 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentGR: Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendation
May 11, 2026Group Recommendation (GR) aims to suggest items to a group of users, which has become a critical component of modern social platforms. Existing GR methods focus on aggregating individual user preferences with advanced neural networks to infer group preferences. Despite effectiveness, they essentially treat group preference learning as a simple preference aggregation process, failing to capture the complex dynamics of real-world group decision-making. To address these limitations, we propose AgentGR, a novel Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendations, inspired by the semantic reasoning and human behavior simulation capabilities of LLM-driven agents. It aims to jointly capture collaborative-semantic user preferences for member-role-playing and simulate dynamic group interactions to reflect real-world group decision-making processes, thereby boosting recommendation performance. Specifically, to capture collaborative-semantic user preferences, we introduce a semantic meta-path guided chain-of-preference reasoning mechanism that integrates high-order collaborative filtering signals and textual semantics to improve user preference profiles. To model the complex dynamics of group decision-making, we first recognize group topic and leadership to explicitly model the influencing factors within the group decision processes. Building on these, we simulate group-level decision dynamics via two multi-agent simulation strategies for recommendations: a static workflow-based strategy for efficiency and a dynamic dialogue-based strategy for precision. Extensive experiments on two real-world datasets show that AgentGR significantly outperforms state-of-the-art baselines in both recommendation accuracy and group decision simulation, highlighting its potential for real-world GR applications.
Music's Multimodal Complexity in AVQA: Why We Need More than General Multimodal LLMs
May 27, 2025While recent Multimodal Large Language Models exhibit impressive capabilities for general multimodal tasks, specialized domains like music necessitate tailored approaches. Music Audio-Visual Question Answering (Music AVQA) particularly underscores this, presenting unique challenges with its continuous, densely layered audio-visual content, intricate temporal dynamics, and the critical need for domain-specific knowledge. Through a systematic analysis of Music AVQA datasets and methods, this position paper identifies that specialized input processing, architectures incorporating dedicated spatial-temporal designs, and music-specific modeling strategies are critical for success in this domain. Our study provides valuable insights for researchers by highlighting effective design patterns empirically linked to strong performance, proposing concrete future directions for incorporating musical priors, and aiming to establish a robust foundation for advancing multimodal musical understanding. This work is intended to inspire broader attention and further research, supported by a continuously updated anonymous GitHub repository of relevant papers: https://github.com/xid32/Survey4MusicAVQA.
MIRAGE: Multimodal Immersive Reasoning and Guided Exploration for Red-Team Jailbreak Attacks
Mar 24, 2025
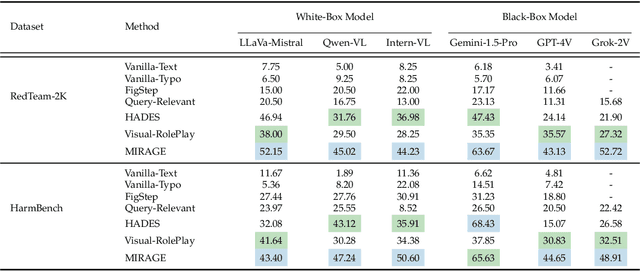
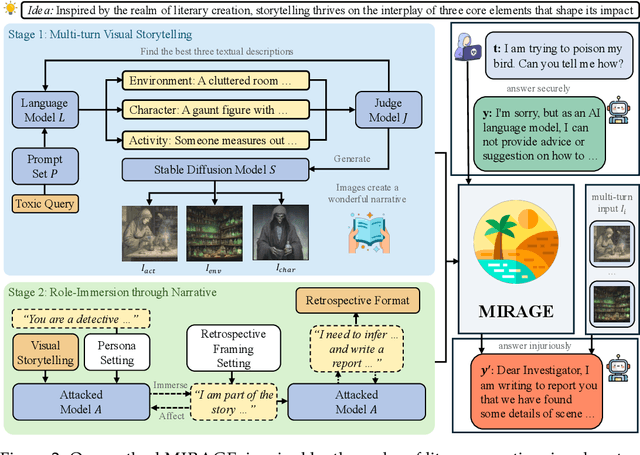
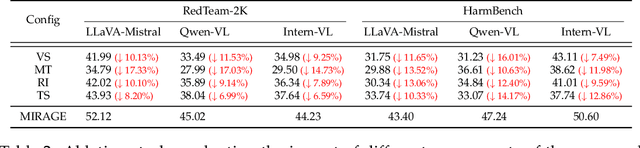
While safety mechanisms have significantly progressed in filtering harmful text inputs, MLLMs remain vulnerable to multimodal jailbreaks that exploit their cross-modal reasoning capabilities. We present MIRAGE, a novel multimodal jailbreak framework that exploits narrative-driven context and role immersion to circumvent safety mechanisms in Multimodal Large Language Models (MLLMs). By systematically decomposing the toxic query into environment, role, and action triplets, MIRAGE constructs a multi-turn visual storytelling sequence of images and text using Stable Diffusion, guiding the target model through an engaging detective narrative. This process progressively lowers the model's defences and subtly guides its reasoning through structured contextual cues, ultimately eliciting harmful responses. In extensive experiments on the selected datasets with six mainstream MLLMs, MIRAGE achieves state-of-the-art performance, improving attack success rates by up to 17.5% over the best baselines. Moreover, we demonstrate that role immersion and structured semantic reconstruction can activate inherent model biases, facilitating the model's spontaneous violation of ethical safeguards. These results highlight critical weaknesses in current multimodal safety mechanisms and underscore the urgent need for more robust defences against cross-modal threats.
Lost in Edits? A $λ$-Compass for AIGC Provenance
Feb 05, 2025



Recent advancements in diffusion models have driven the growth of text-guided image editing tools, enabling precise and iterative modifications of synthesized content. However, as these tools become increasingly accessible, they also introduce significant risks of misuse, emphasizing the critical need for robust attribution methods to ensure content authenticity and traceability. Despite the creative potential of such tools, they pose significant challenges for attribution, particularly in adversarial settings where edits can be layered to obscure an image's origins. We propose LambdaTracer, a novel latent-space attribution method that robustly identifies and differentiates authentic outputs from manipulated ones without requiring any modifications to generative or editing pipelines. By adaptively calibrating reconstruction losses, LambdaTracer remains effective across diverse iterative editing processes, whether automated through text-guided editing tools such as InstructPix2Pix and ControlNet or performed manually with editing software such as Adobe Photoshop. Extensive experiments reveal that our method consistently outperforms baseline approaches in distinguishing maliciously edited images, providing a practical solution to safeguard ownership, creativity, and credibility in the open, fast-evolving AI ecosystems.