 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayWorld: Learning Robot World Models from Autonomous Play
Mar 11, 2026Action-conditioned video models offer a promising path to building general-purpose robot simulators that can improve directly from data. Yet, despite training on large-scale robot datasets, current state-of-the-art video models still struggle to predict physically consistent robot-object interactions that are crucial in robotic manipulation. To close this gap, we present PlayWorld, a simple, scalable, and fully autonomous pipeline for training high-fidelity video world simulators from interaction experience. In contrast to prior approaches that rely on success-biased human demonstrations, PlayWorld is the first system capable of learning entirely from unsupervised robot self-play, enabling naturally scalable data collection while capturing complex, long-tailed physical interactions essential for modeling realistic object dynamics. Experiments across diverse manipulation tasks show that PlayWorld generates high-quality, physically consistent predictions for contact-rich interactions that are not captured by world models trained on human-collected data. We further demonstrate the versatility of PlayWorld in enabling fine-grained failure prediction and policy evaluation, with up to 40% improvements over human-collected data. Finally, we demonstrate how PlayWorld enables reinforcement learning in the world model, improving policy performance by 65% in success rates when deployed in the real world.
Inference-time Unlearning Using Conformal Prediction
Feb 03, 2026Machine unlearning is the process of efficiently removing specific information from a trained machine learning model without retraining from scratch. Existing unlearning methods, which often provide provable guarantees, typically involve retraining a subset of model parameters based on a forget set. While these approaches show promise in certain scenarios, their underlying assumptions are often challenged in real-world applications -- particularly when applied to generative models. Furthermore, updating parameters using these unlearning procedures often degrades the general-purpose capabilities the model acquired during pre-training. Motivated by these shortcomings, this paper considers the paradigm of inference time unlearning -- wherein, the generative model is equipped with an (approximately correct) verifier that judges whether the model's response satisfies appropriate unlearning guarantees. This paper introduces a framework that iteratively refines the quality of the generated responses using feedback from the verifier without updating the model parameters. The proposed framework leverages conformal prediction to reduce computational overhead and provide distribution-free unlearning guarantees. This paper's approach significantly outperforms existing state-of-the-art methods, reducing unlearning error by up to 93% across challenging unlearning benchmarks.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
DPQ-HD: Post-Training Compression for Ultra-Low Power Hyperdimensional Computing
May 08, 2025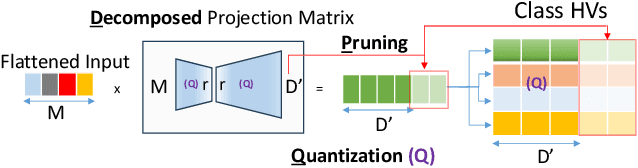

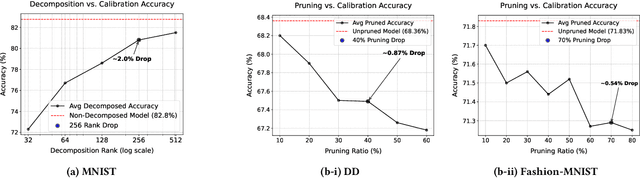
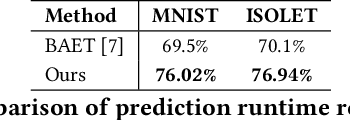
Hyperdimensional Computing (HDC) is emerging as a promising approach for edge AI, offering a balance between accuracy and efficiency. However, current HDC-based applications often rely on high-precision models and/or encoding matrices to achieve competitive performance, which imposes significant computational and memory demands, especially for ultra-low power devices. While recent efforts use techniques like precision reduction and pruning to increase the efficiency, most require retraining to maintain performance, making them expensive and impractical. To address this issue, we propose a novel Post Training Compression algorithm, Decomposition-Pruning-Quantization (DPQ-HD), which aims at compressing the end-to-end HDC system, achieving near floating point performance without the need of retraining. DPQ-HD reduces computational and memory overhead by uniquely combining the above three compression techniques and efficiently adapts to hardware constraints. Additionally, we introduce an energy-efficient inference approach that progressively evaluates similarity scores such as cosine similarity and performs early exit to reduce the computation, accelerating prediction inference while maintaining accuracy. We demonstrate that DPQ-HD achieves up to 20-100x reduction in memory for image and graph classification tasks with only a 1-2% drop in accuracy compared to uncompressed workloads. Lastly, we show that DPQ-HD outperforms the existing post-training compression methods and performs better or at par with retraining-based state-of-the-art techniques, requiring significantly less overall optimization time (up to 100x) and faster inference (up to 56x) on a microcontroller
Material Identification Via RFID For Smart Shopping
Apr 24, 2025Cashierless stores rely on computer vision and RFID tags to associate shoppers with items, but concealed items placed in backpacks, pockets, or bags create challenges for theft prevention. We introduce a system that turns existing RFID tagged items into material sensors by exploiting how different containers attenuate and scatter RF signals. Using RSSI and phase angle, we trained a neural network to classify seven common containers. In a simulated retail environment, the model achieves 89% accuracy with one second samples and 74% accuracy from single reads. Incorporating distance measurements, our system achieves 82% accuracy across 0.3-2m tag to reader separations. When deployed at aisle or doorway choke points, the system can flag suspicious events in real time, prompting camera screening or staff intervention. By combining material identification with computer vision tracking, our system provides proactive loss prevention for cashierless retail while utilizing existing infrastructure.
