 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Parking Availability in Singapore with Cross-Domain Data: A New Dataset and A Data-Driven Approach
May 29, 2024



The increasing number of vehicles highlights the need for efficient parking space management. Predicting real-time Parking Availability (PA) can help mitigate traffic congestion and the corresponding social problems, which is a pressing issue in densely populated cities like Singapore. In this study, we aim to collectively predict future PA across Singapore with complex factors from various domains. The contributions in this paper are listed as follows: (1) A New Dataset: We introduce the \texttt{SINPA} dataset, containing a year's worth of PA data from 1,687 parking lots in Singapore, enriched with various spatial and temporal factors. (2) A Data-Driven Approach: We present DeepPA, a novel deep-learning framework, to collectively and efficiently predict future PA across thousands of parking lots. (3) Extensive Experiments and Deployment: DeepPA demonstrates a 9.2% reduction in prediction error for up to 3-hour forecasts compared to existing advanced models. Furthermore, we implement DeepPA in a practical web-based platform to provide real-time PA predictions to aid drivers and inform urban planning for the governors in Singapore. We release the dataset and source code at https://github.com/yoshall/SINPA.
Primitive3D: 3D Object Dataset Synthesis from Randomly Assembled Primitives
May 25, 2022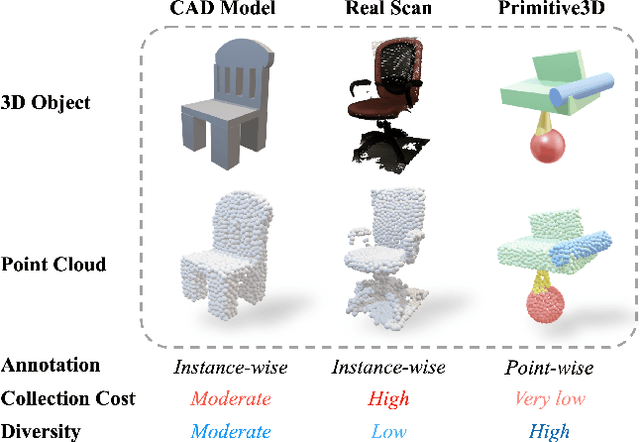

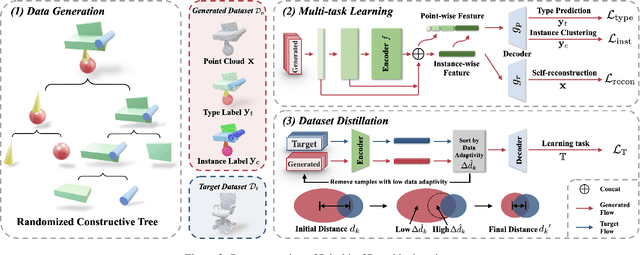
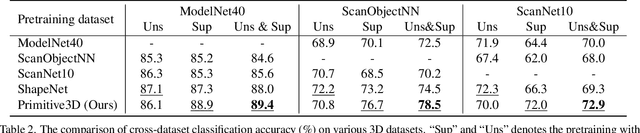
Numerous advancements in deep learning can be attributed to the access to large-scale and well-annotated datasets. However, such a dataset is prohibitively expensive in 3D computer vision due to the substantial collection cost. To alleviate this issue, we propose a cost-effective method for automatically generating a large amount of 3D objects with annotations. In particular, we synthesize objects simply by assembling multiple random primitives. These objects are thus auto-annotated with part labels originating from primitives. This allows us to perform multi-task learning by combining the supervised segmentation with unsupervised reconstruction. Considering the large overhead of learning on the generated dataset, we further propose a dataset distillation strategy to remove redundant samples regarding a target dataset. We conduct extensive experiments for the downstream tasks of 3D object classification. The results indicate that our dataset, together with multi-task pretraining on its annotations, achieves the best performance compared to other commonly used datasets. Further study suggests that our strategy can improve the model performance by pretraining and fine-tuning scheme, especially for the dataset with a small scale. In addition, pretraining with the proposed dataset distillation method can save 86\% of the pretraining time with negligible performance degradation. We expect that our attempt provides a new data-centric perspective for training 3D deep models.
