 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable VisTR: Spatio temporal deformable attention for video instance segmentation
Mar 12, 2022
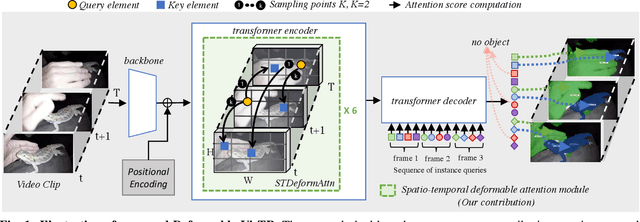

Video instance segmentation (VIS) task requires classifying, segmenting, and tracking object instances over all frames in a video clip. Recently, VisTR has been proposed as end-to-end transformer-based VIS framework, while demonstrating state-of-the-art performance. However, VisTR is slow to converge during training, requiring around 1000 GPU hours due to the high computational cost of its transformer attention module. To improve the training efficiency, we propose Deformable VisTR, leveraging spatio-temporal deformable attention module that only attends to a small fixed set of key spatio-temporal sampling points around a reference point. This enables Deformable VisTR to achieve linear computation in the size of spatio-temporal feature maps. Moreover, it can achieve on par performance as the original VisTR with 10$\times$ less GPU training hours. We validate the effectiveness of our method on the Youtube-VIS benchmark. Code is available at https://github.com/skrya/DefVIS.
Efficient Video Instance Segmentation via Tracklet Query and Proposal
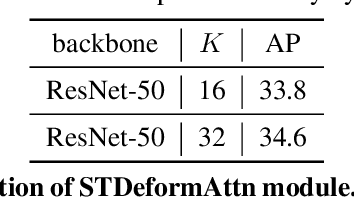
Mar 03, 2022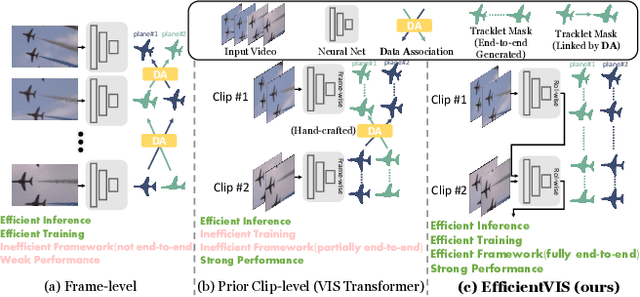
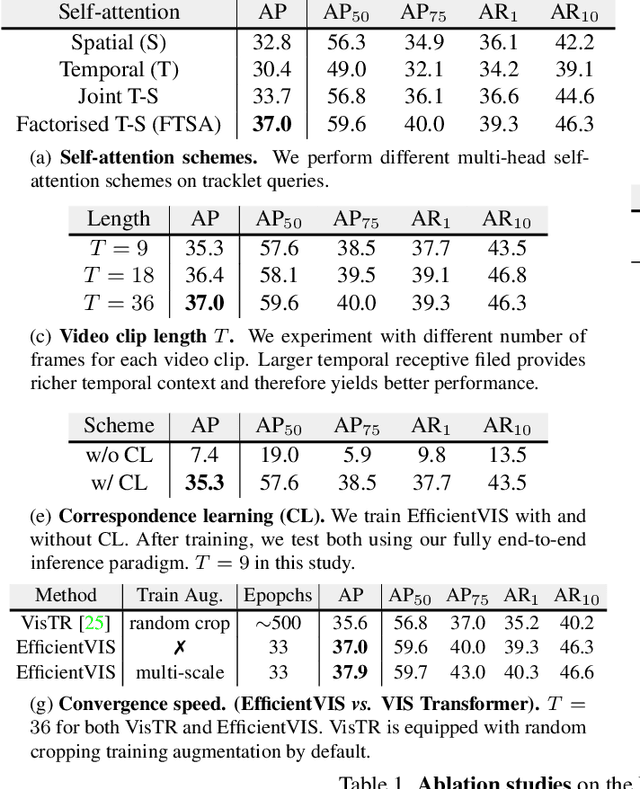
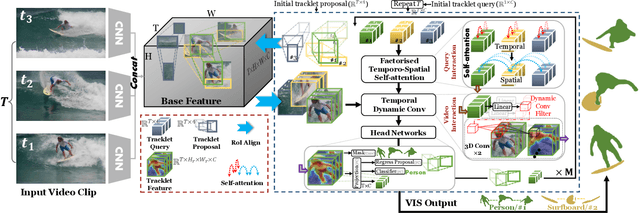
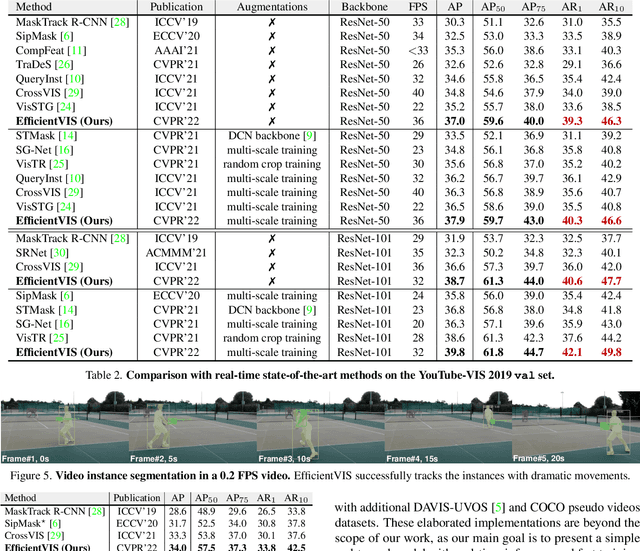
Video Instance Segmentation (VIS) aims to simultaneously classify, segment, and track multiple object instances in videos. Recent clip-level VIS takes a short video clip as input each time showing stronger performance than frame-level VIS (tracking-by-segmentation), as more temporal context from multiple frames is utilized. Yet, most clip-level methods are neither end-to-end learnable nor real-time. These limitations are addressed by the recent VIS transformer (VisTR) which performs VIS end-to-end within a clip. However, VisTR suffers from long training time due to its frame-wise dense attention. In addition, VisTR is not fully end-to-end learnable in multiple