 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAST: A Dual-Stream Voice Anonymization Attacker with Staged Training
Mar 16, 2026Voice anonymization masks vocal traits while preserving linguistic content, which may still leak speaker-specific patterns. To assess and strengthen privacy evaluation, we propose a dual-stream attacker that fuses spectral and self-supervised learning features via parallel encoders with a three-stage training strategy. Stage I establishes foundational speaker-discriminative representations. Stage II leverages the shared identity-transformation characteristics of voice conversion and anonymization, exposing the model to diverse converted speech to build cross-system robustness. Stage III provides lightweight adaptation to target anonymized data. Results on the VoicePrivacy Attacker Challenge (VPAC) dataset demonstrate that Stage II is the primary driver of generalization, enabling strong attacking performance on unseen anonymization datasets. With Stage III, fine-tuning on only 10\% of the target anonymization dataset surpasses current state-of-the-art attackers in terms of EER.
SegReConcat: A Data Augmentation Method for Voice Anonymization Attack
Aug 26, 2025Anonymization of voice seeks to conceal the identity of the speaker while maintaining the utility of speech data. However, residual speaker cues often persist, which pose privacy risks. We propose SegReConcat, a data augmentation method for attacker-side enhancement of automatic speaker verification systems. SegReConcat segments anonymized speech at the word level, rearranges segments using random or similarity-based strategies to disrupt long-term contextual cues, and concatenates them with the original utterance, allowing an attacker to learn source speaker traits from multiple perspectives. The proposed method has been evaluated in the VoicePrivacy Attacker Challenge 2024 framework across seven anonymization systems, SegReConcat improves de-anonymization on five out of seven systems.
Automated evaluation of children's speech fluency for low-resource languages
May 26, 2025Assessment of children's speaking fluency in education is well researched for majority languages, but remains highly challenging for low resource languages. This paper proposes a system to automatically assess fluency by combining a fine-tuned multilingual ASR model, an objective metrics extraction stage, and a generative pre-trained transformer (GPT) network. The objective metrics include phonetic and word error rates, speech rate, and speech-pause duration ratio. These are interpreted by a GPT-based classifier guided by a small set of human-evaluated ground truth examples, to score fluency. We evaluate the proposed system on a dataset of children's speech in two low-resource languages, Tamil and Malay and compare the classification performance against Random Forest and XGBoost, as well as using ChatGPT-4o to predict fluency directly from speech input. Results demonstrate that the proposed approach achieves significantly higher accuracy than multimodal GPT or other methods.
Consistency Guided Knowledge Retrieval and Denoising in LLMs for Zero-shot Document-level Relation Triplet Extraction
Jan 24, 2024



Document-level Relation Triplet Extraction (DocRTE) is a fundamental task in information systems that aims to simultaneously extract entities with semantic relations from a document. Existing methods heavily rely on a substantial amount of fully labeled data. However, collecting and annotating data for newly emerging relations is time-consuming and labor-intensive. Recent advanced Large Language Models (LLMs), such as ChatGPT and LLaMA, exhibit impressive long-text generation capabilities, inspiring us to explore an alternative approach for obtaining auto-labeled documents with new relations. In this paper, we propose a Zero-shot Document-level Relation Triplet Extraction (ZeroDocRTE) framework, which generates labeled data by retrieval and denoising knowledge from LLMs, called GenRDK. Specifically, we propose a chain-of-retrieval prompt to guide ChatGPT to generate labeled long-text data step by step. To improve the quality of synthetic data, we propose a denoising strategy based on the consistency of cross-document knowledge. Leveraging our denoised synthetic data, we proceed to fine-tune the LLaMA2-13B-Chat for extracting document-level relation triplets. We perform experiments for both zero-shot document-level relation and triplet extraction on two public datasets. The experimental results illustrate that our GenRDK framework outperforms strong baselines.
Pronunciation Modeling of Foreign Words for Mandarin ASR by Considering the Effect of Language Transfer
Oct 07, 2022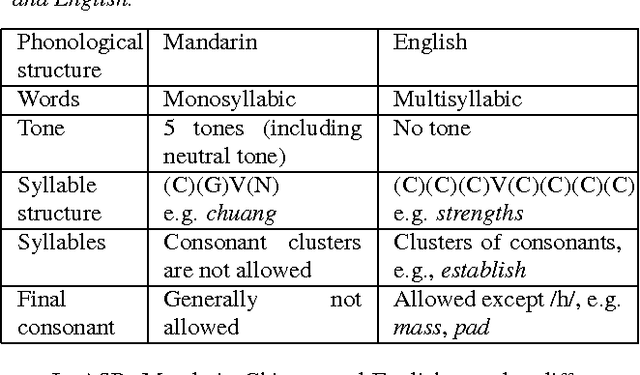
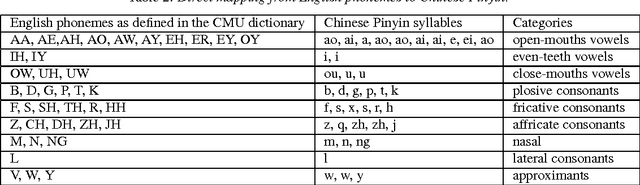

