 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlicing Vision Transformer for Flexible Inference
Dec 06, 2024Vision Transformers (ViT) is known for its scalability. In this work, we target to scale down a ViT to fit in an environment with dynamic-changing resource constraints. We observe that smaller ViTs are intrinsically the sub-networks of a larger ViT with different widths. Thus, we propose a general framework, named Scala, to enable a single network to represent multiple smaller ViTs with flexible inference capability, which aligns with the inherent design of ViT to vary from widths. Concretely, Scala activates several subnets during training, introduces Isolated Activation to disentangle the smallest sub-network from other subnets, and leverages Scale Coordination to ensure each sub-network receives simplified, steady, and accurate learning objectives. Comprehensive empirical validations on different tasks demonstrate that with only one-shot training, Scala learns slimmable representation without modifying the original ViT structure and matches the performance of Separate Training. Compared with the prior art, Scala achieves an average improvement of 1.6% on ImageNet-1K with fewer parameters.
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.
Active Learning for Contextual Search with Binary Feedbacks
Oct 03, 2021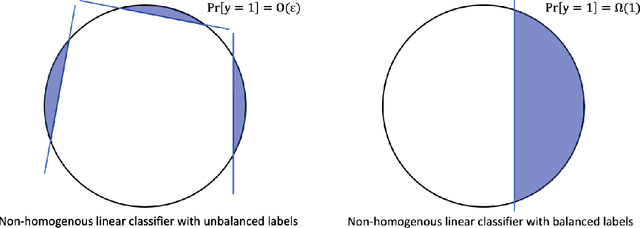
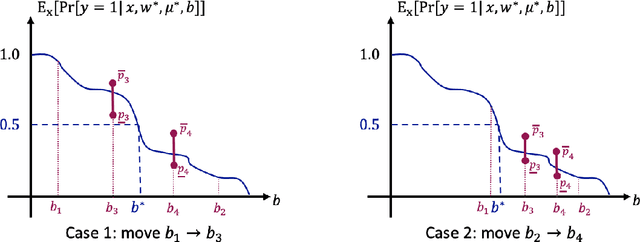
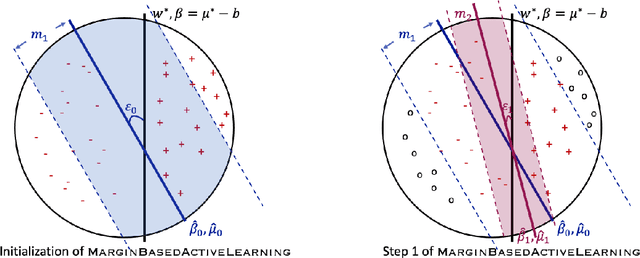
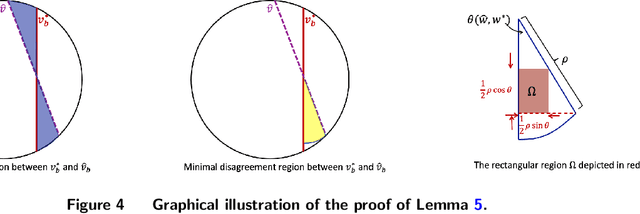
In this paper, we study the learning problem in contextual search, which is motivated by applications such as first-price auction, personalized medicine experiments, and feature-based pricing experiments. In particular, for a sequence of arriving context vectors, with each context associated with an underlying value, the decision-maker either makes a query at a certain point or skips the context. The decision-maker will only observe the binary feedback on the relationship between the query point and the value associated with the context. We study a PAC learning setting, where the goal is to learn the underlying mean value function in context with a minimum number of queries. To address this challenge, we propose a tri-section search approach combined with a margin-based active learning method. We show that the algorithm only needs to make $O(1/\varepsilon^2)$ queries to achieve an $\epsilon$-estimation accuracy. This sample complexity significantly reduces the required sample complexity in the passive setting, at least $\Omega(1/\varepsilon^4)$.
A K-fold Method for Baseline Estimation in Policy Gradient Algorithms
Jan 03, 2017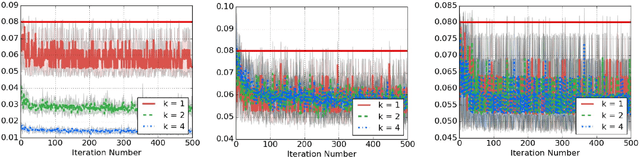
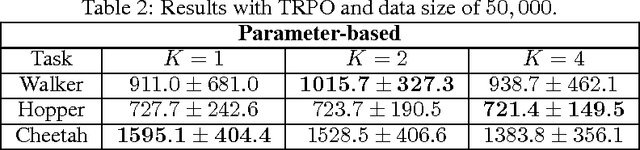
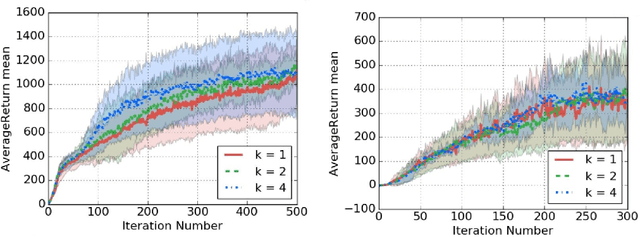
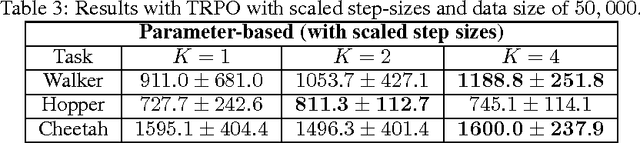
The high variance issue in unbiased policy-gradient methods such as VPG and REINFORCE is typically mitigated by adding a baseline. However, the baseline fitting itself suffers from the underfitting or the overfitting problem. In this paper, we develop a K-fold method for baseline estimation in policy gradient algorithms. The parameter K is the baseline estimation hyperparameter that can adjust the bias-variance trade-off in the baseline estimates. We demonstrate the usefulness of our approach via two state-of-the-art policy gradient algorithms on three MuJoCo locomotive control tasks.