 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoFlow: A Flow-Based Generative Model for Video
Mar 04, 2019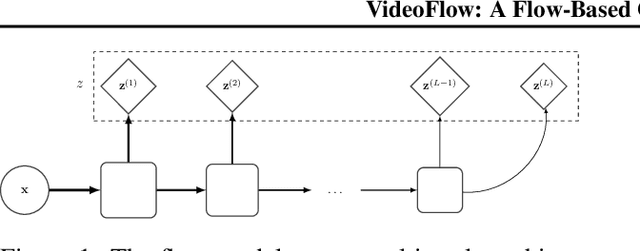

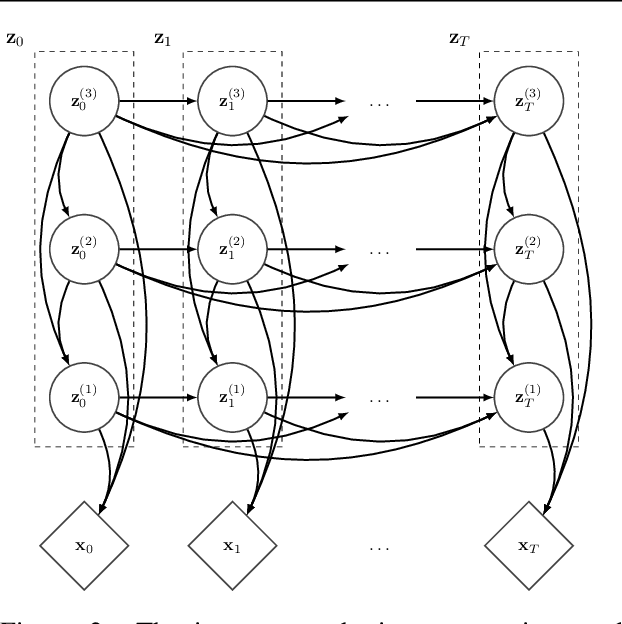
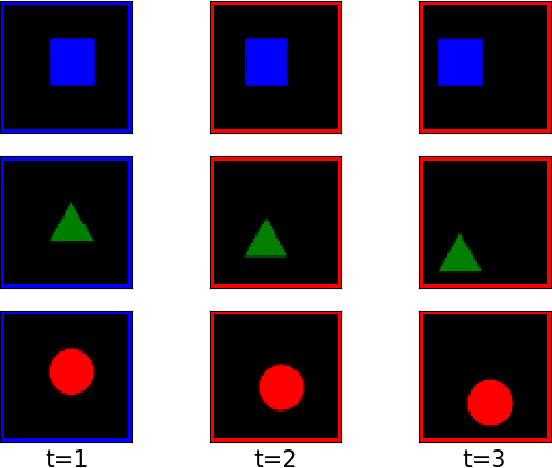
Generative models that can model and predict sequences of future events can, in principle, learn to capture complex real-world phenomena, such as physical interactions. In particular, learning predictive models of videos offers an especially appealing mechanism to enable a rich understanding of the physical world: videos of real-world interactions are plentiful and readily available, and a model that can predict future video frames can not only capture useful representations of the world, but can be useful in its own right, for problems such as model-based robotic control. However, a central challenge in video prediction is that the future is highly uncertain: a sequence of past observations of events can imply many possible futures. Although a number of recent works have studied probabilistic models that can represent uncertain futures, such models are either extremely expensive computationally (as in the case of pixel-level autoregressive models), or do not directly optimize the likelihood of the data. In this work, we propose a model for video prediction based on normalizing flows, which allows for direct optimization of the data likelihood, and produces high-quality stochastic predictions. To our knowledge, our work is the first to propose multi-frame video prediction with normalizing flows. We describe an approach for modeling the latent space dynamics, and demonstrate that flow-based generative models offer a viable and competitive approach to generative modeling of video.
