 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Dense Multi-Cable Knots
Jun 04, 2021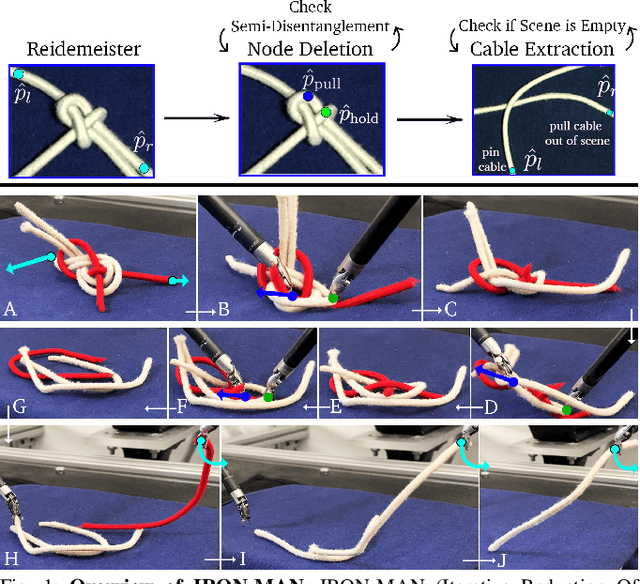
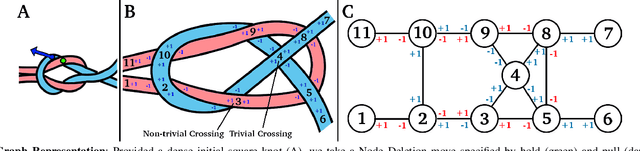
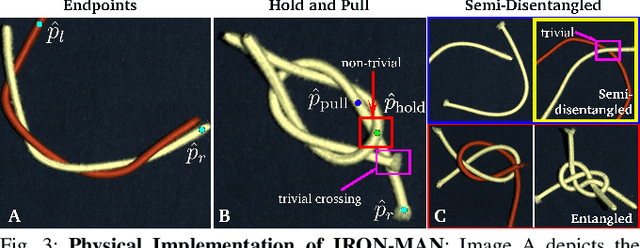

Disentangling two or more cables requires many steps to remove crossings between and within cables. We formalize the problem of disentangling multiple cables and present an algorithm, Iterative Reduction Of Non-planar Multiple cAble kNots (IRON-MAN), that outputs robot actions to remove crossings from multi-cable knotted structures. We instantiate this algorithm with a learned perception system, inspired by prior work in single-cable untying that given an image input, can disentangle two-cable twists, three-cable braids, and knots of two or three cables, such as overhand, square, carrick bend, sheet bend, crown, and fisherman's knots. IRON-MAN keeps track of task-relevant keypoints corresponding to target cable endpoints and crossings and iteratively disentangles the cables by identifying and undoing crossings that are critical to knot structure. Using a da Vinci surgical robot, we experimentally evaluate the effectiveness of IRON-MAN on untangling multi-cable knots of types that appear in the training data, as well as generalizing to novel classes of multi-cable knots. Results suggest that IRON-MAN is effective in disentangling knots involving up to three cables with 80.5% success and generalizing to knot types that are not present during training, with cables of both distinct or identical colors.
