 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOMP-FIT: Grasp-Optimized Motion Planning for Fast Inertial Transport
Oct 28, 2021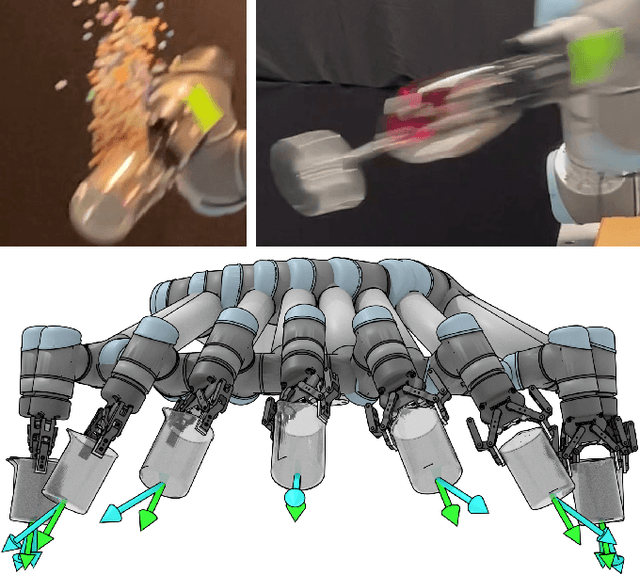
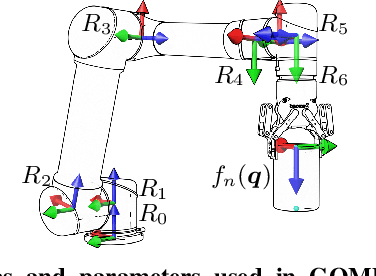


High-speed motions in pick-and-place operations are critical to making robots cost-effective in many automation scenarios, from warehouses and manufacturing to hospitals and homes. However, motions can be too fast -- such as when the object being transported has an open-top, is fragile, or both. One way to avoid spills or damage, is to move the arm slowly. We propose Grasp-Optimized Motion Planning for Fast Inertial Transport (GOMP-FIT), a time-optimizing motion planner based on our prior work, that includes constraints based on accelerations at the robot end-effector. With GOMP-FIT, a robot can perform high-speed motions that avoid obstacles and use inertial forces to its advantage. In experiments transporting open-top containers with varying tilt tolerances, whereas GOMP computes sub-second motions that spill up to 90% of the contents during transport, GOMP-FIT generates motions that spill 0% of contents while being slowed by as little as 0% when there are few obstacles, 30% when there are high obstacles and 45-degree tolerances, and 50% when there 15-degree tolerances and few obstacles.
Dex-NeRF: Using a Neural Radiance Field to Grasp Transparent Objects
Oct 27, 2021



The ability to grasp and manipulate transparent objects is a major challenge for robots. Existing depth cameras have difficulty detecting, localizing, and inferring the geometry of such objects. We propose using neural radiance fields (NeRF) to detect, localize, and infer the geometry of transparent objects with sufficient accuracy to find and grasp them securely. We leverage NeRF's view-independent learned density, place lights to increase specular reflections, and perform a transparency-aware depth-rendering that we feed into the Dex-Net grasp planner. We show how additional lights create specular reflections that improve the quality of the depth map, and test a setup for a robot workcell equipped with an array of cameras to perform transparent object manipulation. We also create synthetic and real datasets of transparent objects in real-world settings, including singulated objects, cluttered tables, and the top rack of a dishwasher. In each setting we show that NeRF and Dex-Net are able to reliably compute robust grasps on transparent objects, achieving 90% and 100% grasp success rates in physical experiments on an ABB YuMi, on objects where baseline methods fail.
