 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Improving Few-Shot Change Detection Visual Question Answering via Decision-Ambiguity-guided Reinforcement Fine-Tuning
Dec 31, 2025Change detection visual question answering (CDVQA) requires answering text queries by reasoning about semantic changes in bi-temporal remote sensing images. A straightforward approach is to boost CDVQA performance with generic vision-language models via supervised fine-tuning (SFT). Despite recent progress, we observe that a significant portion of failures do not stem from clearly incorrect predictions, but from decision ambiguity, where the model assigns similar confidence to the correct answer and strong distractors. To formalize this challenge, we define Decision-Ambiguous Samples (DAS) as instances with a small probability margin between the ground-truth answer and the most competitive alternative. We argue that explicitly optimizing DAS is crucial for improving the discriminability and robustness of CDVQA models. To this end, we propose DARFT, a Decision-Ambiguity-guided Reinforcement Fine-Tuning framework that first mines DAS using an SFT-trained reference policy and then applies group-relative policy optimization on the mined subset. By leveraging multi-sample decoding and intra-group relative advantages, DARFT suppresses strong distractors and sharpens decision boundaries without additional supervision. Extensive experiments demonstrate consistent gains over SFT baselines, particularly under few-shot settings.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
A Dual-Branch Local-Global Framework for Cross-Resolution Land Cover Mapping
Dec 23, 2025Cross-resolution land cover mapping aims to produce high-resolution semantic predictions from coarse or low-resolution supervision, yet the severe resolution mismatch makes effective learning highly challenging. Existing weakly supervised approaches often struggle to align fine-grained spatial structures with coarse labels, leading to noisy supervision and degraded mapping accuracy. To tackle this problem, we propose DDTM, a dual-branch weakly supervised framework that explicitly decouples local semantic refinement from global contextual reasoning. Specifically, DDTM introduces a diffusion-based branch to progressively refine fine-scale local semantics under coarse supervision, while a transformer-based branch enforces long-range contextual consistency across large spatial extents. In addition, we design a pseudo-label confidence evaluation module to mitigate noise induced by cross-resolution inconsistencies and to selectively exploit reliable supervisory signals. Extensive experiments demonstrate that DDTM establishes a new state-of-the-art on the Chesapeake Bay benchmark, achieving 66.52\% mIoU and substantially outperforming prior weakly supervised methods. The code is available at https://github.com/gpgpgp123/DDTM.
CrashChat: A Multimodal Large Language Model for Multitask Traffic Crash Video Analysis
Dec 21, 2025
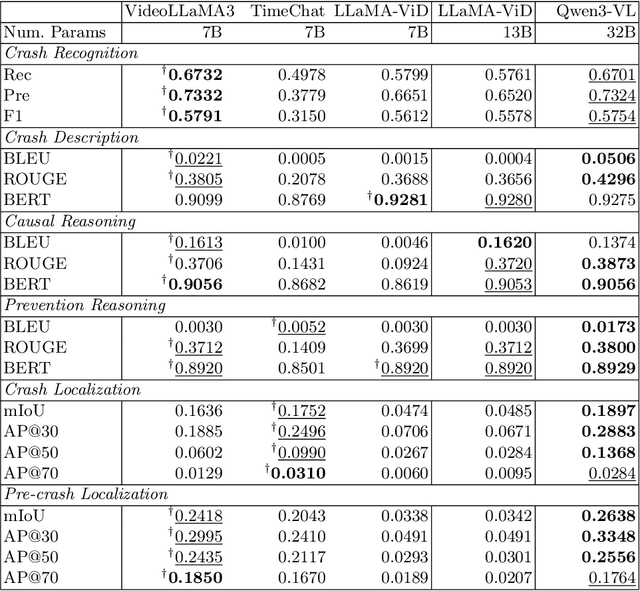
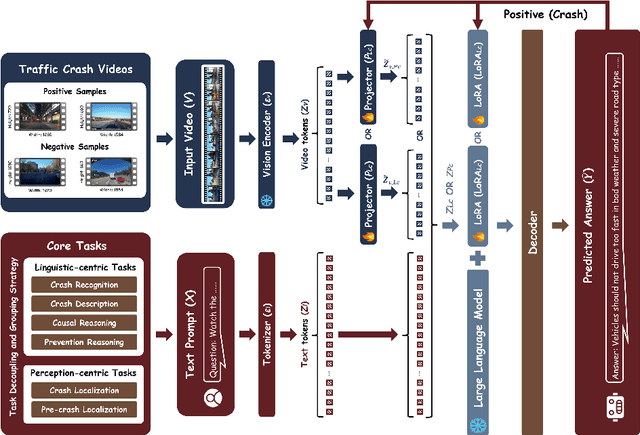
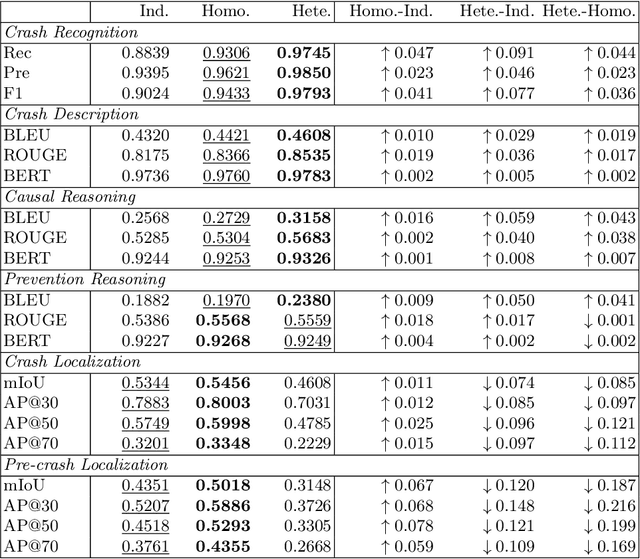
Automating crash video analysis is essential to leverage the growing availability of driving video data for traffic safety research and accountability attribution in autonomous driving. Crash video analysis is a challenging multitask problem due to the complex spatiotemporal dynamics of crash events in video data and the diverse analytical requirements involved. It requires capabilities spanning crash recognition, temporal grounding, and high-level video understanding. Existing models, however, cannot perform all these tasks within a unified framework, and effective training strategies for such models remain underexplored. To fill these gaps, this paper proposes CrashChat, a multimodal large language model (MLLM) for multitask traffic crash analysis, built upon VideoLLaMA3. CrashChat acquires domain-specific knowledge through instruction fine-tuning and employs a novel multitask learning strategy based on task decoupling and grouping, which maximizes the benefit of joint learning within and across task groups while mitigating negative transfer. Numerical experiments on consolidated public datasets demonstrate that CrashChat consistently outperforms existing MLLMs across model scales and traditional vision-based methods, achieving state-of-the-art performance. It reaches near-perfect accuracy in crash recognition, a 176\% improvement in crash localization, and a 40\% improvement in the more challenging pre-crash localization. Compared to general MLLMs, it substantially enhances textual accuracy and content coverage in crash description and reasoning tasks, with 0.18-0.41 increases in BLEU scores and 0.18-0.42 increases in ROUGE scores. Beyond its strong performance, CrashChat is a convenient, end-to-end analytical tool ready for practical implementation. The dataset and implementation code for CrashChat are available at https://github.com/Liangkd/CrashChat.