Bridging the Source-to-target Gap for Cross-domain Person Re-Identification with Intermediate Domains
Mar 03, 2022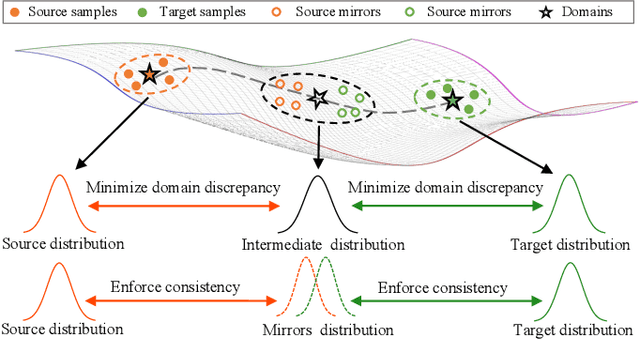
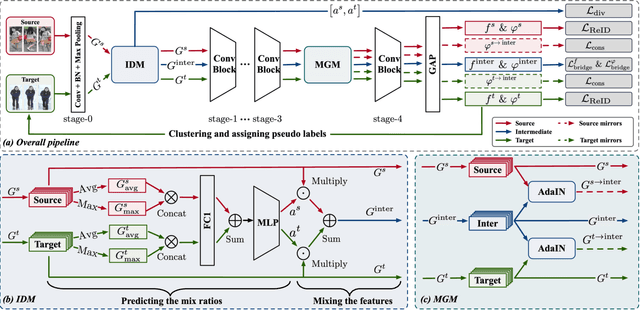
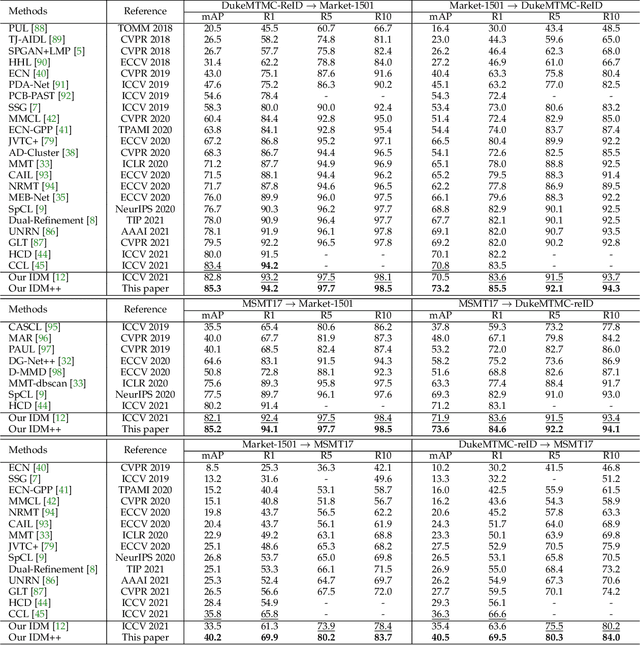
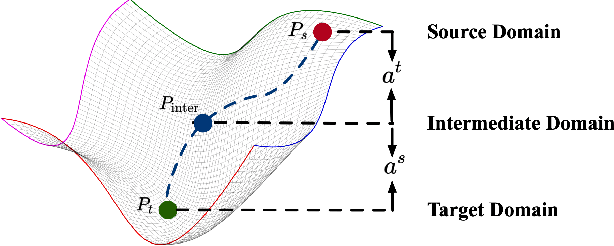
Cross-domain person re-identification (re-ID), such as unsupervised domain adaptive (UDA) re-ID, aims to transfer the identity-discriminative knowledge from the source to the target domain. Existing methods commonly consider the source and target domains are isolated from each other, i.e., no intermediate status is modeled between both domains. Directly transferring the knowledge between two isolated domains can be very difficult, especially when the domain gap is large. From a novel perspective, we assume these two domains are not completely isolated, but can be connected through intermediate domains. Instead of directly aligning the source and target domains against each other, we propose to align the source and target domains against their intermediate domains for a smooth knowledge transfer. To discover and utilize these intermediate domains, we propose an Intermediate Domain Module (IDM) and a Mirrors Generation Module (MGM). IDM has two functions: 1) it generates multiple intermediate domains by mixing the hidden-layer features from source and target domains and 2) it dynamically reduces the domain gap between the source / target domain features and the intermediate domain features. While IDM achieves good domain alignment, it introduces a side effect, i.e., the mix-up operation may mix the identities into a new identity and lose the original identities. To compensate this, MGM is introduced by mapping the features into the IDM-generated intermediate domains without changing their original identity. It allows to focus on minimizing domain variations to promote the alignment between the source / target domain and intermediate domains, which reinforces IDM into IDM++. We extensively evaluate our method under both the UDA and domain generalization (DG) scenarios and observe that IDM++ yields consistent performance improvement for cross-domain re-ID, achieving new state of the art.