ThriftyDAgger: Budget-Aware Novelty and Risk Gating for Interactive Imitation Learning
Sep 17, 2021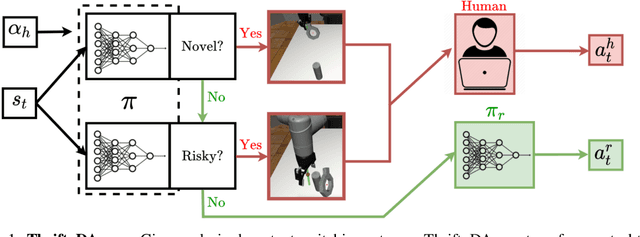
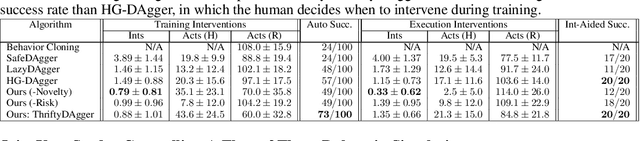
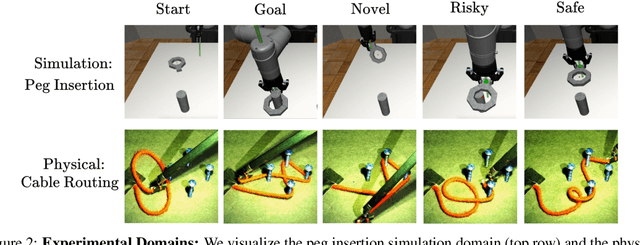

Effective robot learning often requires online human feedback and interventions that can cost significant human time, giving rise to the central challenge in interactive imitation learning: is it possible to control the timing and length of interventions to both facilitate learning and limit burden on the human supervisor? This paper presents ThriftyDAgger, an algorithm for actively querying a human supervisor given a desired budget of human interventions. ThriftyDAgger uses a learned switching policy to solicit interventions only at states that are sufficiently (1) novel, where the robot policy has no reference behavior to imitate, or (2) risky, where the robot has low confidence in task completion. To detect the latter, we introduce a novel metric for estimating risk under the current robot policy. Experiments in simulation and on a physical cable routing experiment suggest that ThriftyDAgger's intervention criteria balances task performance and supervisor burden more effectively than prior algorithms. ThriftyDAgger can also be applied at execution time, where it achieves a 100% success rate on both the simulation and physical tasks. A user study (N=10) in which users control a three-robot fleet while also performing a concentration task suggests that ThriftyDAgger increases human and robot performance by 58% and 80% respectively compared to the next best algorithm while reducing supervisor burden.
FogROS: An Adaptive Framework for Automating Fog Robotics Deployment
Aug 25, 2021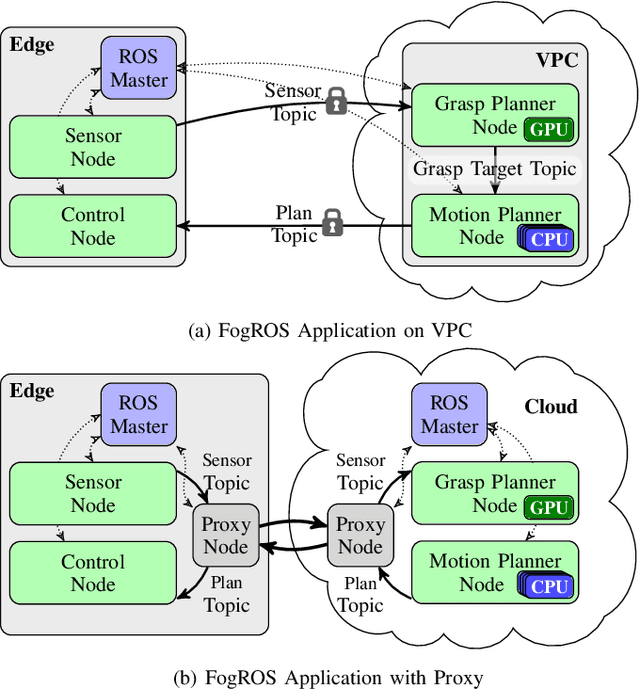