Orienting Novel 3D Objects Using Self-Supervised Learning of Rotation Transforms
May 29, 2021
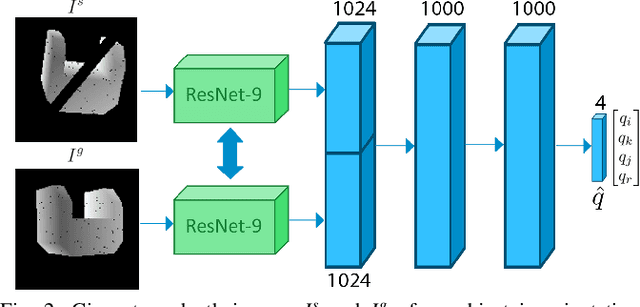
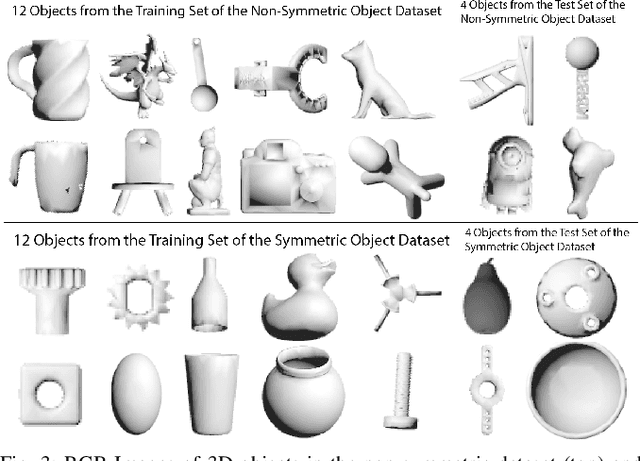
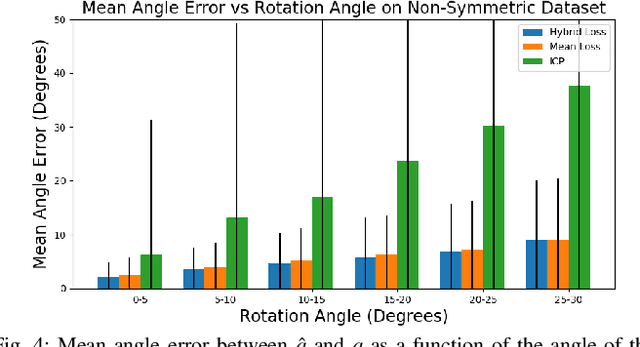
Orienting objects is a critical component in the automation of many packing and assembly tasks. We present an algorithm to orient novel objects given a depth image of the object in its current and desired orientation. We formulate a self-supervised objective for this problem and train a deep neural network to estimate the 3D rotation as parameterized by a quaternion, between these current and desired depth images. We then use the trained network in a proportional controller to re-orient objects based on the estimated rotation between the two depth images. Results suggest that in simulation we can rotate unseen objects with unknown geometries by up to 30{\deg} with a median angle error of 1.47{\deg} over 100 random initial/desired orientations each for 22 novel objects. Experiments on physical objects suggest that the controller can achieve a median angle error of 4.2{\deg} over 10 random initial/desired orientations each for 5 objects.