Learning Awareness Models
Apr 17, 2018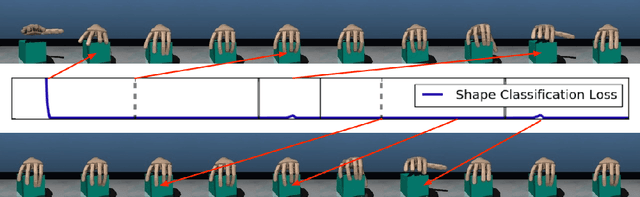
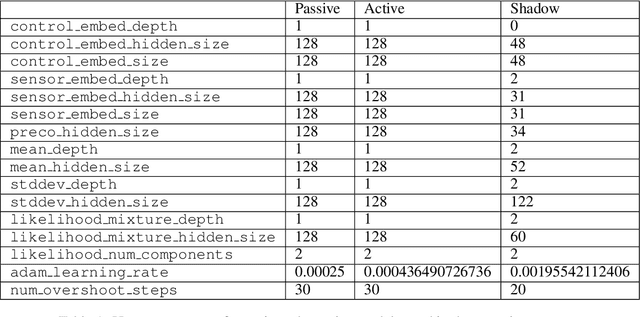

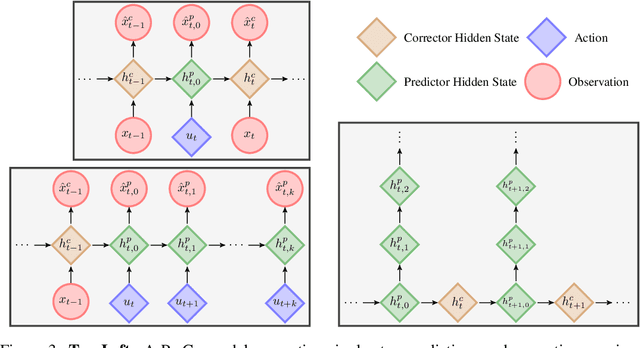
We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.
Learnable Explicit Density for Continuous Latent Space and Variational Inference
Oct 06, 2017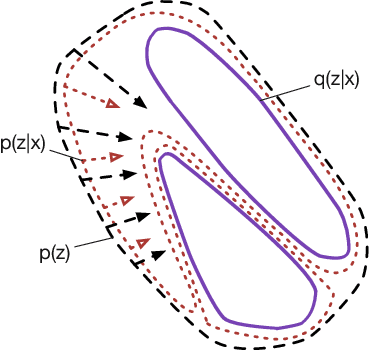
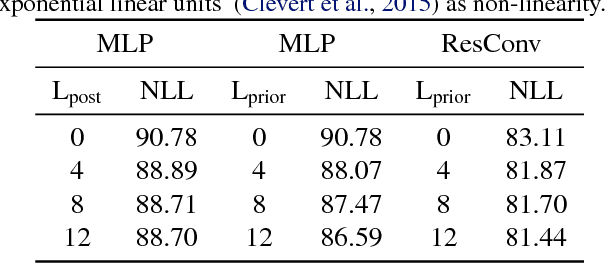
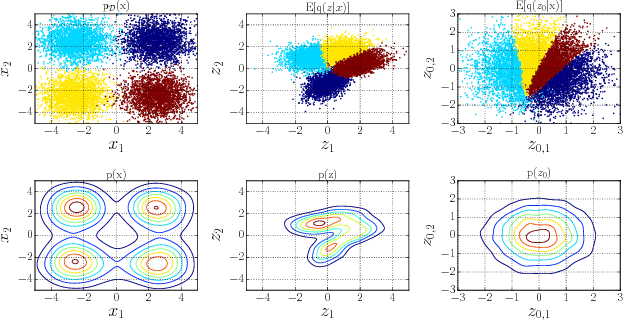

In this paper, we study two aspects of the variational autoencoder (VAE): the prior distribution over the latent variables and its corresponding posterior. First, we decompose the learning of VAEs into layerwise density estimation, and argue that having a flexible prior is beneficial to both sample generation and inference. Second, we analyze the family of inverse autoregressive flows (inverse AF) and show that with further improvement, inverse AF could be used as universal approximation to any complicated posterior. Our analysis results in a unified approach to parameterizing a VAE, without the need to restrict ourselves to use factorial Gaussians in the latent real space.