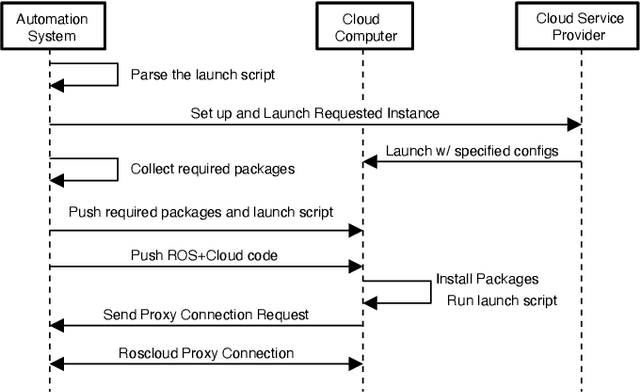
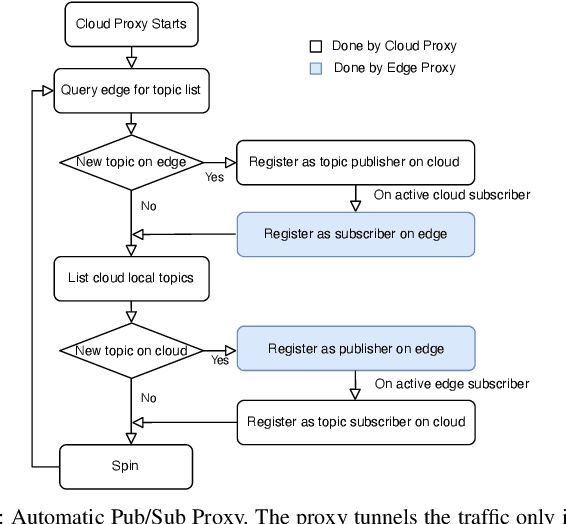
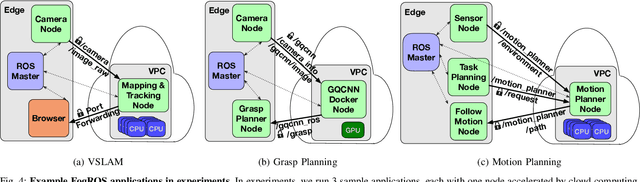
As many robot automation applications increasingly rely on multi-core processing or deep-learning models, cloud computing is becoming an attractive and economically viable resource for systems that do not contain high computing power onboard. Despite its immense computing capacity, it is often underused by the robotics and automation community due to lack of expertise in cloud computing and cloud-based infrastructure. Fog Robotics balances computing and data between cloud edge devices. We propose a software framework, FogROS, as an extension of the Robot Operating System (ROS), the de-facto standard for creating robot automation applications and components. It allows researchers to deploy components of their software to the cloud with minimal effort, and correspondingly gain access to additional computing cores, GPUs, FPGAs, and TPUs, as well as predeployed software made available by other researchers. FogROS allows a researcher to specify which components of their software will be deployed to the cloud and to what type of computing hardware. We evaluate FogROS on 3 examples: (1) simultaneous localization and mapping (ORB-SLAM2), (2) Dexterity Network (Dex-Net) GPU-based grasp planning, and (3) multi-core motion planning using a 96-core cloud-based server. In all three examples, a component is deployed to the cloud and accelerated with a small change in system launch configuration, while incurring additional latency of 1.2 s, 0.6 s, and 0.5 s due to network communication, the computation speed is improved by 2.6x, 6.0x and 34.2x, respectively. Code, videos, and supplementary material can be found at https://github.com/BerkeleyAutomation/FogROS.