A Multi-Chamber Smart Suction Cup for Adaptive Gripping and Haptic Exploration
May 05, 2021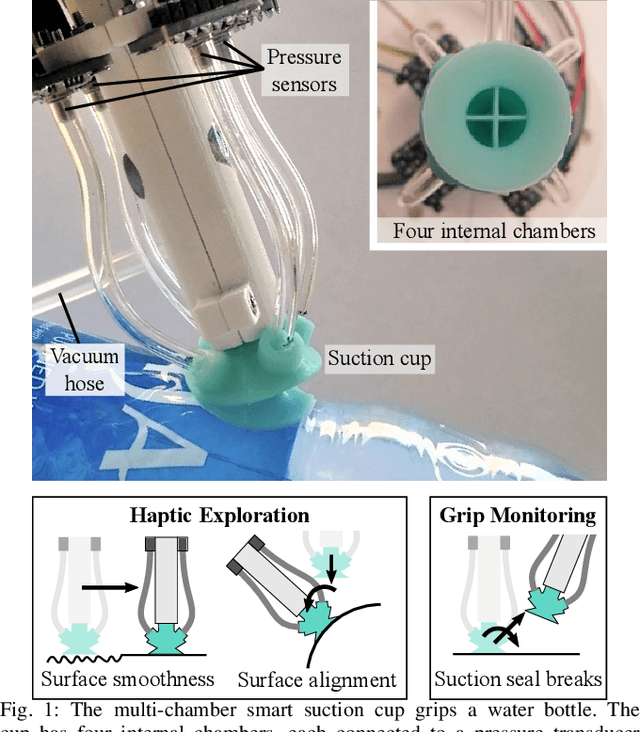
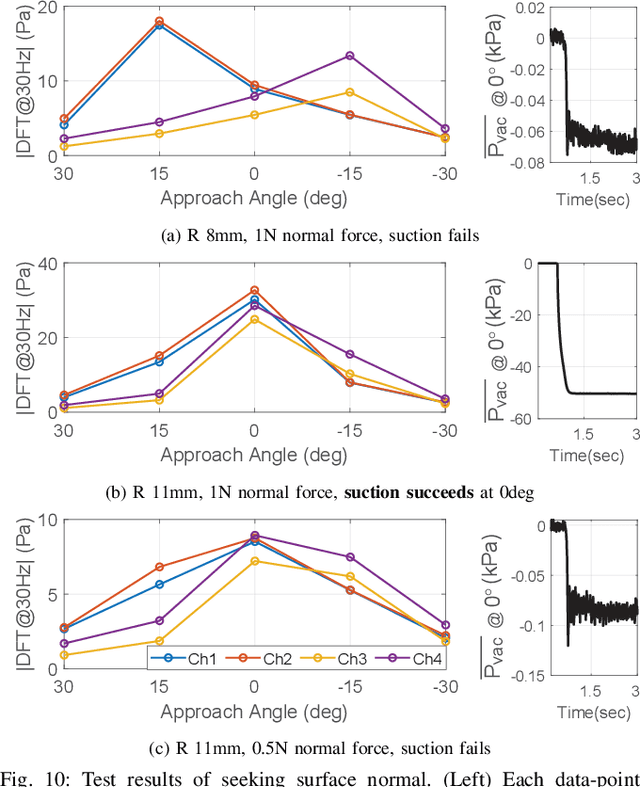
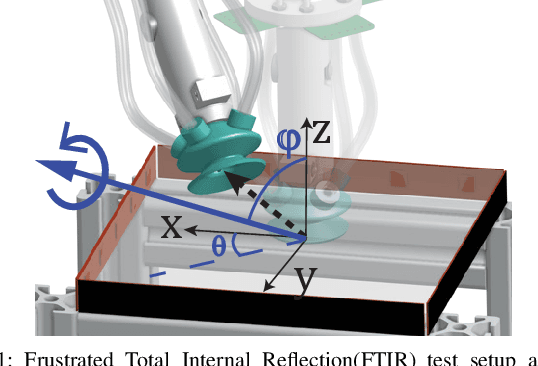
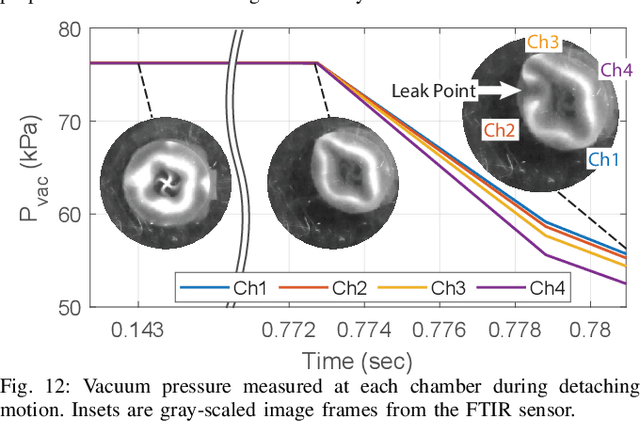
We present a novel robot end-effector for gripping and haptic exploration. Tactile sensing through suction flow monitoring is applied to a new suction cup design that contains multiple chambers for air flow. Each chamber connects with its own remote pressure transducer, which enables both absolute and differential pressure measures between chambers. By changing the overall vacuum applied to this smart suction cup, it can perform different functions such as gentle haptic exploration (low pressure) and monitoring breaks in the seal during strong astrictive gripping (high pressure). Haptic exploration of surfaces through sliding and palpation can guide the selection of suction grasp locations and help to identify the local surface geometry. During suction gripping, this design localizes breaks in the suction seal between four quadrants with up to 97% accuracy and detects breaks in the suction seal early enough to avoid total grasp failure.
LazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Mar 31, 2021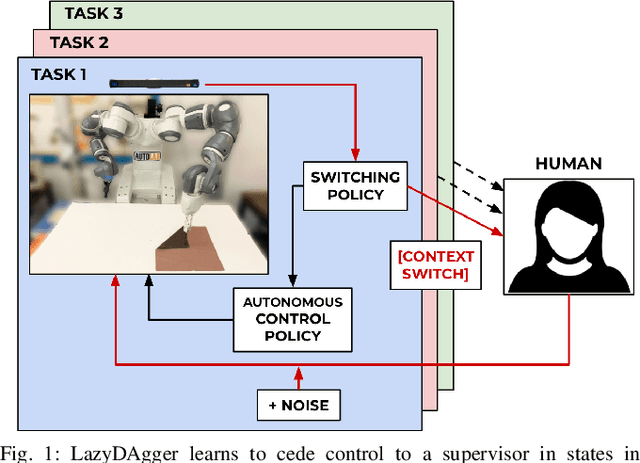
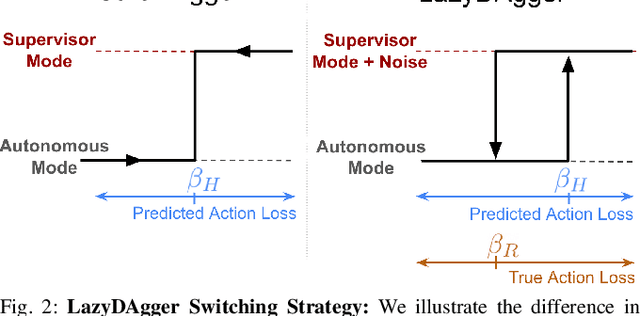
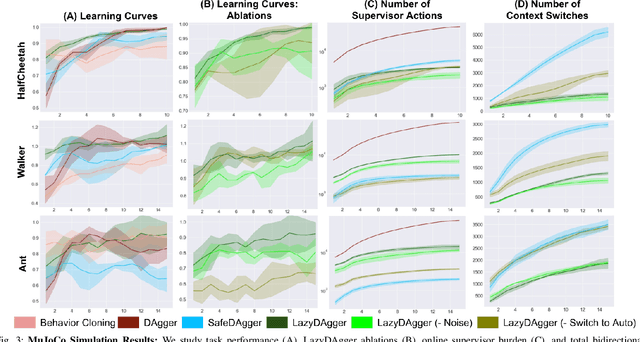
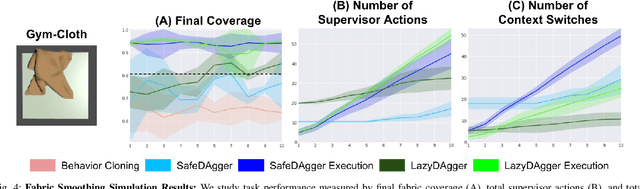
Corrective interventions while a robot is learning to automate a task provide an intuitive method for a human supervisor to assist the robot and convey information about desired behavior. However, these interventions can impose significant burden on a human supervisor, as each intervention interrupts other work the human is doing, incurs latency with each context switch between supervisor and autonomous control, and requires time to perform. We present LazyDAgger, which extends the interactive imitation learning (IL) algorithm SafeDAgger to reduce context switches between supervisor and autonomous control. We find that LazyDAgger improves the performance and robustness of the learned policy during both learning and execution while limiting burden on the supervisor. Simulation experiments suggest that LazyDAgger can reduce context switches by an average of 60% over SafeDAgger on 3 continuous control tasks while maintaining state-of-the-art policy performance. In physical fabric manipulation experiments with an ABB YuMi robot, LazyDAgger reduces context switches by 60% while achieving a 60% higher success rate than SafeDAgger at execution time.