video clips as it requires a hand-crafted data association to link instance tracklets between successive clips. This paper proposes EfficientVIS, a fully end-to-end framework with efficient training and inference. At the core are tracklet query and tracklet proposal that associate and segment regions-of-interest (RoIs) across space and time by an iterative query-video interaction. We further propose a correspondence learning that makes tracklets linking between clips end-to-end learnable. Compared to VisTR, EfficientVIS requires 15x fewer training epochs while achieving state-of-the-art accuracy on the YouTube-VIS benchmark. Meanwhile, our method enables whole video instance segmentation in a single end-to-end pass without data association at all.
Slow-Fast Visual Tempo Learning for Video-based Action Recognition
Feb 24, 2022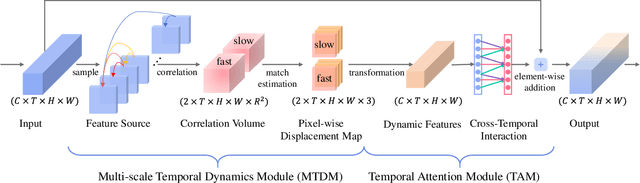
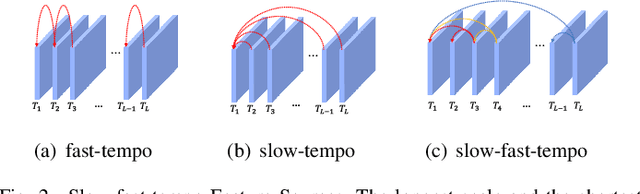
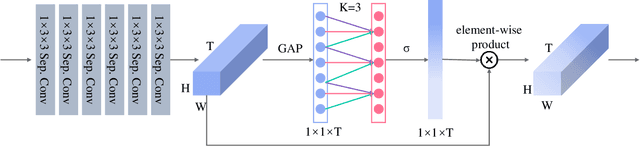
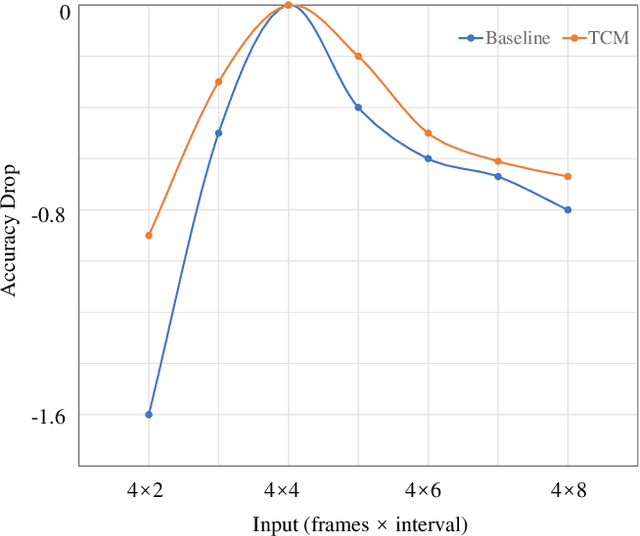
Action visual tempo characterizes the dynamics and the temporal scale of an action, which is helpful to distinguish human actions that share high similarities in visual dynamics and appearance. Previous methods capture the visual tempo either by sampling raw videos with multiple rates, which requires a costly multi-layer network to handle each rate, or by hierarchically sampling backbone features, which relies heavily on high-level features that miss fine-grained temporal dynamics. In this work, we propose a Temporal Correlation Module (TCM), which can be easily embedded into the current action recognition backbones in a plug-in-and-play manner, to extract action visual tempo from low-level backbone features at single-layer remarkably. Specifically, our TCM contains two main components: a Multi-scale Temporal Dynamics Module (MTDM) and a Temporal Attention Module (TAM). MTDM applies a correlation operation to learn pixel-wise fine-grained temporal dynamics for both fast-tempo and slow-tempo. TAM adaptively emphasizes expressive features and suppresses inessential ones via analyzing the global information across