Accelerating Quadratic Optimization with Reinforcement Learning
Jul 22, 2021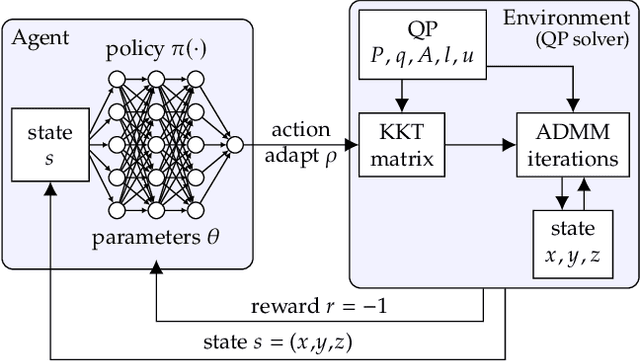
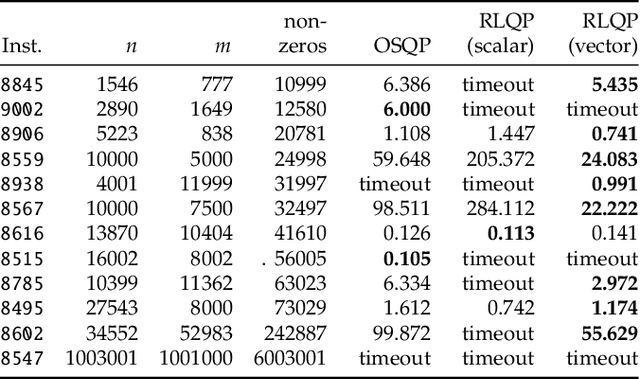
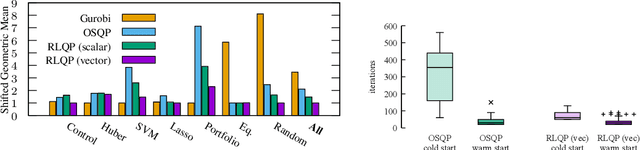
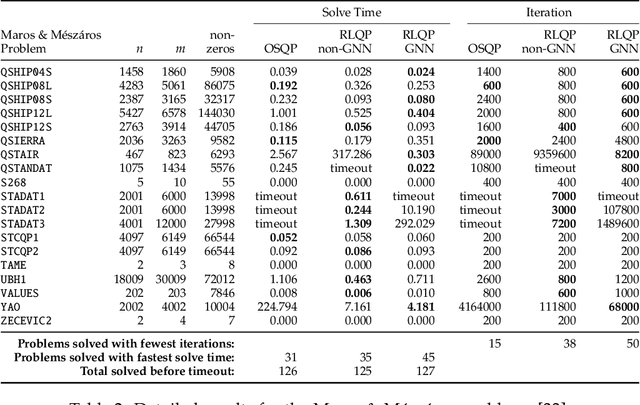
First-order methods for quadratic optimization such as OSQP are widely used for large-scale machine learning and embedded optimal control, where many related problems must be rapidly solved. These methods face two persistent challenges: manual hyperparameter tuning and convergence time to high-accuracy solutions. To address these, we explore how Reinforcement Learning (RL) can learn a policy to tune parameters to accelerate convergence. In experiments with well-known QP benchmarks we find that our RL policy, RLQP, significantly outperforms state-of-the-art QP solvers by up to 3x. RLQP generalizes surprisingly well to previously unseen problems with varying dimension and structure from different applications, including the QPLIB, Netlib LP and Maros-Meszaros problems. Code for RLQP is available at https://github.com/berkeleyautomation/rlqp.
Kit-Net: Self-Supervised Learning to Kit Novel 3D Objects into Novel 3D Cavities
Jul 13, 2021



In industrial part kitting, 3D objects are inserted into cavities for transportation or subsequent assembly. Kitting is a critical step as it can decrease downstream processing and handling times and enable lower storage and shipping costs. We present Kit-Net, a framework for kitting previously unseen 3D objects into cavities given depth images of both the target cavity and an object held by a gripper in an unknown initial orientation. Kit-Net uses self-supervised deep learning and data augmentation to train a convolutional neural network (CNN) to robustly estimate 3D rotations between objects and matching concave or convex cavities using a large training dataset of simulated depth images pairs. Kit-Net then uses the trained CNN to implement a controller to orient and position novel objects for insertion into novel prismatic and conformal 3D cavities. Experiments in simulation suggest that Kit-Net can orient objects to have a 98.9% average intersection volume between the object mesh and that of the target cavity. Physical experiments with industrial objects succeed in 18% of trials using a baseline method and in 63% of trials with Kit-Net. Video, code, and data are available at https://github.com/BerkeleyAutomation/Kit-Net.
