 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMPDM: A Diffusion Model for Driving Video Prediction with Historical Motion Priors
Mar 28, 2026Video prediction is a useful function for autonomous driving, enabling intelligent vehicles to reliably anticipate how driving scenes will evolve and thereby supporting reasoning and safer planning. However, existing models are constrained by multi-stage training pipelines and remain insufficient in modeling the diverse motion patterns in real driving scenes, leading to degraded temporal consistency and visual quality. To address these challenges, this paper introduces the historical motion priors-informed diffusion model (HMPDM), a video prediction model that leverages historical motion priors to enhance motion understanding and temporal coherence. The proposed deep learning system introduces three key designs: (i) a Temporal-aware Latent Conditioning (TaLC) module for implicit historical motion injection; (ii) a Motion-aware Pyramid Encoder (MaPE) for multi-scale motion representation; (iii) a Self-Conditioning (SC) strategy for stable iterative denoising. Extensive experiments on the Cityscapes and KITTI benchmarks demonstrate that HMPDM outperforms state-of-the-art video prediction methods with efficiency, achieving a 28.2% improvement in FVD on Cityscapes under the same monocular RGB input configuration setting. The implementation codes are publicly available at https://github.com/KELISBU/HMPDM.
CrashChat: A Multimodal Large Language Model for Multitask Traffic Crash Video Analysis
Dec 21, 2025
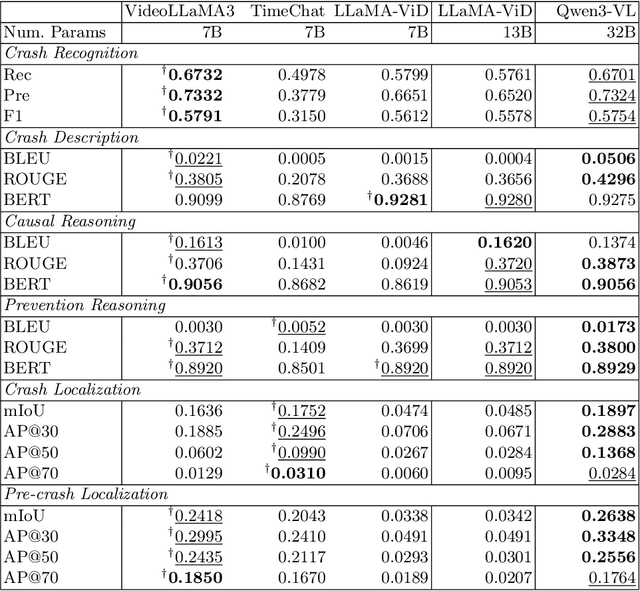
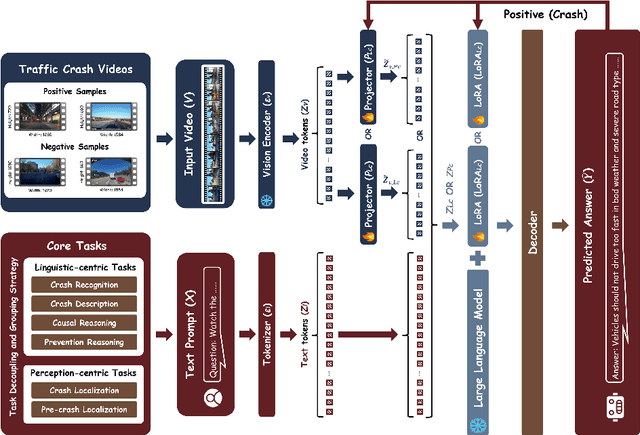
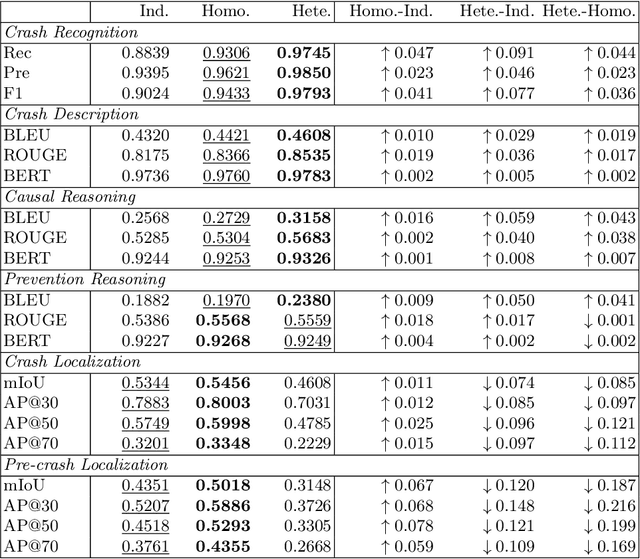
Automating crash video analysis is essential to leverage the growing availability of driving video data for traffic safety research and accountability attribution in autonomous driving. Crash video analysis is a challenging multitask problem due to the complex spatiotemporal dynamics of crash events in video data and the diverse analytical requirements involved. It requires capabilities spanning crash recognition, temporal grounding, and high-level video understanding. Existing models, however, cannot perform all these tasks within a unified framework, and effective training strategies for such models remain underexplored. To fill these gaps, this paper proposes CrashChat, a multimodal large language model (MLLM) for multitask traffic crash analysis, built upon VideoLLaMA3. CrashChat acquires domain-specific knowledge through instruction fine-tuning and employs a novel multitask learning strategy based on task decoupling and grouping, which maximizes the benefit of joint learning within and across task groups while mitigating negative transfer. Numerical experiments on consolidated public datasets demonstrate that CrashChat consistently outperforms existing MLLMs across model scales and traditional vision-based methods, achieving state-of-the-art performance. It reaches near-perfect accuracy in crash recognition, a 176\% improvement in crash localization, and a 40\% improvement in the more challenging pre-crash localization. Compared to general MLLMs, it substantially enhances textual accuracy and content coverage in crash description and reasoning tasks, with 0.18-0.41 increases in BLEU scores and 0.18-0.42 increases in ROUGE scores. Beyond its strong performance, CrashChat is a convenient, end-to-end analytical tool ready for practical implementation. The dataset and implementation code for CrashChat are available at https://github.com/Liangkd/CrashChat.