first-order logic rules that can explain the patterns in the data. In experiments, compared with the state-of-the-art methods, we find NLIL can search for rules that are x10 times longer while remaining x3 times faster. We also show that NLIL can scale to large image datasets, i.e. Visual Genome, with 1M entities.
Can Graph Neural Networks Help Logic Reasoning?
Jun 27, 2019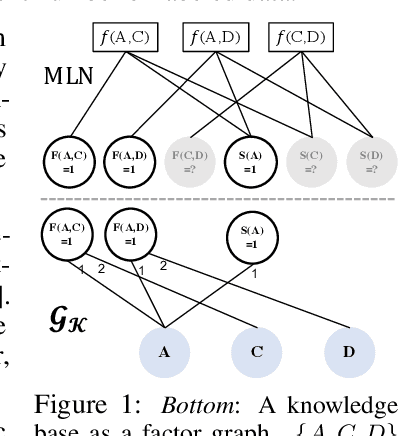

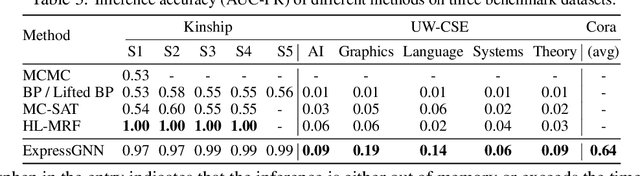
Effectively combining logic reasoning and probabilistic inference has been a long-standing goal of machine learning: the former has the ability to generalize with small training data, while the latter provides a principled framework for dealing with noisy data. However, existing methods for combining the best of both worlds are typically computationally intensive. In this paper, we focus on Markov Logic Networks and explore the use of graph neural networks (GNNs) for representing probabilistic logic inference. It is revealed from our analysis that the representation power of GNN alone is not enough for such a task. We instead propose a more expressive variant, called ExpressGNN, which can perform effective probabilistic logic inference while being able to scale to a large number of entities. We demonstrate by several benchmark datasets that ExpressGNN has the potential to advance probabilistic logic reasoning to the next stage.
Optimal Solution Predictions for Mixed Integer Programs
Jun 23, 2019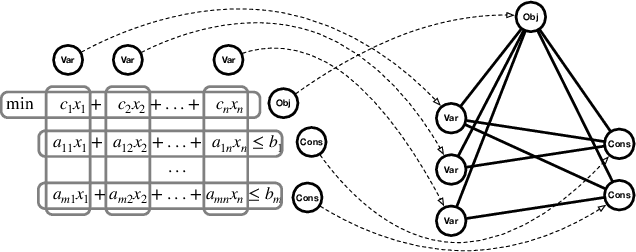
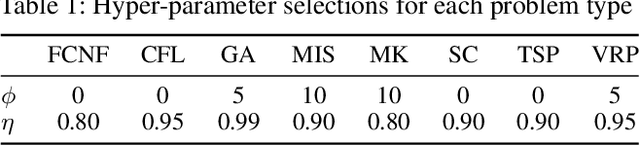
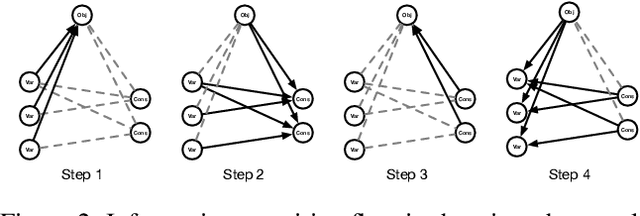
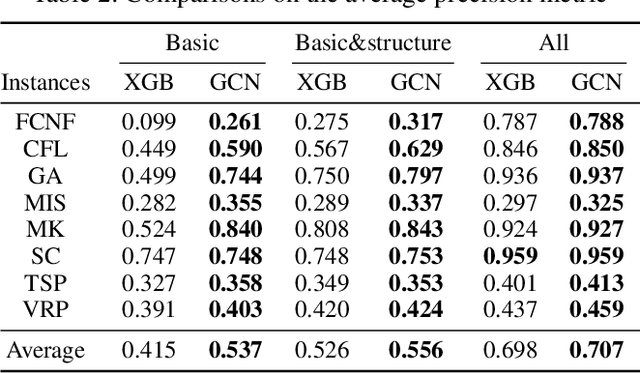
Mixed Integer Programming (MIP) is one of the most widely used modeling techniques to deal with combinatorial optimization problems. In many applications, a similar MIP model is solved on a regular basis, maintaining remarkable similarities in model structures and solution appearances but differing in formulation coefficients. This offers the opportunity for machine learning method to explore the correlations between model structures and the resulting solution values. To address this issue, we propose to represent an MIP instance using a tripartite graph, based on which a Graph Convolutional Network (GCN) is constructed to predict solution values for binary variables. The predicted solutions are used to generate a local branching cut to the model which accelerate the solution process for MIP. Computational evaluations on 8 distinct types of MIP problems show that the proposed framework improves the performance of a state-of-the-art open source MIP solver significantly in terms of running time and solution quality.