various tempos. Extensive experiments conducted on several action recognition benchmarks, e.g. Something-Something V1 & V2, Kinetics-400, UCF-101, and HMDB-51, have demonstrated that the proposed TCM is effective to promote the performance of the existing video-based action recognition models for a large margin. The source code is publicly released at https://github.com/zphyix/TCM.
Joint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition
Feb 08, 2022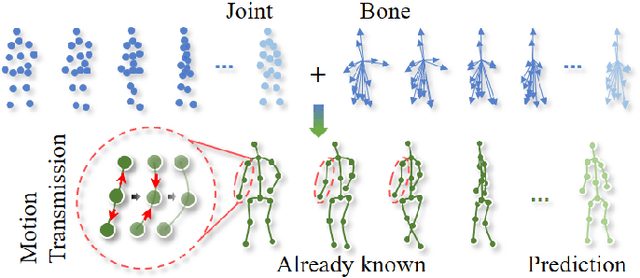
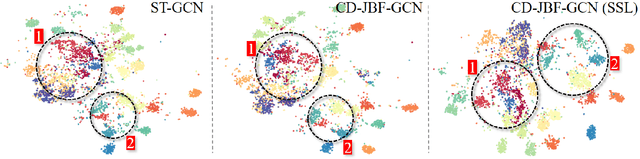
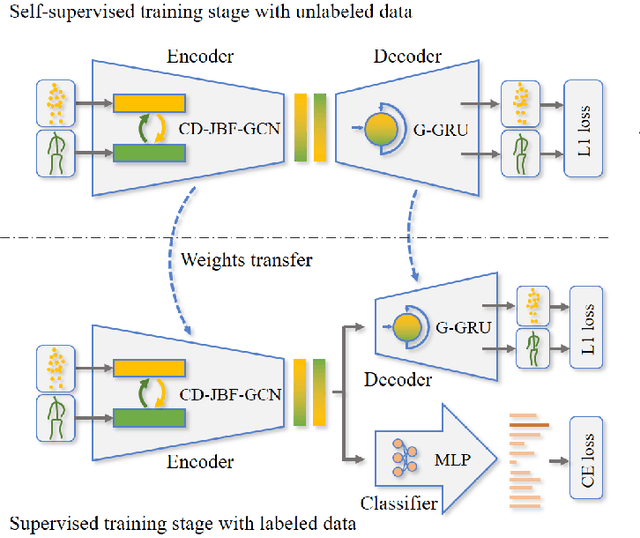
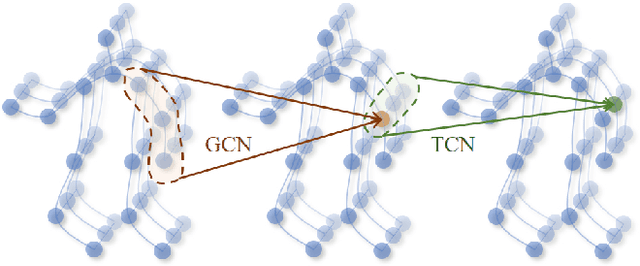
In recent years, graph convolutional networks (GCNs) play an increasingly critical role in skeleton-based human action recognition. However, most GCN-based methods still have two main limitations: 1) They only consider the motion information of the joints or process the joints and bones separately, which are unable to fully explore the latent functional correlation between joints and bones for action recognition. 2) Most of these works are performed in the supervised learning way, which heavily relies on massive labeled training data. To address these issues, we propose a semi-supervised skeleton-based action recognition method which has been rarely exploited before. We design a novel correlation-driven joint-bone fusion graph convolutional network (CD-JBF-GCN) as an encoder and use a pose prediction head as a decoder to achieve semi-supervised learning. Specifically, the CD-JBF-GC can explore the motion transmission between the joint stream and the bone stream, so that promoting both streams to learn more discriminative feature representations. The pose prediction based auto-encoder in the self-supervised training stage allows the network to learn motion representation from unlabeled data, which is essential for action recognition. Extensive experiments on two popular datasets, i.e. NTU-RGB+D and Kinetics-Skeleton, demonstrate that our model achieves the state-of-the-art performance for semi-supervised skeleton-based action recognition and is also useful for fully-supervised methods.