Sharp Minima Can Generalize For Deep Nets
May 15, 2017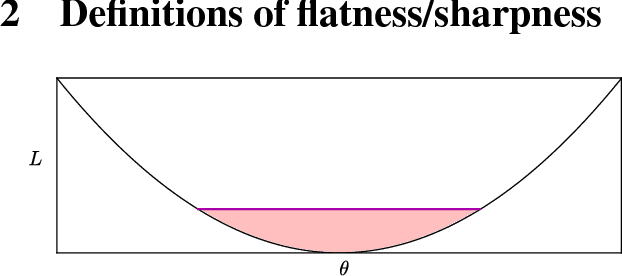
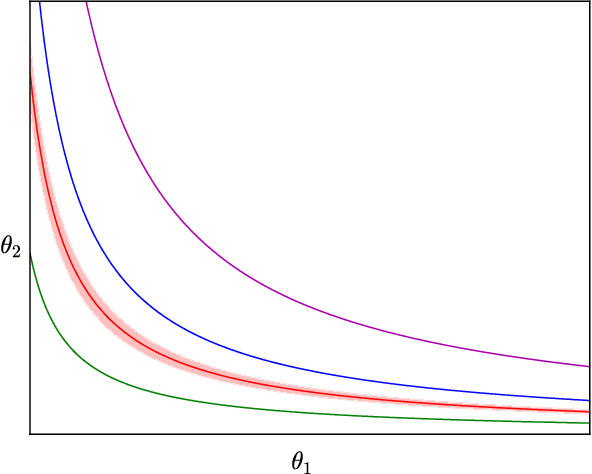
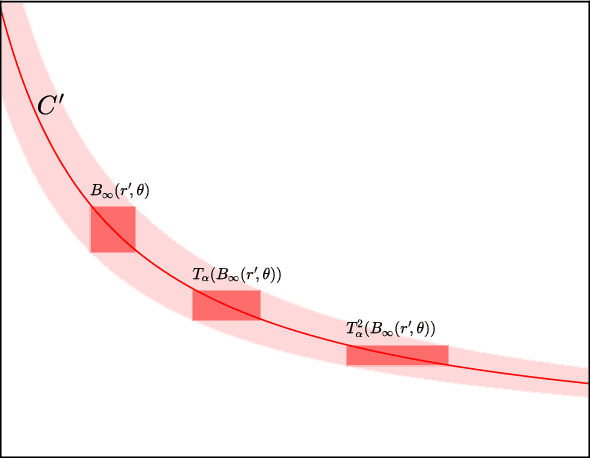
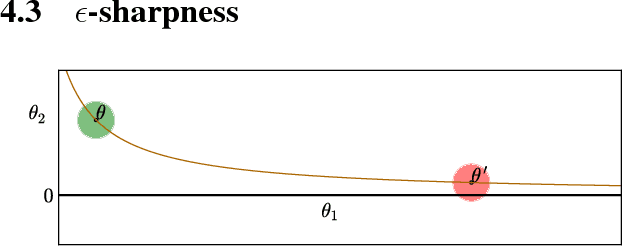
Despite their overwhelming capacity to overfit, deep learning architectures tend to generalize relatively well to unseen data, allowing them to be deployed in practice. However, explaining why this is the case is still an open area of research. One standing hypothesis that is gaining popularity, e.g. Hochreiter & Schmidhuber (1997); Keskar et al. (2017), is that the flatness of minima of the loss function found by stochastic gradient based methods results in good generalization. This paper argues that most notions of flatness are problematic for deep models and can not be directly applied to explain generalization. Specifically, when focusing on deep networks with rectifier units, we can exploit the particular geometry of parameter space induced by the inherent symmetries that these architectures exhibit to build equivalent models corresponding to arbitrarily sharper minima. Furthermore, if we allow to reparametrize a function, the geometry of its parameters can change drastically without affecting its generalization properties.