LS3: Latent Space Safe Sets for Long-Horizon Visuomotor Control of Iterative Tasks
Jul 10, 2021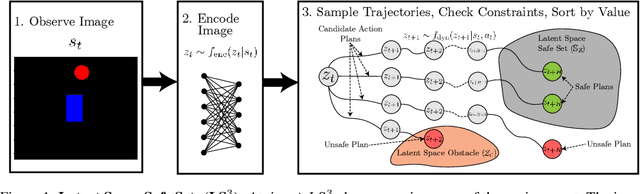
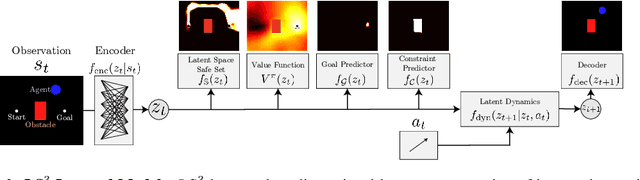


Reinforcement learning (RL) algorithms have shown impressive success in exploring high-dimensional environments to learn complex, long-horizon tasks, but can often exhibit unsafe behaviors and require extensive environment interaction when exploration is unconstrained. A promising strategy for safe learning in dynamically uncertain environments is requiring that the agent can robustly return to states where task success (and therefore safety) can be guaranteed. While this approach has been successful in low-dimensions, enforcing this constraint in environments with high-dimensional state spaces, such as images, is challenging. We present Latent Space Safe Sets (LS3), which extends this strategy to iterative, long-horizon tasks with image observations by using suboptimal demonstrations and a learned dynamics model to restrict exploration to the neighborhood of a learned Safe Set where task completion is likely. We evaluate LS3 on 4 domains, including a challenging sequential pushing task in simulation and a physical cable routing task. We find that LS3 can use prior task successes to restrict exploration and learn more efficiently than prior algorithms while satisfying constraints. See https://tinyurl.com/latent-ss for code and supplementary material.
Untangling Dense Non-Planar Knots by Learning Manipulation Features and Recovery Policies
Jun 29, 2021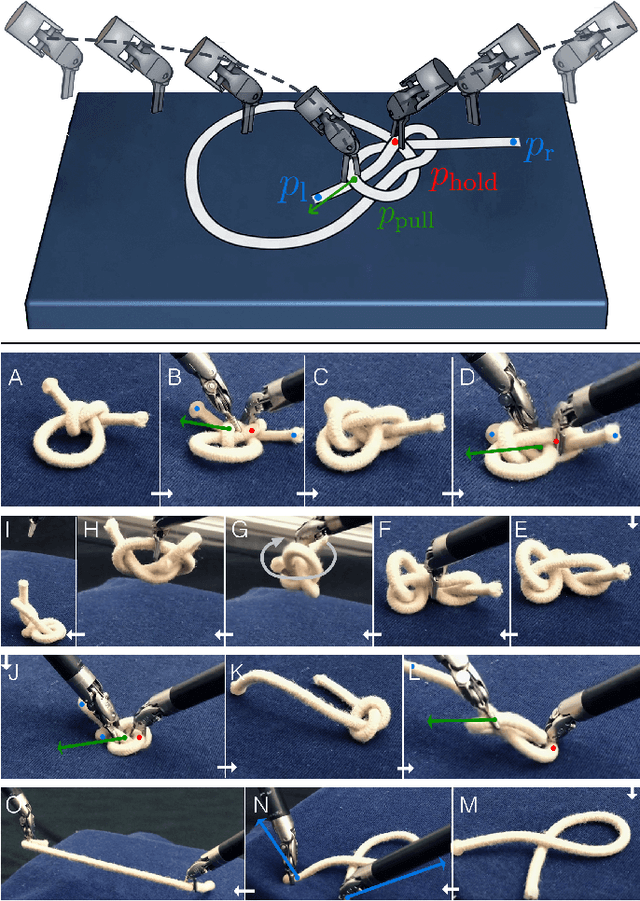
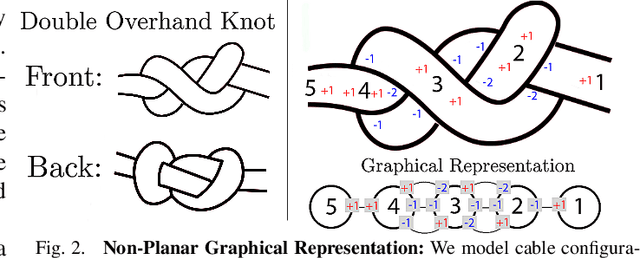
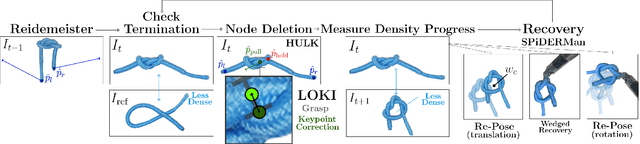
Robot manipulation for untangling 1D deformable structures such as ropes, cables, and wires is challenging due to their infinite dimensional configuration space, complex dynamics, and tendency to self-occlude. Analytical controllers often fail in the presence of dense configurations, due to the difficulty of grasping between adjacent cable segments. We present two algorithms that enhance robust cable untangling, LOKI and SPiDERMan, which operate alongside HULK, a high-level planner from prior work. LOKI uses a learned model of