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Feb 19, 2021
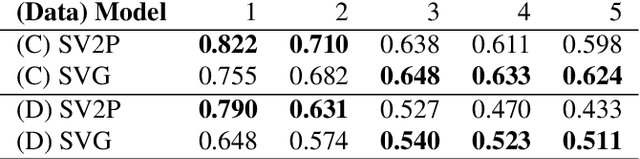
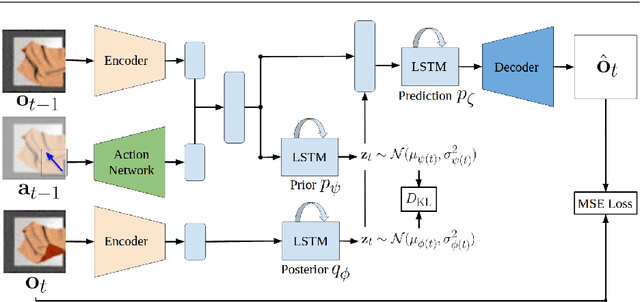
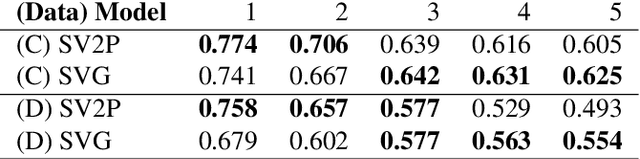
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, the choice of visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability. Code, data, videos, and supplementary material are available at https://sites.google.com/view/fabric-vsf/.
Superhuman Surgical Peg Transfer Using Depth-Sensing and Deep Recurrent Neural Networks
Dec 24, 2020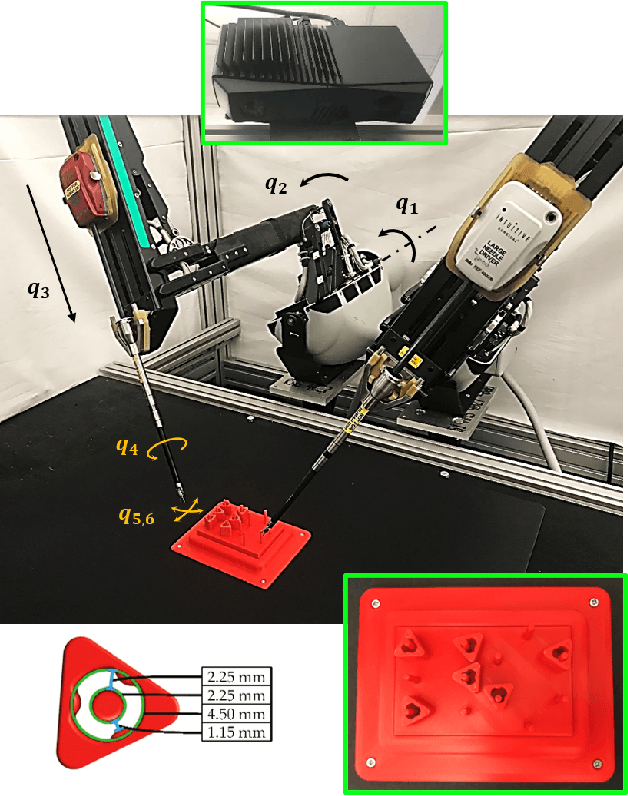
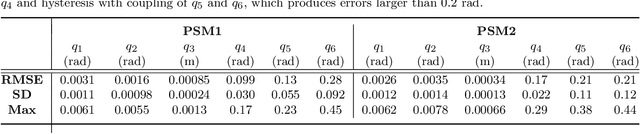
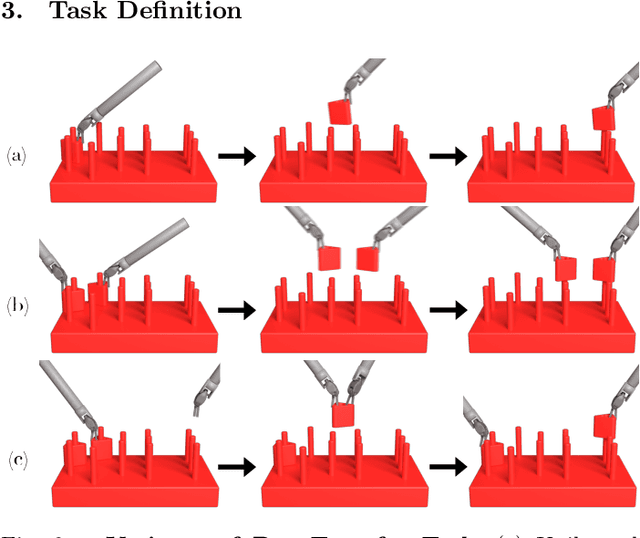
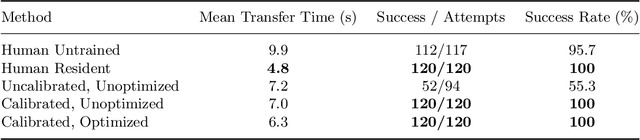
We consider the automation of the well-known peg-transfer task from the Fundamentals of Laparoscopic Surgery (FLS). While human surgeons teleoperate robots to perform this task with great dexterity, it remains challenging to automate. We present an approach that leverages emerging innovations in depth sensing, deep learning, and Peiper's method for computing inverse kinematics with time-minimized joint motion. We use the da Vinci Research Kit (dVRK) surgical robot with a Zivid depth sensor, and automate three variants of the peg-transfer task: unilateral, bilateral without handovers, and bilateral with handovers. We use 3D-printed fiducial markers with depth sensing and a deep recurrent neural network to improve the precision of the dVRK to less than 1 