Density estimation using Real NVP
Feb 27, 2017
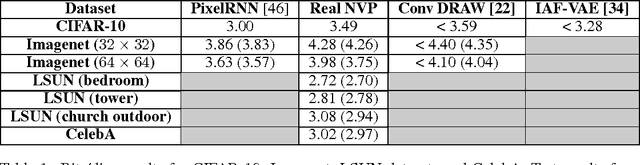


Unsupervised learning of probabilistic models is a central yet challenging problem in machine learning. Specifically, designing models with tractable learning, sampling, inference and evaluation is crucial in solving this task. We extend the space of such models using real-valued non-volume preserving (real NVP) transformations, a set of powerful invertible and learnable transformations, resulting in an unsupervised learning algorithm with exact log-likelihood computation, exact sampling, exact inference of latent variables, and an interpretable latent space. We demonstrate its ability to model natural images on four datasets through sampling, log-likelihood evaluation and latent variable manipulations.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
A Recurrent Latent Variable Model for Sequential Data
Apr 06, 2016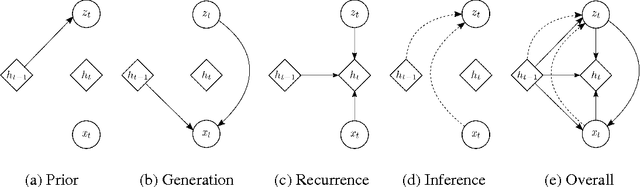
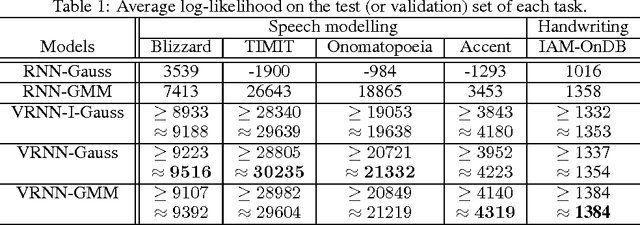

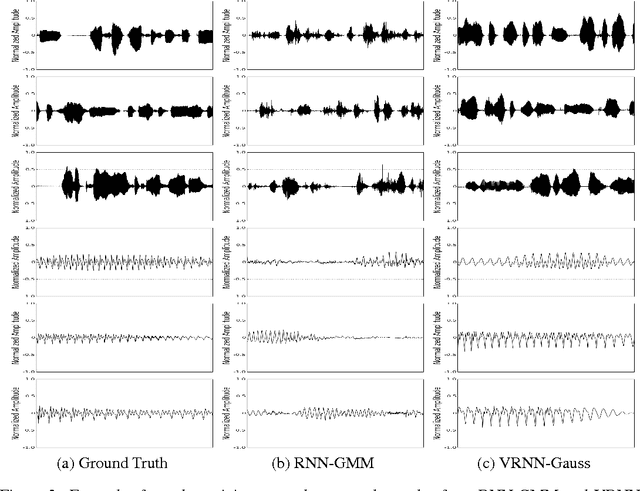
In this paper, we explore the inclusion of latent random variables into the dynamic hidden state of a recurrent neural network (RNN) by combining elements of the variational autoencoder. We argue that through the use of high-level latent random variables, the variational RNN (VRNN)1 can model the kind of variability observed in highly structured sequential data such as natural speech. We empirically evaluate the proposed model against related sequential models on four speech datasets and one handwriting dataset. Our results show the important roles that latent random variables can play in the RNN dynamic hidden state.
NICE: Non-linear Independent Components Estimation
Apr 10, 2015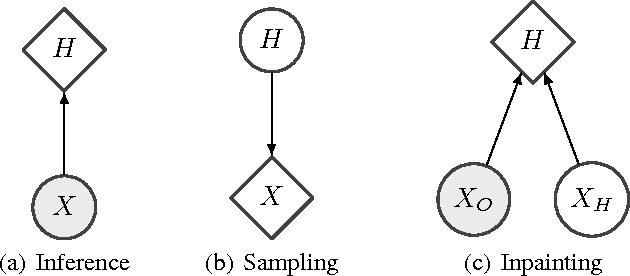


We propose a deep learning framework for modeling complex high-dimensional densities called Non-linear Independent Component Estimation (NICE). It is based on the idea that a good representation is one in which the data has a distribution that is easy to model. For this purpose, a non-linear deterministic transformation of the data is learned that maps it to a latent space so as to make the transformed data conform to a factorized distribution, i.e., resulting in independent latent variables. We parametrize this transformation so that computing the Jacobian determinant and inverse transform is trivial, yet we maintain the ability to learn complex non-linear transformations, via a composition of simple building blocks, each based on a deep neural network. The training criterion is simply the exact log-likelihood, which is tractable. Unbiased ancestral sampling is also easy. We show that this approach yields good generative models on four image datasets and can be used for inpainting.