Consistent 3D Hand Reconstruction in Video via self-supervised Learning
Jan 24, 2022
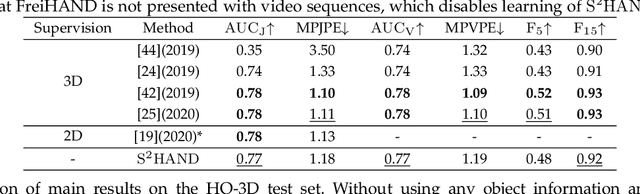
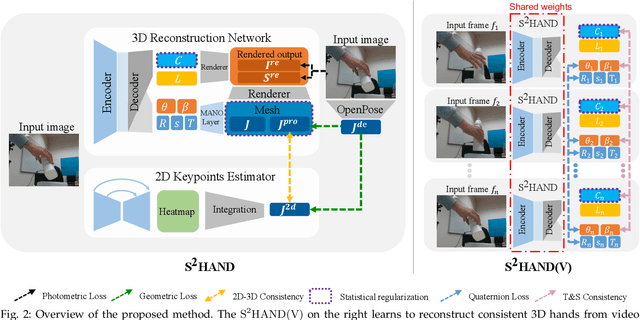
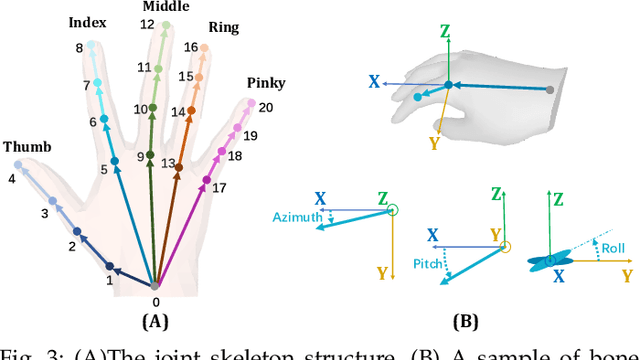
We present a method for reconstructing accurate and consistent 3D hands from a monocular video. We observe that detected 2D hand keypoints and the image texture provide important cues about the geometry and texture of the 3D hand, which can reduce or even eliminate the requirement on 3D hand annotation. Thus we propose ${\rm {S}^{2}HAND}$, a self-supervised 3D hand reconstruction model, that can jointly estimate pose, shape, texture, and the camera viewpoint from a single RGB input through the supervision of easily accessible 2D detected keypoints. We leverage the continuous hand motion information contained in the unlabeled video data and propose ${\rm {S}^{2}HAND(V)}$, which uses a set of weights shared ${\rm {S}^{2}HAND}$ to process each frame and exploits additional motion, texture, and shape consistency constrains to promote more accurate hand poses and more consistent shapes and textures. Experiments on benchmark datasets demonstrate that our self-supervised approach produces comparable hand reconstruction performance compared with the recent full-supervised methods in single-frame as input setup, and notably improves the reconstruction accuracy and consistency when using video training data.