mm. We report experimental results for 1800 block transfer trials. Results suggest that the fully automated system can outperform an experienced human surgical resident, who performs far better than untrained humans, in terms of both speed and success rate. For the most difficult variant of peg transfer (with handovers) we compare the performance of the surgical resident with performance of the automated system over 120 trials for each. The experienced surgical resident achieves success rate 93.2 % with mean transfer time of 8.6 seconds. The automated system achieves success rate 94.1 % with mean transfer time of 8.1 seconds. To our knowledge this is the first fully automated system to achieve "superhuman" performance in both speed and success on peg transfer. Supplementary material is available at https://sites.google.com/view/surgicalpegtransfer.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020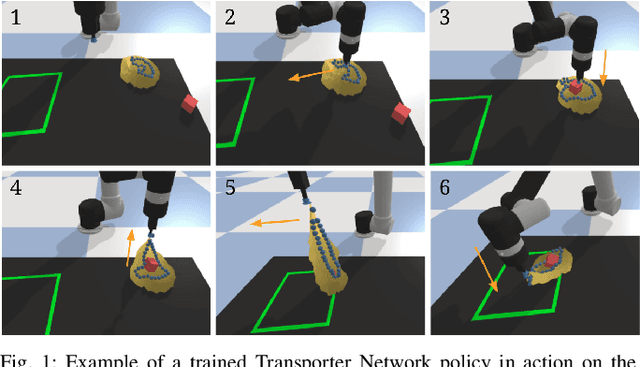
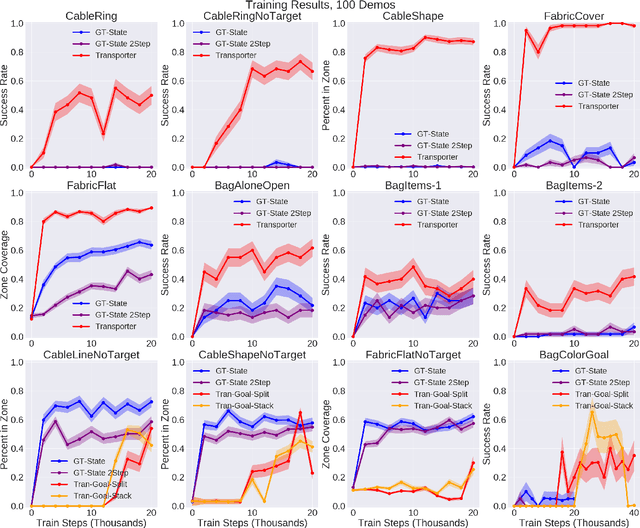
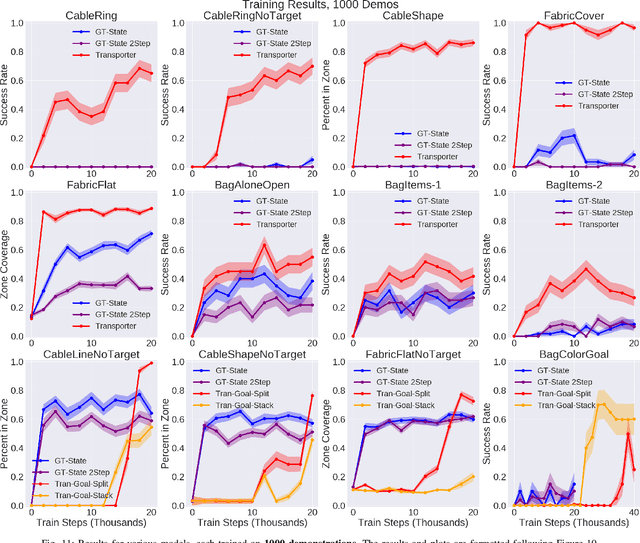
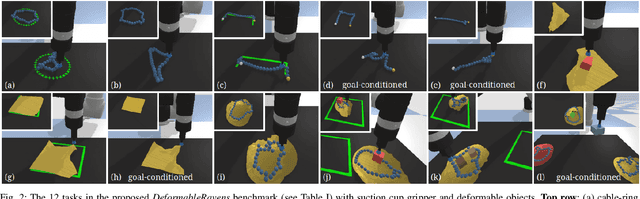
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
Semantic and Geometric Modeling with Neural Message Passing in 3D Scene Graphs for Hierarchical Mechanical Search
Dec 07, 2020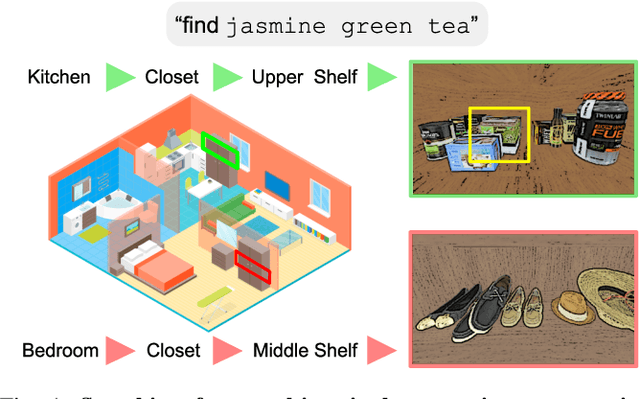
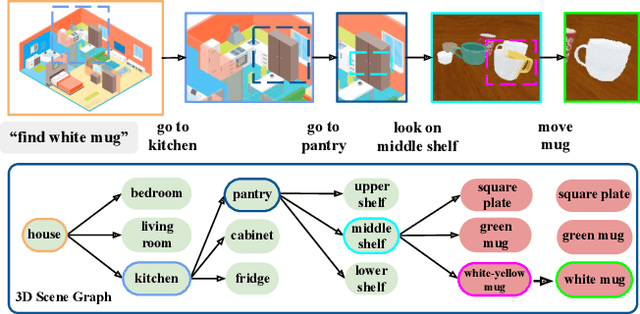
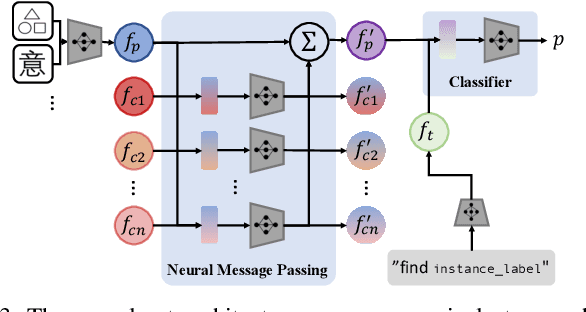
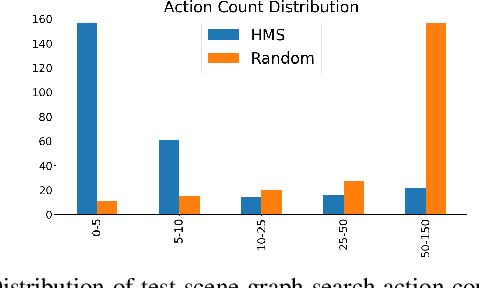
Searching for objects in indoor organized environments such as homes or offices is part of our everyday activities. When looking for a target object, we jointly reason about the rooms and containers the object is likely to be in; the same type of container will have a different probability of having the target depending on the room it is in. We also combine geometric and semantic information to infer what container is best to search, or what other objects are best to move, if the target object is hidden from view. We propose to use a 3D scene graph representation to capture the hierarchical, semantic, and geometric aspects of this problem. To exploit this representation in a search process, we introduce Hierarchical Mechanical Search (HMS), a method that guides an agent's actions towards finding a target object specified with a natural language description. HMS is based on a novel neural network architecture that uses neural message passing of vectors with visual, geometric, and linguistic information to allow HMS to reason across layers of the graph while combining semantic and geometric cues. HMS is evaluated on a novel dataset of 500 3D scene graphs with dense placements of semantically related objects in storage locations, and is shown to be significantly better than several baselines at finding objects and close to the oracle policy in terms of the median number of actions required. Additional qualitative results can be found at https://ai.stanford.edu/mech-search/hms.