IDM: An Intermediate Domain Module for Domain Adaptive Person Re-ID
Aug 05, 2021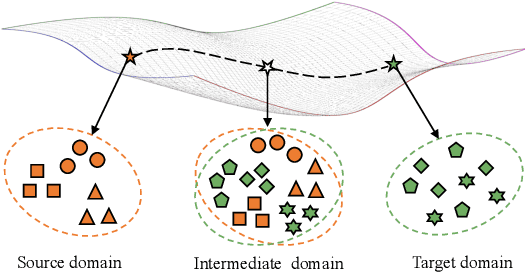
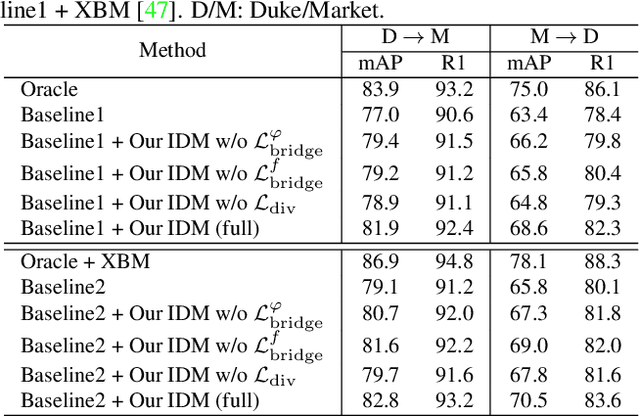
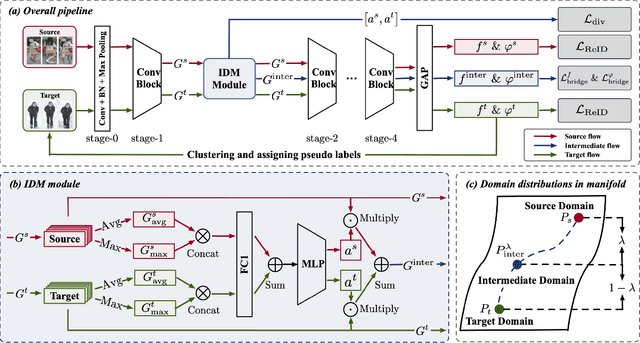
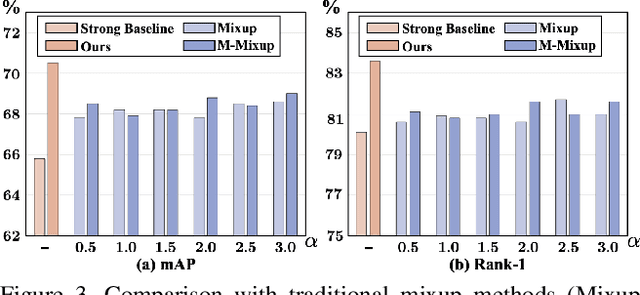
Unsupervised domain adaptive person re-identification (UDA re-ID) aims at transferring the labeled source domain's knowledge to improve the model's discriminability on the unlabeled target domain. From a novel perspective, we argue that the bridging between the source and target domains can be utilized to tackle the UDA re-ID task, and we focus on explicitly modeling appropriate intermediate domains to characterize this bridging. Specifically, we propose an Intermediate Domain Module (IDM) to generate intermediate domains' representations on-the-fly by mixing the source and target domains' hidden representations using two domain factors. Based on the "shortest geodesic path" definition, i.e., the intermediate domains along the shortest geodesic path between the two extreme domains can play a better bridging role, we propose two properties that these intermediate domains should satisfy. To ensure these two properties to better characterize appropriate intermediate domains, we enforce the bridge losses on intermediate domains' prediction space and feature space, and enforce a diversity loss on the two domain factors. The bridge losses aim at guiding the distribution of appropriate intermediate domains to keep the right distance to the source and target domains. The diversity loss serves as a regularization to prevent the generated intermediate domains from being over-fitting to either of the source and target domains. Our proposed method outperforms the state-of-the-arts by a large margin in all the common UDA re-ID tasks, and the mAP gain is up to 7.7% on the challenging MSMT17 benchmark. Code is available at https://github.com/SikaStar/IDM.