Pseudo Supervised Monocular Depth Estimation with Teacher-Student Network
Oct 22, 2021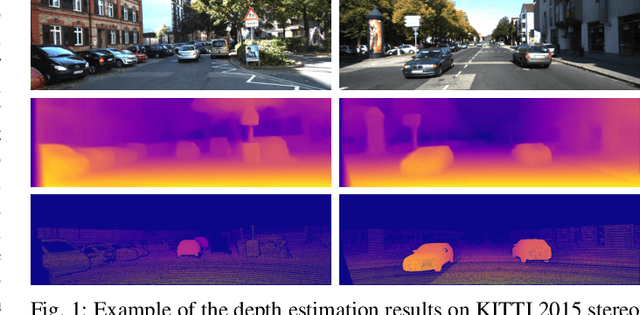
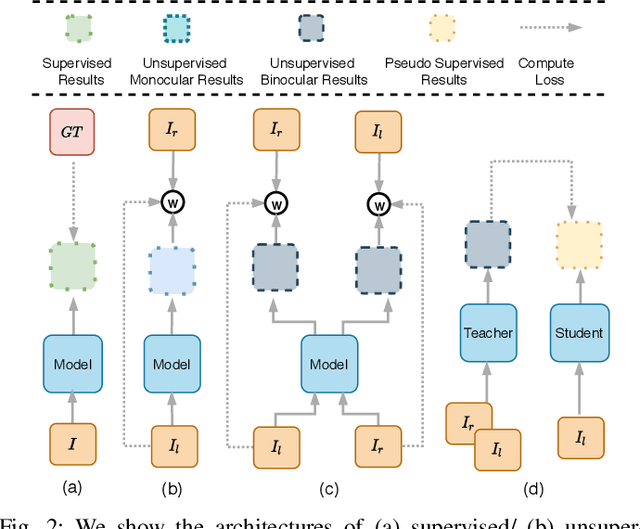
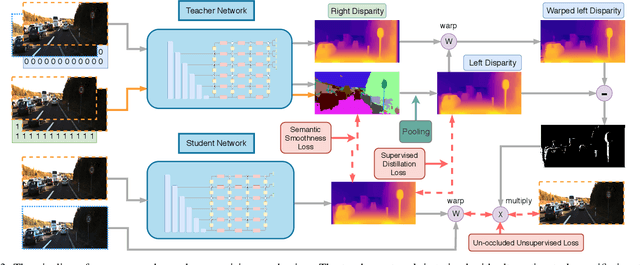
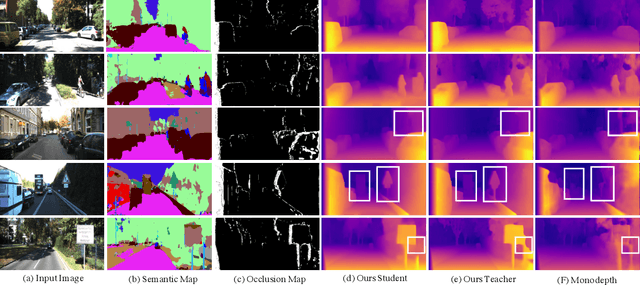
Despite recent improvement of supervised monocular depth estimation, the lack of high quality pixel-wise ground truth annotations has become a major hurdle for further progress. In this work, we propose a new unsupervised depth estimation method based on pseudo supervision mechanism by training a teacher-student network with knowledge distillation. It strategically integrates the advantages of supervised and unsupervised monocular depth estimation, as well as unsupervised binocular depth estimation. Specifically, the teacher network takes advantage of the effectiveness of binocular depth estimation to produce accurate disparity maps, which are then used as the pseudo ground truth to train the student network for monocular depth estimation. This effectively converts the problem of unsupervised learning to supervised learning. Our extensive experimental results demonstrate that the proposed method outperforms the state-of-the-art on the KITTI benchmark.