A Survey of Challenges and Sensing Technologies in Autonomous Retail Systems
Mar 11, 2025Autonomous stores leverage advanced sensing technologies to enable cashier-less shopping, real-time inventory tracking, and seamless customer interactions. However, these systems face significant challenges, including occlusion in vision-based tracking, scalability of sensor deployment, theft prevention, and real-time data processing. To address these issues, researchers have explored multi-modal sensing approaches, integrating computer vision, RFID, weight sensing, vibration-based detection, and LiDAR to enhance accuracy and efficiency. This survey provides a comprehensive review of sensing technologies used in autonomous retail environments, highlighting their strengths, limitations, and integration strategies. We categorize existing solutions across inventory tracking, environmental monitoring, people-tracking, and theft detection, discussing key challenges and emerging trends. Finally, we outline future directions for scalable, cost-efficient, and privacy-conscious autonomous store systems.
Liberal Entity Matching as a Compound AI Toolchain
Jun 17, 2024

Entity matching (EM), the task of identifying whether two descriptions refer to the same entity, is essential in data management. Traditional methods have evolved from rule-based to AI-driven approaches, yet current techniques using large language models (LLMs) often fall short due to their reliance on static knowledge and rigid, predefined prompts. In this paper, we introduce Libem, a compound AI system designed to address these limitations by incorporating a flexible, tool-oriented approach. Libem supports entity matching through dynamic tool use, self-refinement, and optimization, allowing it to adapt and refine its process based on the dataset and performance metrics. Unlike traditional solo-AI EM systems, which often suffer from a lack of modularity that hinders iterative design improvements and system optimization, Libem offers a composable and reusable toolchain. This approach aims to contribute to ongoing discussions and developments in AI-driven data management.
MAF: Multi-Aspect Feedback for Improving Reasoning in Large Language Models
Oct 19, 2023Language Models (LMs) have shown impressive performance in various natural language tasks. However, when it comes to natural language reasoning, LMs still face challenges such as hallucination, generating incorrect intermediate reasoning steps, and making mathematical errors. Recent research has focused on enhancing LMs through self-improvement using feedback. Nevertheless, existing approaches relying on a single generic feedback source fail to address the diverse error types found in LM-generated reasoning chains. In this work, we propose Multi-Aspect Feedback, an iterative refinement framework that integrates multiple feedback modules, including frozen LMs and external tools, each focusing on a specific error category. Our experimental results demonstrate the efficacy of our approach to addressing several errors in the LM-generated reasoning chain and thus improving the overall performance of an LM in several reasoning tasks. We see a relative improvement of up to 20% in Mathematical Reasoning and up to 18% in Logical Entailment.