Generalizable Person Re-identification with Relevance-aware Mixture of Experts
May 19, 2021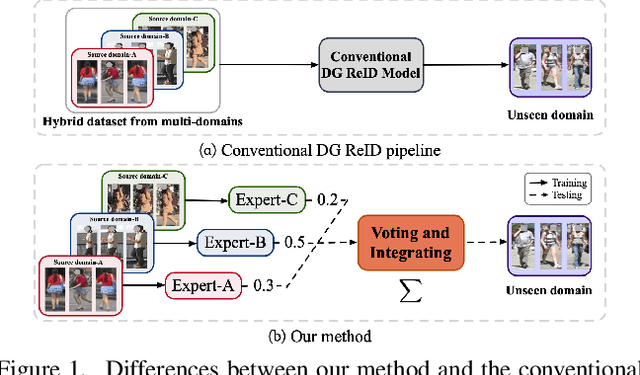
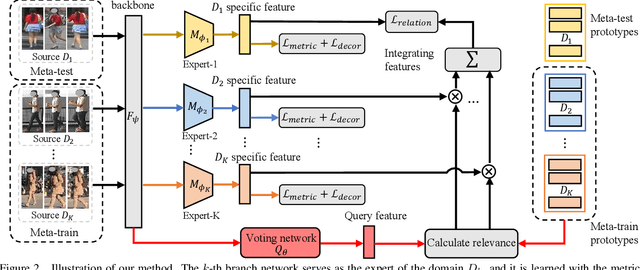
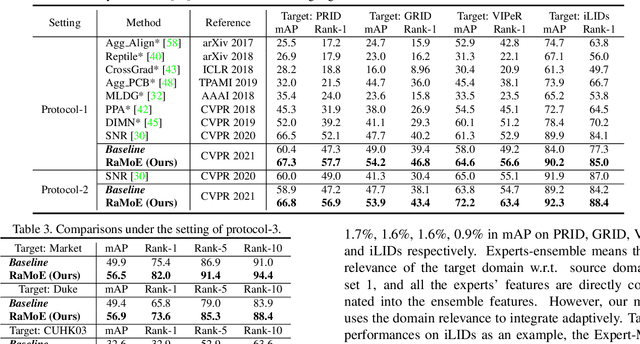
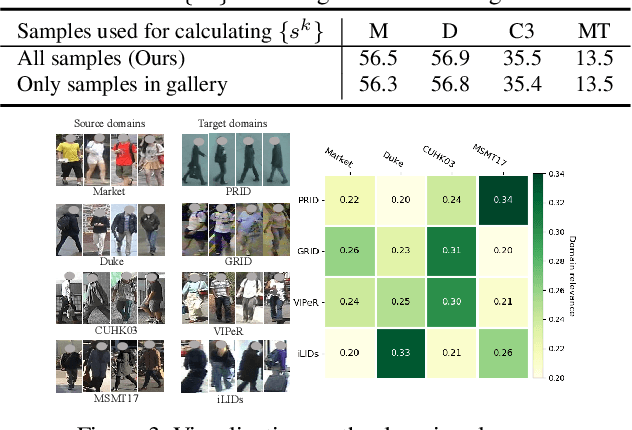
Domain generalizable (DG) person re-identification (ReID) is a challenging problem because we cannot access any unseen target domain data during training. Almost all the existing DG ReID methods follow the same pipeline where they use a hybrid dataset from multiple source domains for training, and then directly apply the trained model to the unseen target domains for testing. These methods often neglect individual source domains' discriminative characteristics and their relevances w.r.t. the unseen target domains, though both of which can be leveraged to help the model's generalization. To handle the above two issues, we propose a novel method called the relevance-aware mixture of experts (RaMoE), using an effective voting-based mixture mechanism to dynamically leverage source domains' diverse characteristics to improve the model's generalization. Specifically, we propose a decorrelation loss to make the source domain networks (experts) keep the diversity and discriminability of individual domains' characteristics. Besides, we design a voting network to adaptively integrate all the experts' features into the more generalizable aggregated features with domain relevance. Considering the target domains' invisibility during training, we propose a novel learning-to-learn algorithm combined with our relation alignment loss to update the voting network. Extensive experiments demonstrate that our proposed RaMoE outperforms the state-of-the-art methods.