manipulation features to refine a coarse grasp keypoint prediction to a precise, optimized location and orientation, while SPiDERMan uses a learned model to sense task progress and apply recovery actions. We evaluate these algorithms in physical cable untangling experiments with 336 knots and over 1500 actions on real cables using the da Vinci surgical robot. We find that the combination of HULK, LOKI, and SPiDERMan is able to untangle dense overhand, figure-eight, double-overhand, square, bowline, granny, stevedore, and triple-overhand knots. The composition of these methods successfully untangles a cable from a dense initial configuration in 68.3% of 60 physical experiments and achieves 50% higher success rates than baselines from prior work. Supplementary material, code, and videos can be found at https://tinyurl.com/rssuntangling.
Policy Gradient Bayesian Robust Optimization for Imitation Learning
Jun 21, 2021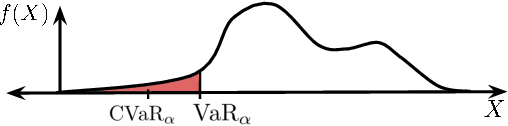
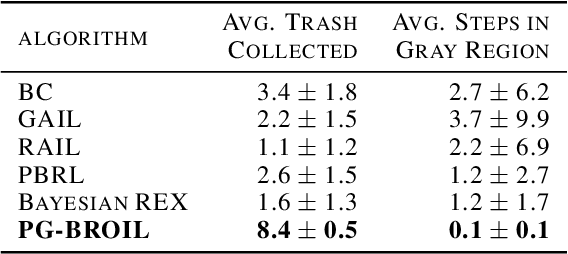
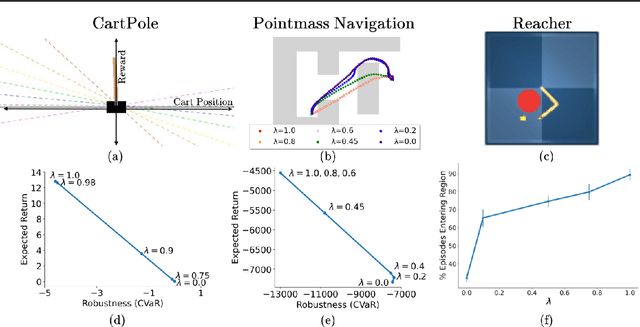
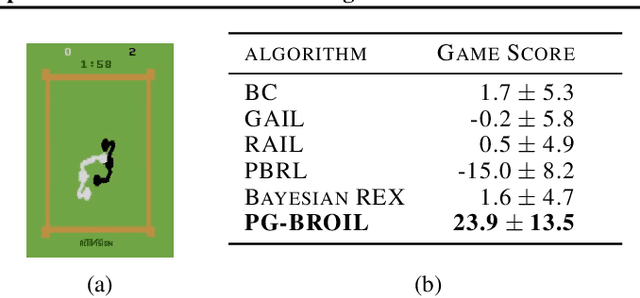
The difficulty in specifying rewards for many real-world problems has led to an increased focus on learning rewards from human feedback, such as demonstrations. However, there are often many different reward functions that explain the human feedback, leaving agents with uncertainty over what the true reward function is. While most policy optimization approaches handle this uncertainty by optimizing for expected performance, many applications demand risk-averse behavior. We derive a novel policy gradient-style robust optimization approach, PG-BROIL, that optimizes a soft-robust objective that balances expected performance and risk. To the best of our knowledge, PG-BROIL is the first policy optimization algorithm robust to a distribution of reward hypotheses which can scale to continuous MDPs. Results suggest that PG-BROIL can produce a family of behaviors ranging from risk-neutral to risk-averse and outperforms state-of-the-art imitation learning algorithms when learning from ambiguous demonstrations by hedging against uncertainty, rather than seeking to uniquely identify the demonstrator's reward function.