OVIS: Open-Vocabulary Visual Instance Search via Visual-Semantic Aligned Representation Learning
Aug 08, 2021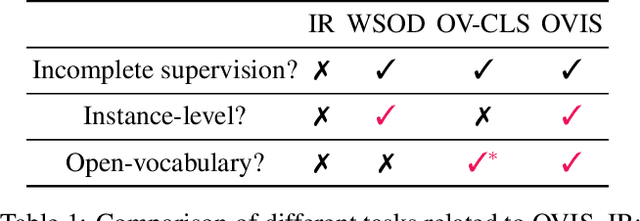
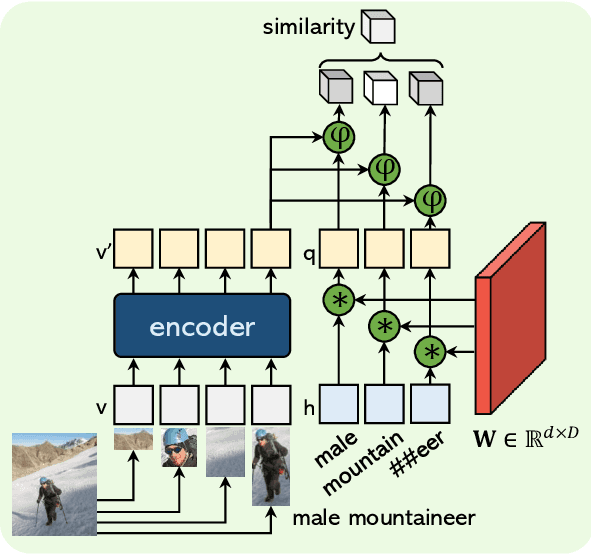

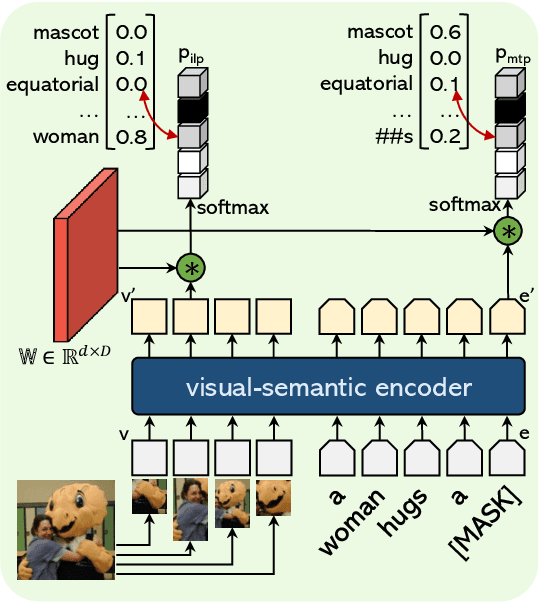
We introduce the task of open-vocabulary visual instance search (OVIS). Given an arbitrary textual search query, Open-vocabulary Visual Instance Search (OVIS) aims to return a ranked list of visual instances, i.e., image patches, that satisfies the search intent from an image database. The term "open vocabulary" means that there are neither restrictions to the visual instance to be searched nor restrictions to the word that can be used to compose the textual search query. We propose to address such a search challenge via visual-semantic aligned representation learning (ViSA). ViSA leverages massive image-caption pairs as weak image-level (not instance-level) supervision to learn a rich cross-modal semantic space where the representations of visual instances (not images) and those of textual queries are aligned, thus allowing us to measure the similarities between any visual instance and an arbitrary textual query. To evaluate the performance of ViSA, we build two datasets named OVIS40 and OVIS1600 and also introduce a pipeline for error analysis. Through extensive experiments on the two datasets, we demonstrate ViSA's ability to search for visual instances in images not available during training given a wide range of textual queries including those composed of uncommon words. Experimental results show that ViSA achieves an mAP@50 of 21.9% on OVIS40 under the most challenging setting and achieves an mAP@6 of 14.9% on OVIS1600 dataset.