PointBA: Towards Backdoor Attacks in 3D Point Cloud
Mar 30, 2021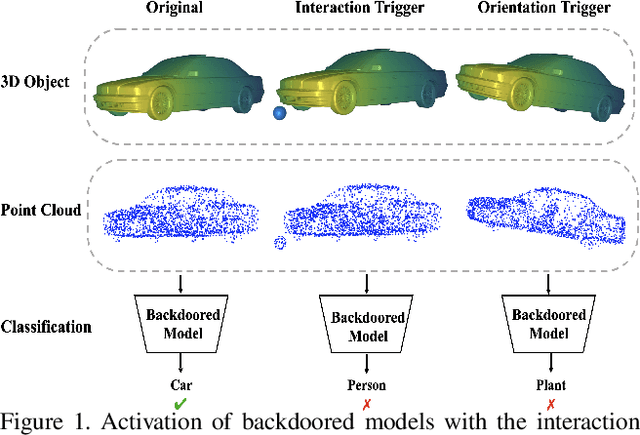

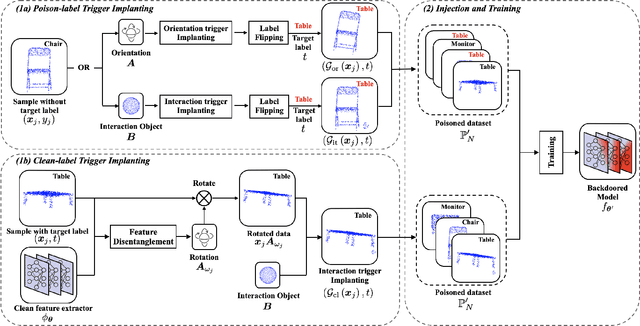

3D deep learning has been increasingly more popular for a variety of tasks including many safety-critical applications. However, recently several works raise the security issues of 3D deep nets. Although most of these works consider adversarial attacks, we identify that backdoor attack is indeed a more serious threat to 3D deep learning systems but remains unexplored. We present the backdoor attacks in 3D with a unified framework that exploits the unique properties of 3D data and networks. In particular, we design two attack approaches: the poison-label attack and the clean-label attack. The first one is straightforward and effective in practice, while the second one is more sophisticated assuming there are certain data inspections. The attack algorithms are mainly motivated and developed by 1) the recent discovery of 3D adversarial samples which demonstrate the vulnerability of 3D deep nets under spatial transformations; 2) the proposed feature disentanglement technique that manipulates the feature of the data through optimization methods and its potential to embed a new task. Extensive experiments show the efficacy of the poison-label attack with over 95% success rate across several 3D datasets and models, and the ability of clean-label attack against data filtering with around 50% success rate. Our proposed backdoor attack in 3D point cloud is expected to perform as a baseline for improving the robustness of 3D deep models.