Perspectives on Sim2Real Transfer for Robotics: A Summary of the R:SS 2020 Workshop
Dec 07, 2020
This report presents the debates, posters, and discussions of the Sim2Real workshop held in conjunction with the 2020 edition of the "Robotics: Science and System" conference. Twelve leaders of the field took competing debate positions on the definition, viability, and importance of transferring skills from simulation to the real world in the context of robotics problems. The debaters also joined a large panel discussion, answering audience questions and outlining the future of Sim2Real in robotics. Furthermore, we invited extended abstracts to this workshop which are summarized in this report. Based on the workshop, this report concludes with directions for practitioners exploiting this technology and for researchers further exploring open problems in this area.
Mechanical Search on Shelves using Lateral Access X-RAY
Nov 23, 2020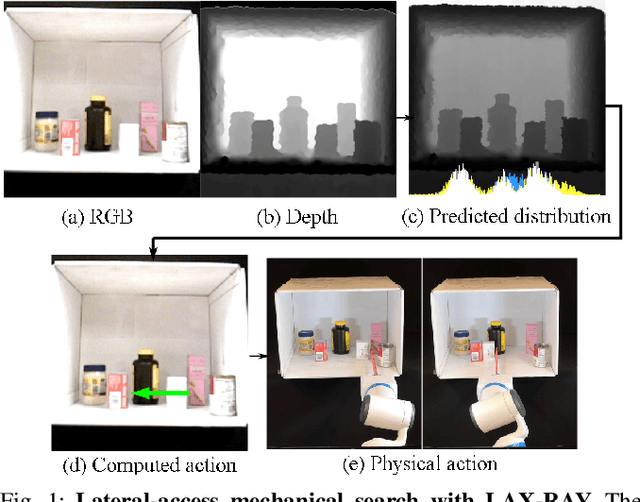



Efficiently finding an occluded object with lateral access arises in many contexts such as warehouses, retail, healthcare, shipping, and homes. We introduce LAX-RAY (Lateral Access maXimal Reduction of occupancY support Area), a system to automate the mechanical search for occluded objects on shelves. For such lateral access environments, LAX-RAY couples a perception pipeline predicting a target object occupancy support distribution with a mechanical search policy that sequentially selects occluding objects to push to the side to reveal the target as efficiently as possible. Within the context of extruded polygonal objects and a stationary target with a known aspect ratio, we explore three lateral access search policies: Distribution Area Reduction (DAR), Distribution Entropy Reduction (DER), and Distribution Entropy Reduction over Multiple Time Steps (DER-MT) utilizing the support distribution and prior information. We evaluate these policies using the First-Order Shelf Simulator (FOSS) in which we simulate 800 random shelf environments of varying difficulty, and in a physical shelf environment with a Fetch robot and an embedded PrimeSense RGBD Camera. Average simulation results of 87.3% success rate demonstrate better performance of DER-MT with 2 prediction steps. When deployed on the robot, results show a success rate of at least 80% for all policies, suggesting that LAX-RAY can efficiently reveal the target object in reality. Both results show significantly better performance of the three proposed policies compared to a baseline policy with uniform probability distribution assumption in non-trivial cases, showing the importance of distribution prediction. Code, videos, and supplementary material can be found at https://sites.google.com/berkeley.edu/lax-ray.