SK-Net: Deep Learning on Point Cloud via End-to-end Discovery of Spatial Keypoints
Mar 31, 2020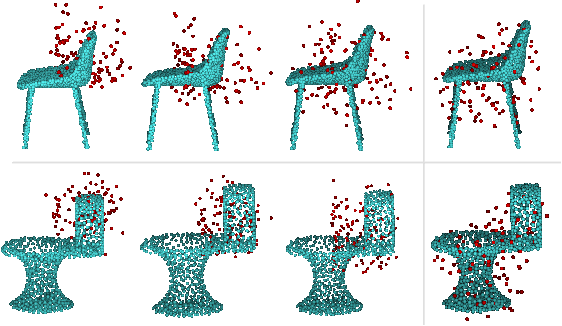
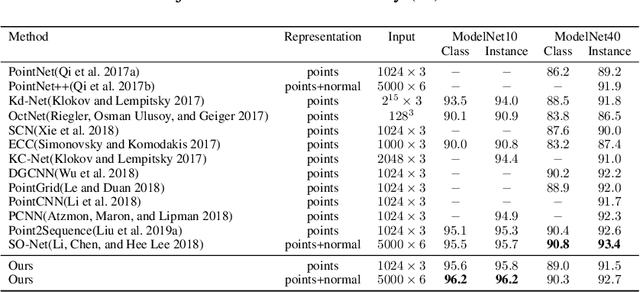
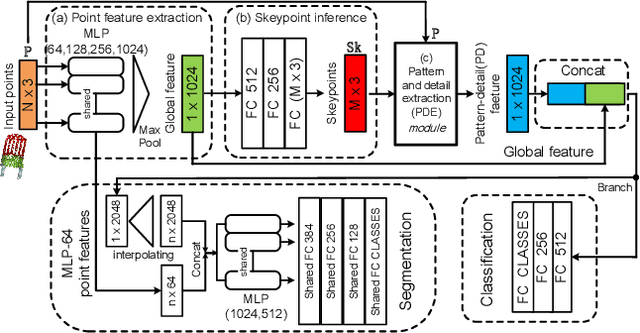

Since the PointNet was proposed, deep learning on point cloud has been the concentration of intense 3D research. However, existing point-based methods usually are not adequate to extract the local features and the spatial pattern of a point cloud for further shape understanding. This paper presents an end-to-end framework, SK-Net, to jointly optimize the inference of spatial keypoint with the learning of feature representation of a point cloud for a specific point cloud task. One key process of SK-Net is the generation of spatial keypoints (Skeypoints). It is jointly conducted by two proposed regulating losses and a task objective function without knowledge of Skeypoint location annotations and proposals. Specifically, our Skeypoints are not sensitive to the location consistency but are acutely aware of shape. Another key process of SK-Net is the extraction of the local structure of Skeypoints (detail feature) and the local spatial pattern of normalized Skeypoints (pattern feature). This process generates a comprehensive representation, pattern-detail (PD) feature, which comprises the local detail information of a point cloud and reveals its spatial pattern through the part district reconstruction on normalized Skeypoints. Consequently, our network is prompted to effectively understand the correlation between different regions of a point cloud and integrate contextual information of the point cloud. In point cloud tasks, such as classification and segmentation, our proposed method performs better than or comparable with the state-of-the-art approaches. We also present an ablation study to demonstrate the advantages of SK-Net.
Efficiently Exploring Ordering Problems through Conflict-directed Search
Apr 15, 2019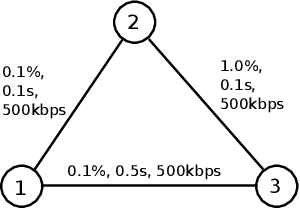
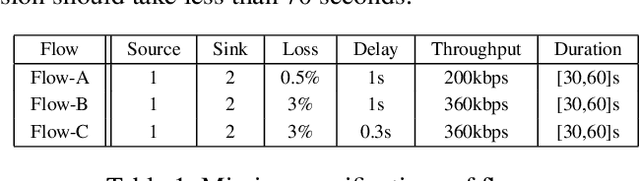
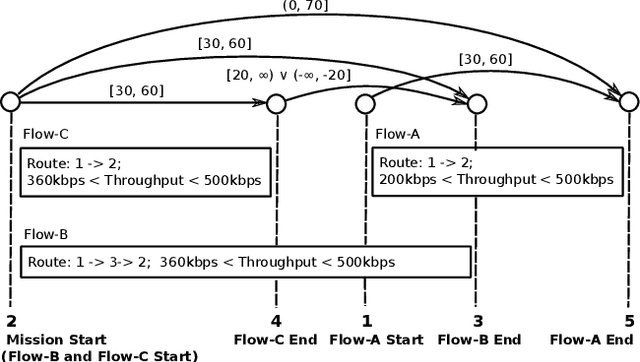
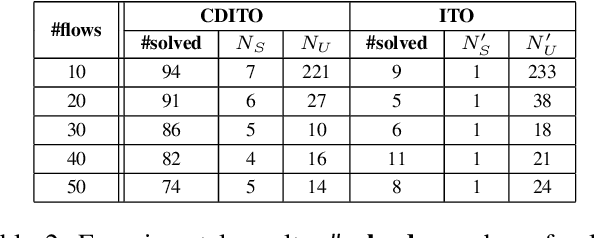
In planning and scheduling, solving problems with both state and temporal constraints is hard since these constraints may be highly coupled. Judicious orderings of events enable solvers to efficiently make decisions over sequences of actions to satisfy complex hybrid specifications. The ordering problem is thus fundamental to planning. Promising recent works have explored the ordering problem as search, incorporating a special tree structure for efficiency. However, such approaches only reason over partial order specifications. Having observed that an ordering is inconsistent with respect to underlying constraints, prior works do not exploit the tree structure to efficiently generate orderings that resolve the inconsistency. In this paper, we present Conflict-directed Incremental Total Ordering (CDITO), a conflict-directed search method to incrementally and systematically generate event total orders given ordering relations and conflicts returned by sub-solvers. Due to its ability to reason over conflicts, CDITO is much more efficient than Incremental Total Ordering. We demonstrate this by benchmarking on temporal network configuration problems that involve routing network flows and allocating bandwidth resources over time.