Dual-Refinement: Joint Label and Feature Refinement for Unsupervised Domain Adaptive Person Re-Identification
Jan 17, 2021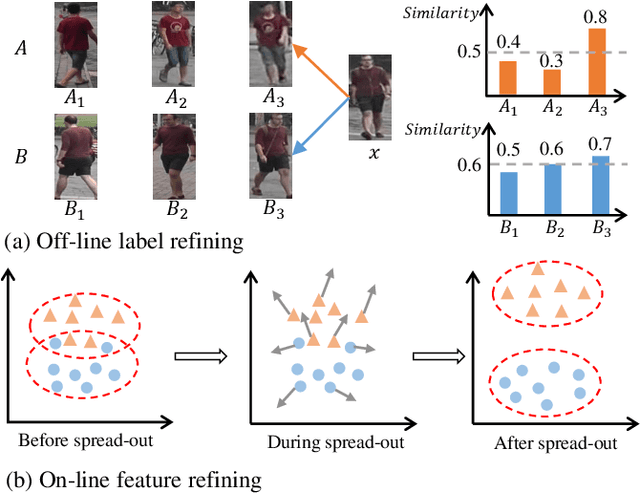
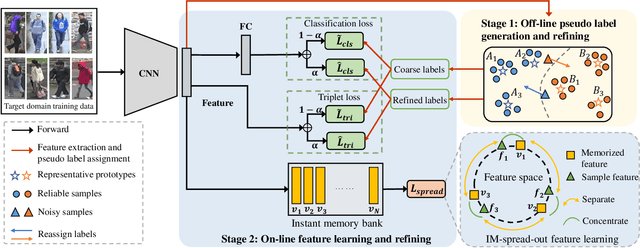
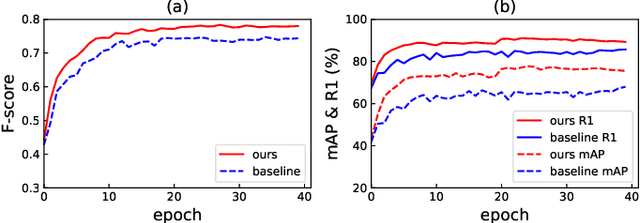
Unsupervised domain adaptive (UDA) person re-identification (re-ID) is a challenging task due to the missing of labels for the target domain data. To handle this problem, some recent works adopt clustering algorithms to off-line generate pseudo labels, which can then be used as the supervision signal for on-line feature learning in the target domain. However, the off-line generated labels often contain lots of noise that significantly hinders the discriminability of the on-line learned features, and thus limits the final UDA re-ID performance. To this end, we propose a novel approach, called Dual-Refinement, that jointly refines pseudo labels at the off-line clustering phase and features at the on-line training phase, to alternatively boost the label purity and feature discriminability in the target domain for more reliable re-ID. Specifically, at the off-line phase, a new hierarchical clustering scheme is proposed, which selects representative prototypes for every coarse cluster. Thus, labels can be effectively refined by using the inherent hierarchical information of person images. Besides, at the on-line phase, we propose an instant memory spread-out (IM-spread-out) regularization, that takes advantage of the proposed instant memory bank to store sample features of the entire dataset and enable spread-out feature learning over the entire training data instantly. Our Dual-Refinement method reduces the influence of noisy labels and refines the learned features within the alternative training process. Experiments demonstrate that our method outperforms the state-of-the-art methods by a large margin.
Campus3D: A Photogrammetry Point Cloud Benchmark for Hierarchical Understanding of Outdoor Scene
Aug 11, 2020
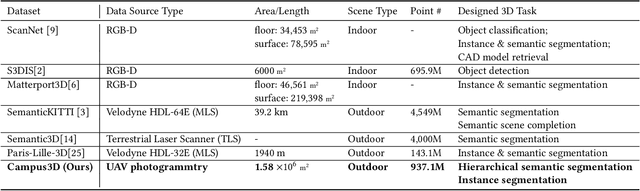

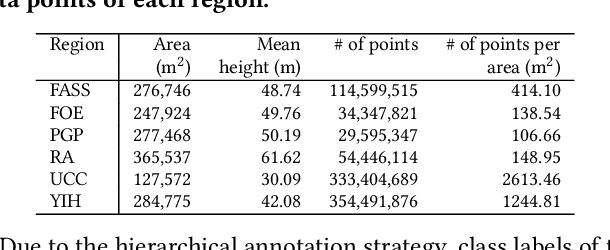
Learning on 3D scene-based point cloud has received extensive attention as its promising application in many fields, and well-annotated and multisource datasets can catalyze the development of those data-driven approaches. To facilitate the research of this area, we present a richly-annotated 3D point cloud dataset for multiple outdoor scene understanding tasks and also an effective learning framework for its hierarchical segmentation task. The dataset was generated via the photogrammetric processing on unmanned aerial vehicle (UAV) images of the National University of Singapore (NUS) campus, and has been point-wisely annotated with both hierarchical and instance-based labels. Based on it, we formulate a hierarchical learning problem for 3D point cloud segmentation and propose a measurement evaluating consistency across various hierarchies. To solve this problem, a two-stage method including multi-task (MT) learning and hierarchical ensemble (HE) with consistency consideration is proposed. Experimental results demonstrate the superiority of the proposed method and potential advantages of our hierarchical annotations. In addition, we benchmark results of semantic and instance segmentation, which is accessible online at https://3d.dataset.site with the dataset and all source codes.