Routing-Led Evolutionary Algorithm for Large-Scale Multi-Objective VNF Placement Problems
Dec 17, 2025Modern data centers contain thousands of servers making them major consumers of electricity. To minimize their environmental impact, it is critical that we use their resources efficiently. In this paper we study how to discover the optimal placement of virtual network functions in large scale data centers. We propose a novel parallel metaheuristic, fast heuristic objective functions of the QoS and new memory efficient data structures for large networks. We further identify a simple, fast heuristic that can produce competitive solutions to very large problem instances. Using these new concepts, we are able to find high quality solutions for data centres with up to 64,000 servers.
Assessing Automated Fact-Checking for Medical LLM Responses with Knowledge Graphs
Nov 16, 2025



The recent proliferation of large language models (LLMs) holds the potential to revolutionize healthcare, with strong capabilities in diverse medical tasks. Yet, deploying LLMs in high-stakes healthcare settings requires rigorous verification and validation to understand any potential harm. This paper investigates the reliability and viability of using medical knowledge graphs (KGs) for the automated factuality evaluation of LLM-generated responses. To ground this investigation, we introduce FAITH, a framework designed to systematically probe the strengths and limitations of this KG-based approach. FAITH operates without reference answers by decomposing responses into atomic claims, linking them to a medical KG, and scoring them based on evidence paths. Experiments on diverse medical tasks with human subjective evaluations demonstrate that KG-grounded evaluation achieves considerably higher correlations with clinician judgments and can effectively distinguish LLMs with varying capabilities. It is also robust to textual variances. The inherent explainability of its scoring can further help users understand and mitigate the limitations of current LLMs. We conclude that while limitations exist, leveraging KGs is a prominent direction for automated factuality assessment in healthcare.
Preference is More Than Comparisons: Rethinking Dueling Bandits with Augmented Human Feedback
Nov 12, 2025Interactive preference elicitation (IPE) aims to substantially reduce human effort while acquiring human preferences in wide personalization systems. Dueling bandit (DB) algorithms enable optimal decision-making in IPE building on pairwise comparisons. However, they remain inefficient when human feedback is sparse. Existing methods address sparsity by heavily relying on parametric reward models, whose rigid assumptions are vulnerable to misspecification. In contrast, we explore an alternative perspective based on feedback augmentation, and introduce critical improvements to the model-free DB framework. Specifically, we introduce augmented confidence bounds to integrate augmented human feedback under generalized concentration properties, and analyze the multi-factored performance trade-off via regret analysis. Our prototype algorithm achieves competitive performance across several IPE benchmarks, including recommendation, multi-objective optimization, and response optimization for large language models, demonstrating the potential of our approach for provably efficient IPE in broader applications.
Beyond Monotonicity: Revisiting Factorization Principles in Multi-Agent Q-Learning
Nov 12, 2025Value decomposition is a central approach in multi-agent reinforcement learning (MARL), enabling centralized training with decentralized execution by factorizing the global value function into local values. To ensure individual-global-max (IGM) consistency, existing methods either enforce monotonicity constraints, which limit expressive power, or adopt softer surrogates at the cost of algorithmic complexity. In this work, we present a dynamical systems analysis of non-monotonic value decomposition, modeling learning dynamics as continuous-time gradient flow. We prove that, under approximately greedy exploration, all zero-loss equilibria violating IGM consistency are unstable saddle points, while only IGM-consistent solutions are stable attractors of the learning dynamics. Extensive experiments on both synthetic matrix games and challenging MARL benchmarks demonstrate that unconstrained, non-monotonic factorization reliably recovers IGM-optimal solutions and consistently outperforms monotonic baselines. Additionally, we investigate the influence of temporal-difference targets and exploration strategies, providing actionable insights for the design of future value-based MARL algorithms.