PAC Best Arm Identification Under a Deadline
Jun 08, 2021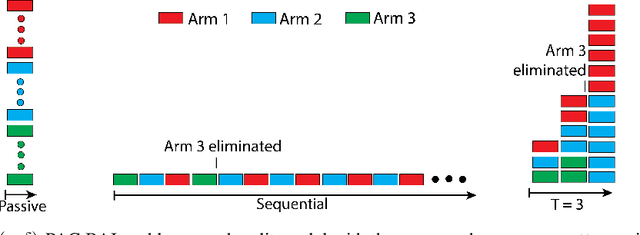
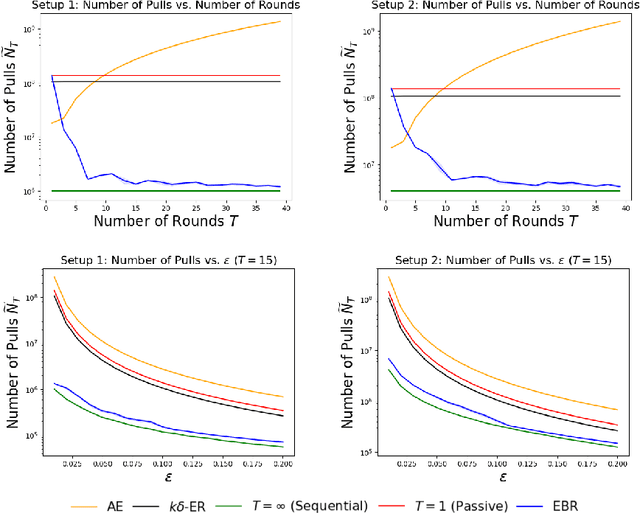
We study $(\epsilon, \delta)$-PAC best arm identification, where a decision-maker must identify an $\epsilon$-optimal arm with probability at least $1 - \delta$, while minimizing the number of arm pulls (samples). Most of the work on this topic is in the sequential setting, where there is no constraint on the time taken to identify such an arm; this allows the decision-maker to pull one arm at a time. In this work, the decision-maker is given a deadline of $T$ rounds, where, on each round, it can adaptively choose which arms to pull and how many times to pull them; this distinguishes the number of decisions made (i.e., time or number of rounds) from the number of samples acquired (cost). Such situations occur in clinical trials, where one may need to identify a promising treatment under a deadline while minimizing the number of test subjects, or in simulation-based studies run on the cloud, where we can elastically scale up or down the number of virtual machines to conduct as many experiments as we wish, but need to pay for the resource-time used. As the decision-maker can only make $T$ decisions, she may need to pull some arms excessively relative to a sequential algorithm in order to perform well on all possible problems. We formalize this added difficulty with two hardness results that indicate that unlike sequential settings, the ability to adapt to the problem difficulty is constrained by the finite deadline. We propose Elastic Batch Racing (EBR), a novel algorithm for this setting and bound its sample complexity, showing that EBR is optimal with respect to both hardness results. We present simulations evaluating EBR in this setting, where it outperforms baselines by several orders of magnitude.