Two-Stream Consensus Network: Submission to HACS Challenge 2021 Weakly-Supervised Learning Track
Jul 11, 2021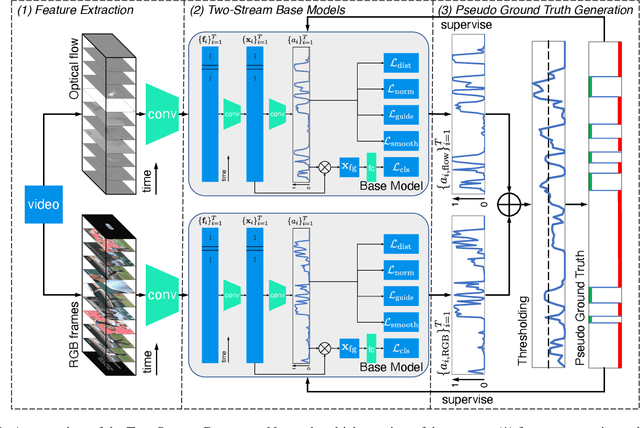
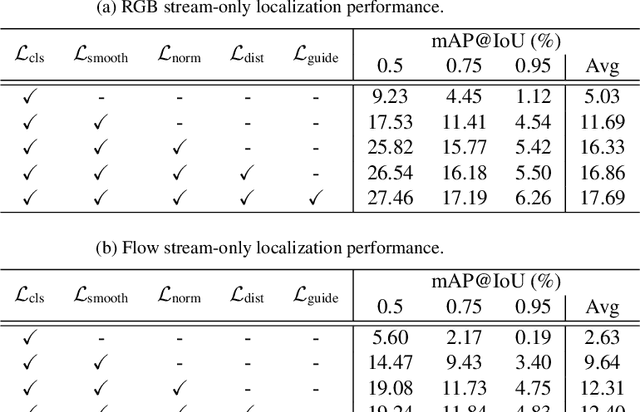
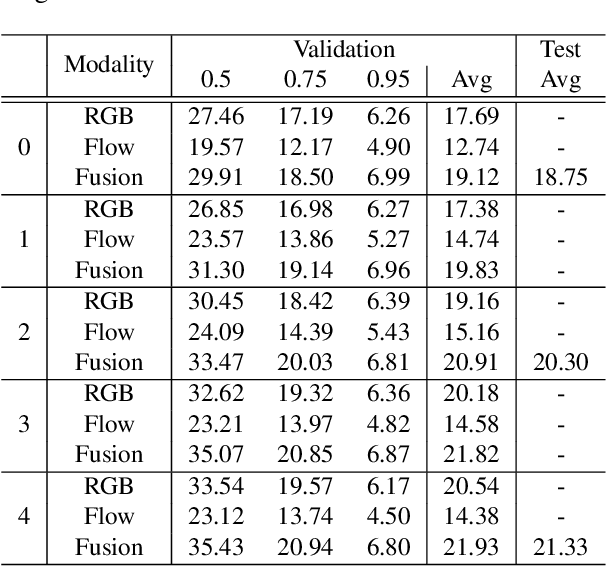
This technical report presents our solution to the HACS Temporal Action Localization Challenge 2021, Weakly-Supervised Learning Track. The goal of weakly-supervised temporal action localization is to temporally locate and classify action of interest in untrimmed videos given only video-level labels. We adopt the two-stream consensus network (TSCN) as the main framework in this challenge. The TSCN consists of a two-stream base model training procedure and a pseudo ground truth learning procedure. The base model training encourages the model to predict reliable predictions based on single modality (i.e., RGB or optical flow), based on the fusion of which a pseudo ground truth is generated and in turn used as supervision to train the base models. On the HACS v1.1.1 dataset, without fine-tuning the feature-extraction I3D models, our method achieves 22.20% on the validation set and 21.68% on the testing set in terms of average mAP. Our solution ranked the 2rd in this challenge, and we hope our method can serve as a baseline for future academic research.
NeLF: Practical Novel View Synthesis with Neural Light Field
May 21, 2021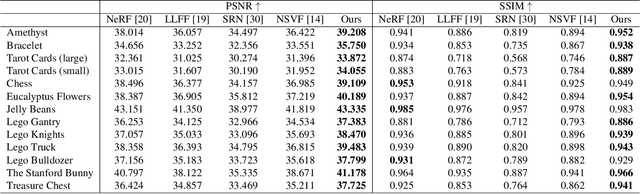
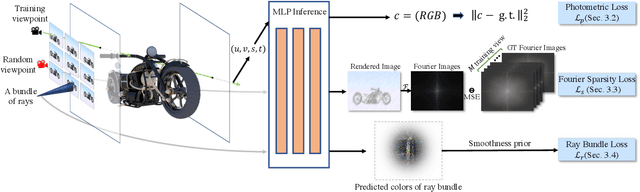
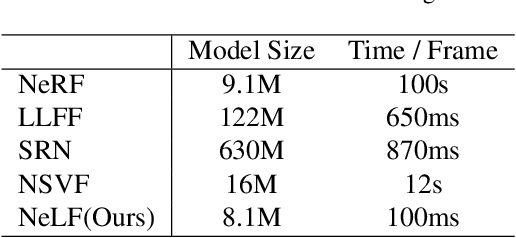
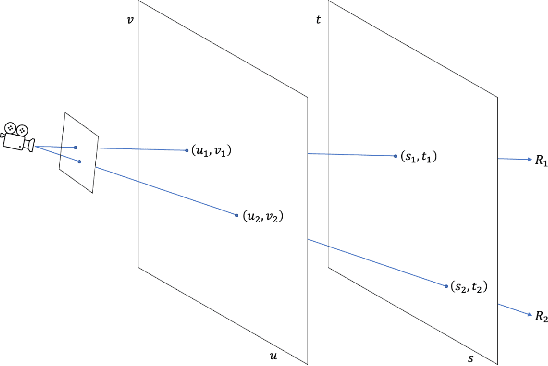
In this paper, we present an efficient and robust deep learning solution for novel view synthesis of complex scenes. In our approach, a 3D scene is represented as a light field, i.e., a set of rays, each of which has a corresponding color when reaching the image plane. For efficient novel view rendering, we adopt a 4D parameterization of the light field, where each ray is characterized by a 4D parameter. We then formulate the light field as a 4D function that maps 4D coordinates to corresponding color values. We train a deep fully connected network to