Compressive Hyperspherical Energy Minimization
Jun 12, 2019
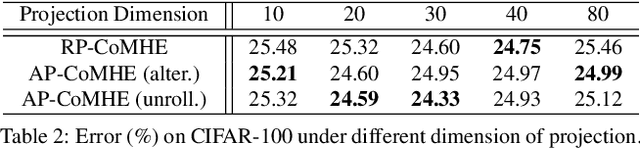
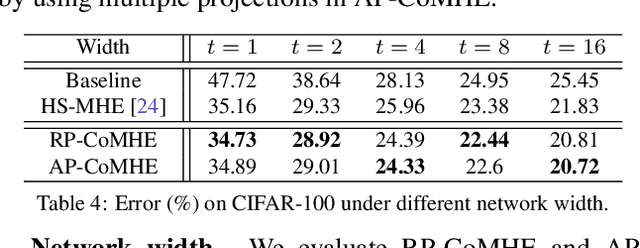
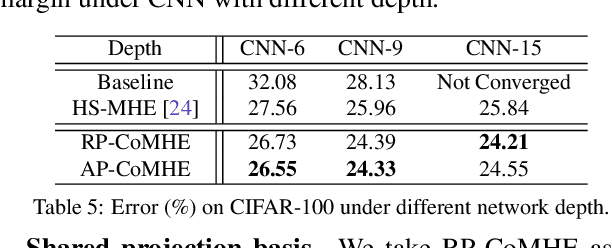
Recent work on minimum hyperspherical energy (MHE) has demonstrated its potential in regularizing neural networks and improving their generalization. MHE was inspired by the Thomson problem in physics, where the distribution of multiple propelling electrons on a unit sphere can be modeled via minimizing some potential energy. Despite the practical effectiveness, MHE suffers from local minima as their number increases dramatically in high dimensions, limiting MHE from unleashing its full potential in improving network generalization. To address this issue, we propose compressive minimum hyperspherical energy (CoMHE) as an alternative regularization for neural networks. Specifically, CoMHE utilizes a projection mapping to reduce the dimensionality of neurons and minimizes their hyperspherical energy. According to different constructions for the projection matrix, we propose two major variants: random projection CoMHE and angle-preserving CoMHE. Furthermore, we provide theoretical insights to justify its effectiveness. We show that CoMHE consistently outperforms MHE by a significant margin in comprehensive experiments, and demonstrate its diverse applications to a variety of tasks such as image recognition and point cloud recognition.
GLAD: Learning Sparse Graph Recovery
Jun 01, 2019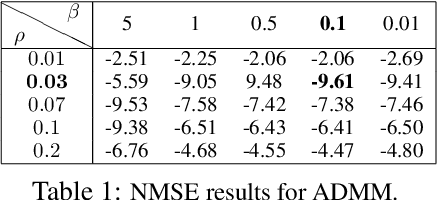
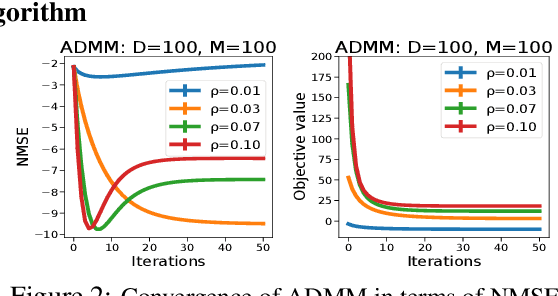
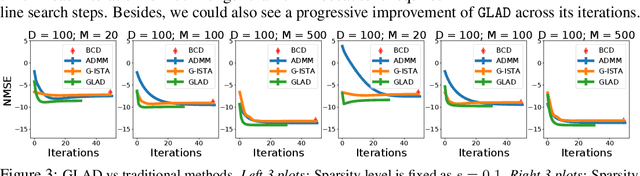
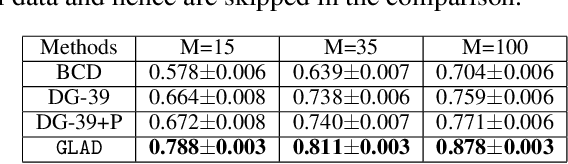
Recovering sparse conditional independence graphs from data is a fundamental problem in machine learning with wide applications. A popular formulation of the problem is an $\ell_1$ regularized maximum likelihood estimation. Many convex optimization algorithms have been designed to solve this formulation to recover the graph structure. Recently, there is a surge of interest to learn algorithms directly based on data, and in this case, learn to map empirical covariance to the sparse precision matrix. However, it is a challenging task in this case, since the symmetric positive definiteness (SPD) and sparsity of the matrix are not easy to enforce in learned algorithms, and a direct mapping from data to precision matrix may contain many parameters. We propose a deep learning architecture, GLAD, which uses an Alternating Minimization (AM) algorithm as our model inductive bias, and learns the model parameters via supervised learning. We show that GLAD learns a very compact and effective model for recovering sparse graph from data.
