 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Distinct Representation Learning for Action Recognition
Paper and Code
Jul 15, 2020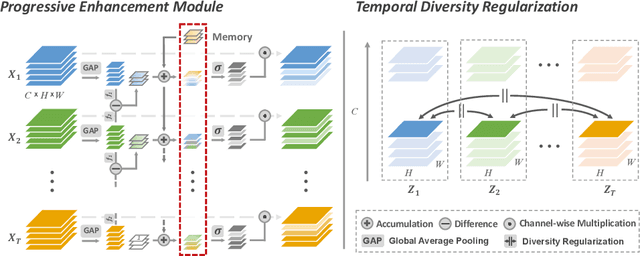
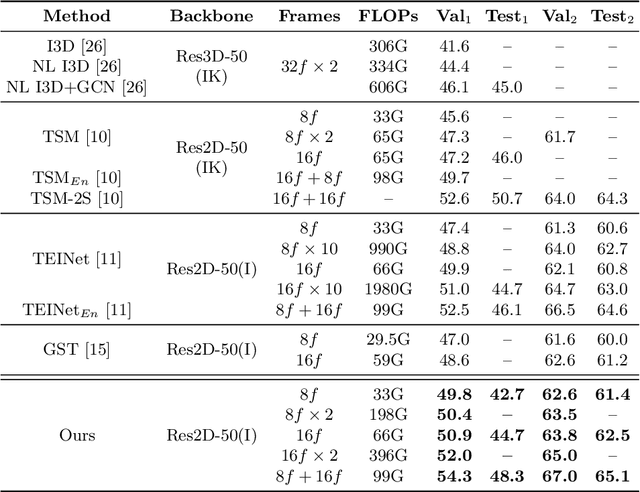
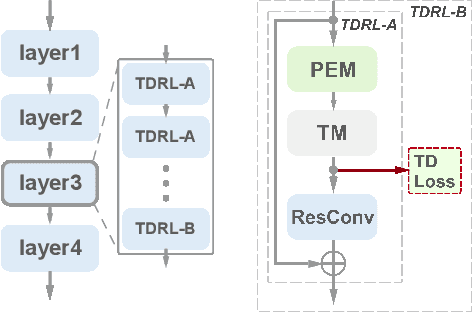
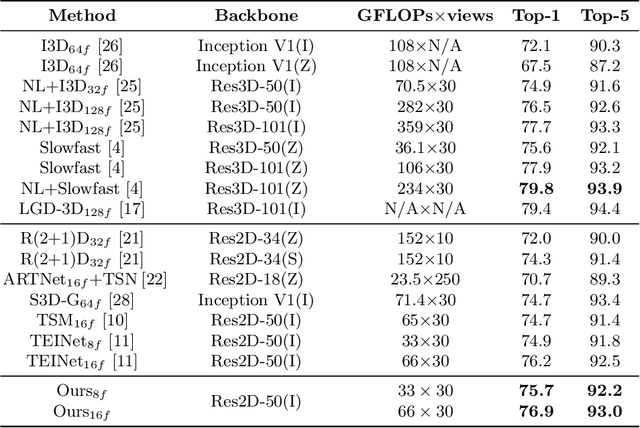
Motivated by the previous success of Two-Dimensional Convolutional Neural Network (2D CNN) on image recognition, researchers endeavor to leverage it to characterize videos. However, one limitation of applying 2D CNN to analyze videos is that different frames of a video share the same 2D CNN kernels, which may result in repeated and redundant information utilization, especially in the spatial semantics extraction process, hence neglecting the critical variations among frames. In this paper, we attempt to tackle this issue through two ways. 1) Design a sequential channel filtering mechanism, i.e., Progressive Enhancement Module (PEM), to excite the discriminative channels of features from different frames step by step, and thus avoid repeated information extraction. 2) Create a Temporal Diversity Loss (TD Loss) to force the kernels to concentrate on and capture the variations among frames rather than the image regions with similar appearance. Our method is evaluated on benchmark temporal reasoning datasets Something-Something V1 and V2, and it achieves visible improvements over the best competitor by 2.4% and 1.3%, respectively. Besides, performance improvements over the 2D-CNN-based state-of-the-arts on the large-scale dataset Kinetics are also witnessed.