optimize this implicit function and memorize the 3D scene. Then, the scene-specific model is used to synthesize novel views. Different from previous light field approaches which require dense view sampling to reliably render novel views, our method can render novel views by sampling rays and querying the color for each ray from the network directly, thus enabling high-quality light field rendering with a sparser set of training images. Our method achieves state-of-the-art novel view synthesis results while maintaining an interactive frame rate.
Weakly Supervised Temporal Action Localization Through Learning Explicit Subspaces for Action and Context
Mar 30, 2021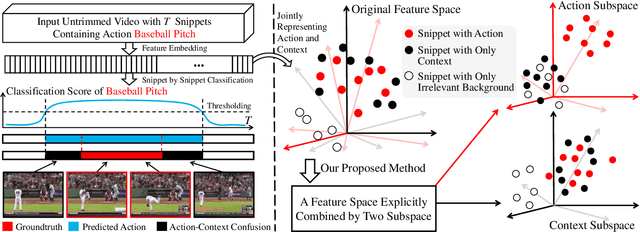

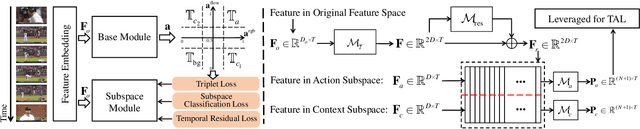
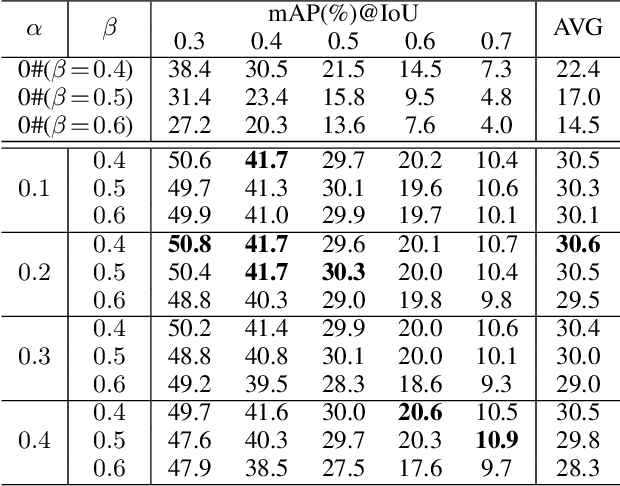
Weakly-supervised Temporal Action Localization (WS-TAL) methods learn to localize temporal starts and ends of action instances in a video under only video-level supervision. Existing WS-TAL methods rely on deep features learned for action recognition. However, due to the mismatch between classification and localization, these features cannot distinguish the frequently co-occurring contextual background, i.e., the context, and the actual action instances. We term this challenge action-context confusion, and it will adversely affect the action localization accuracy. To address this challenge, we introduce a framework that learns two feature subspaces respectively for actions and their context. By explicitly accounting for action visual elements, the action instances can be localized more precisely without the distraction from the context. To facilitate the learning of these two feature subspaces with only video-level categorical labels, we leverage the predictions from both spatial and temporal streams for snippets grouping. In addition, an unsupervised learning task is introduced to make the proposed module focus on mining temporal information. The proposed approach outperforms state-of-the-art WS-TAL methods on three benchmarks, i.e., THUMOS14, ActivityNet v1.2 and v1.3 datasets.