* Accepted by the 28th ACM International Conference on Multimedia (ACM MM 2020)
Directed Graph Convolutional Network
Apr 29, 2020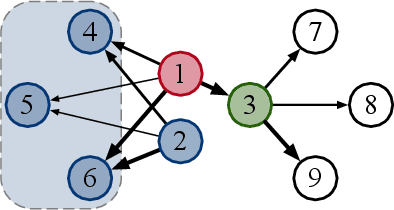
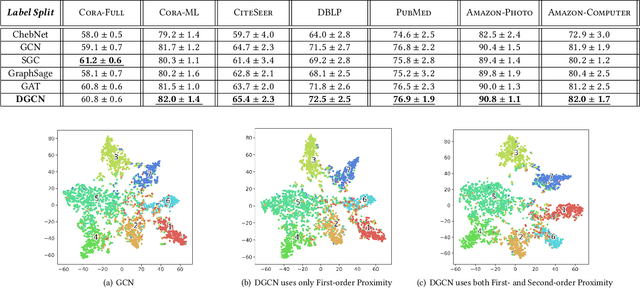
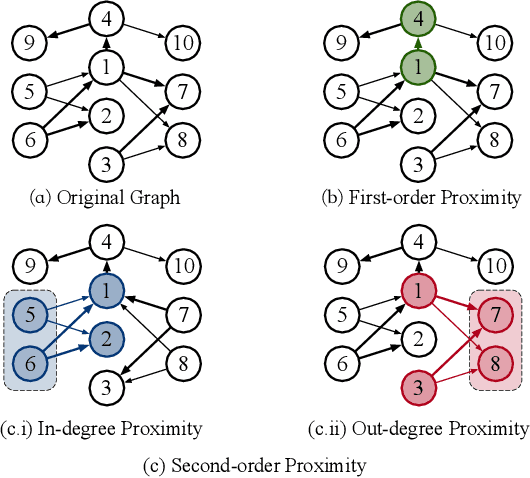
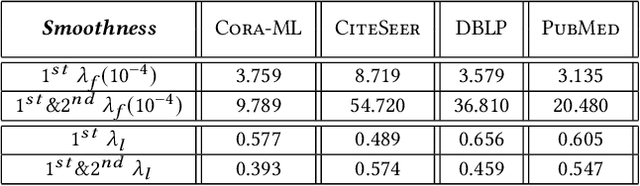
Graph Convolutional Networks (GCNs) have been widely used due to their outstanding performance in processing graph-structured data. However, the undirected graphs limit their application scope. In this paper, we extend spectral-based graph convolution to directed graphs by using first- and second-order proximity, which can not only retain the connection properties of the directed graph, but also expand the receptive field of the convolution operation. A new GCN model, called DGCN, is then designed to learn representations on the directed graph, leveraging both the first- and second-order proximity information. We empirically show the fact that GCNs working only with DGCNs can encode more useful information from graph and help achieve better performance when generalized to other models. Moreover, extensive experiments on citation networks and co-purchase datasets demonstrate the superiority of our model against the state-of-the-art methods.