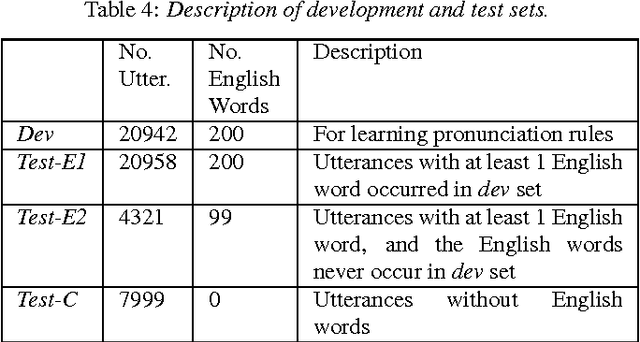
One of the challenges in automatic speech recognition is foreign words recognition. It is observed that a speaker's pronunciation of a foreign word is influenced by his native language knowledge, and such phenomenon is known as the effect of language transfer. This paper focuses on examining the phonetic effect of language transfer in automatic speech recognition. A set of lexical rules is proposed to convert an English word into Mandarin phonetic representation. In this way, a Mandarin lexicon can be augmented by including English words. Hence, the Mandarin ASR system becomes capable to recognize English words without retraining or re-estimation of the acoustic model parameters. Using the lexicon that derived from the proposed rules, the ASR performance of Mandarin English mixed speech is improved without harming the accuracy of Mandarin only speech. The proposed lexical rules are generalized and they can be directly applied to unseen English words.
Cloud-based Automatic Speech Recognition Systems for Southeast Asian Languages
Oct 07, 2022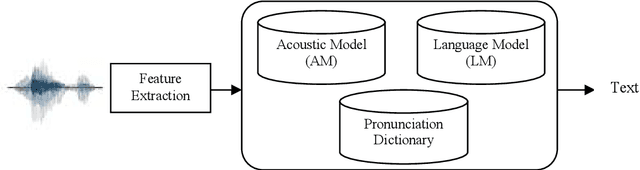
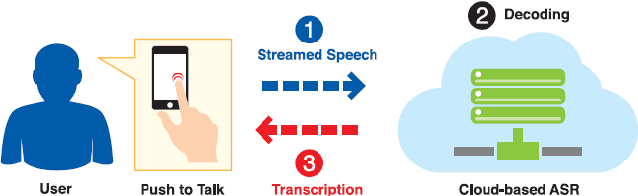
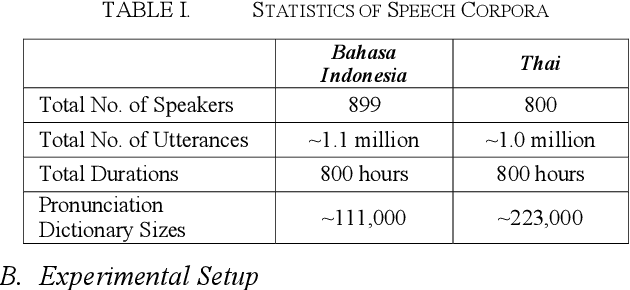

This paper provides an overall introduction of our Automatic Speech Recognition (ASR) systems for Southeast Asian languages. As not much existing work has been carried out on such regional languages, a few difficulties should be addressed before building the systems: limitation on speech and text resources, lack of linguistic knowledge, etc. This work takes Bahasa Indonesia and Thai as examples to illustrate the strategies of collecting various resources required for building ASR systems.