Techniques for Learning Binary Stochastic Feedforward Neural Networks
Apr 09, 2015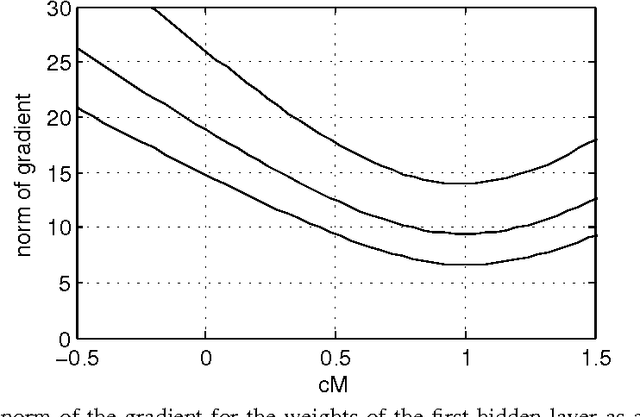
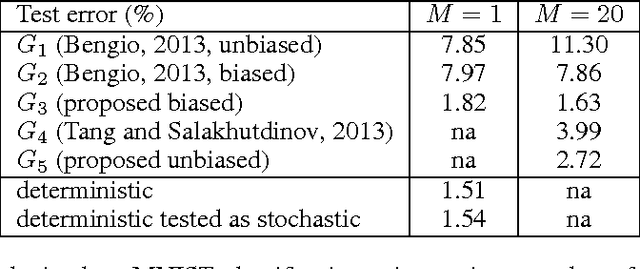
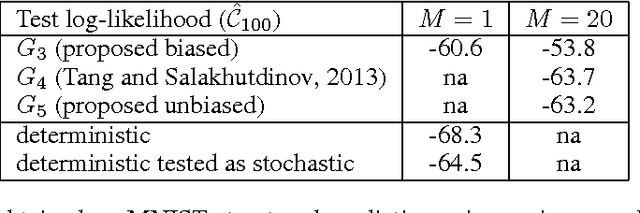
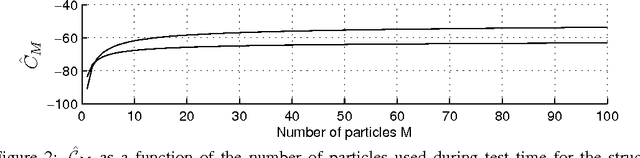
Stochastic binary hidden units in a multi-layer perceptron (MLP) network give at least three potential benefits when compared to deterministic MLP networks. (1) They allow to learn one-to-many type of mappings. (2) They can be used in structured prediction problems, where modeling the internal structure of the output is important. (3) Stochasticity has been shown to be an excellent regularizer, which makes generalization performance potentially better in general. However, training stochastic networks is considerably more difficult. We study training using M samples of hidden activations per input. We show that the case M=1 leads to a fundamentally different behavior where the network tries to avoid stochasticity. We propose two new estimators for the training gradient and propose benchmark tests for comparing training algorithms. Our experiments confirm that training stochastic networks is difficult and show that the proposed two estimators perform favorably among all the five known estimators.
Predicting Parameters in Deep Learning
Oct 27, 2014

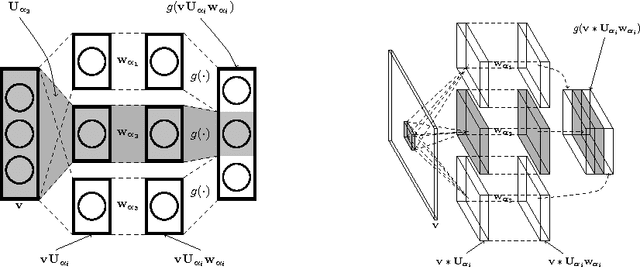
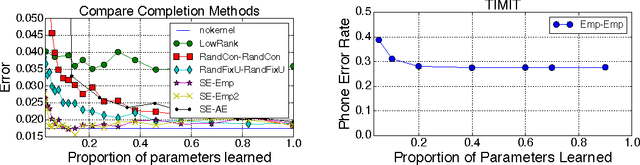
We demonstrate that there is significant redundancy in the parameterization of several deep learning models. Given only a few weight values for each feature it is possible to accurately predict the remaining values. Moreover, we show that not only can the parameter values be predicted, but many of them need not be learned at all. We train several different architectures by learning only a small number of weights and predicting the rest. In the best case we are able to predict more than 95% of the weights of a network without any drop in accuracy.