Fine-Grained Urban Flow Inference
Feb 05, 2020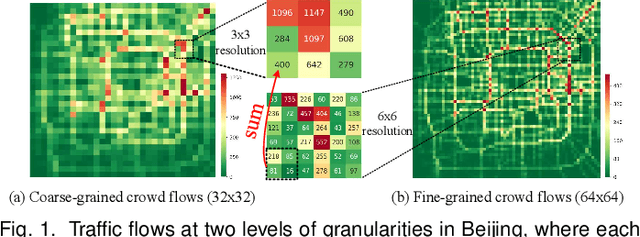
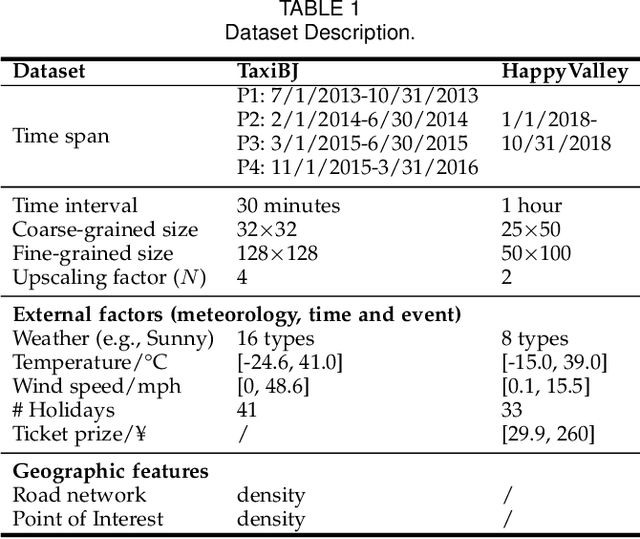
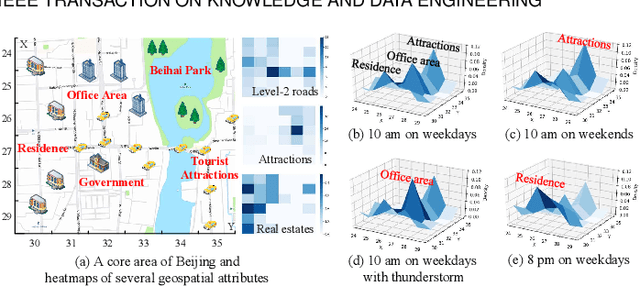
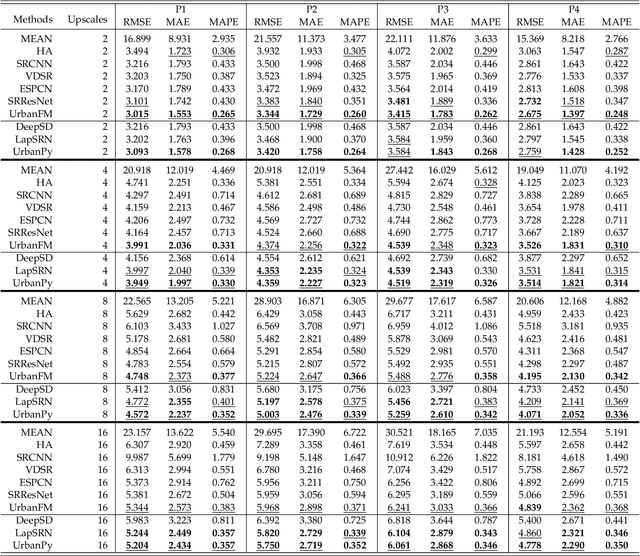
The ubiquitous deployment of monitoring devices in urban flow monitoring systems induces a significant cost for maintenance and operation. A technique is required to reduce the number of deployed devices, while preventing the degeneration of data accuracy and granularity. In this paper, we present an approach for inferring the real-time and fine-grained crowd flows throughout a city based on coarse-grained observations. This task exhibits two challenges: the spatial correlations between coarse- and fine-grained urban flows, and the complexities of external impacts. To tackle these issues, we develop a model entitled UrbanFM which consists of two major parts: 1) an inference network to generate fine-grained flow distributions from coarse-grained inputs that uses a feature extraction module and a novel distributional upsampling module; 2) a general fusion subnet to further boost the performance by considering the influence of different external factors. This structure provides outstanding effectiveness and efficiency for small scale upsampling. However, the single-pass upsampling used by UrbanFM is insufficient at higher upscaling rates. Therefore, we further present UrbanPy, a cascading model for progressive inference of fine-grained urban flows by decomposing the original tasks into multiple subtasks. Compared to UrbanFM, such an enhanced structure demonstrates favorable performance for larger-scale inference tasks.