Exponential Family Estimation via Adversarial Dynamics Embedding
Apr 27, 2019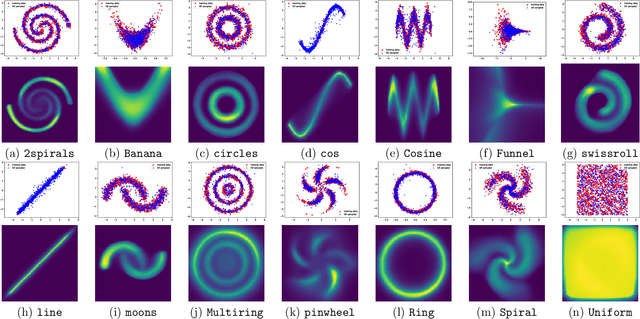
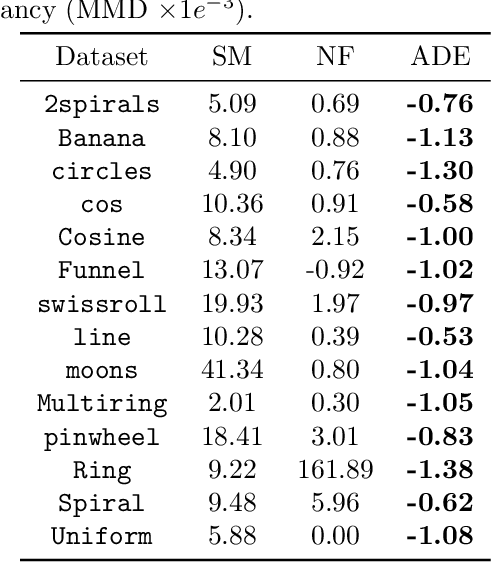
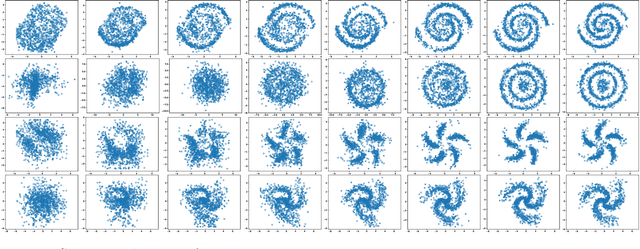
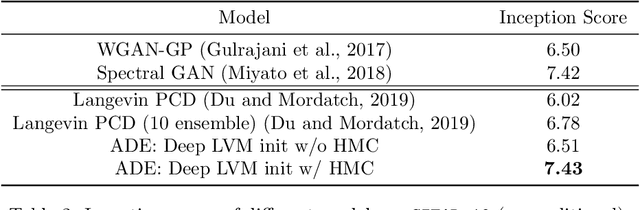
We present an efficient algorithm for maximum likelihood estimation (MLE) of the general exponential family, even in cases when the energy function is represented by a deep neural network. We consider the primal-dual view of the MLE for the kinectics augmented model, which naturally introduces an adversarial dual sampler. The sampler will be represented by a novel neural network architectures, dynamics embeddings, mimicking the dynamical-based samplers, e.g., Hamiltonian Monte-Carlo and its variants. The dynamics embedding parametrization inherits the flexibility from HMC, and provides tractable entropy estimation of the augmented model. Meanwhile, it couples the adversarial dual samplers with the primal model, reducing memory and sample complexity. We further show that several existing estimators, including contrastive divergence (Hinton, 2002), score matching (Hyv\"arinen, 2005), pseudo-likelihood (Besag, 1975), noise-contrastive estimation (Gutmann and Hyv\"arinen, 2010), non-local contrastive objectives (Vickrey et al., 2010), and minimum probability flow (Sohl-Dickstein et al., 2011), can be recast as the special cases of the proposed method with different prefixed dual samplers. Finally, we empirically demonstrate the superiority of the proposed estimator against existing state-of-the-art methods on synthetic and real-world benchmarks.