 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInception Convolution with Efficient Dilation Search
Dec 25, 2020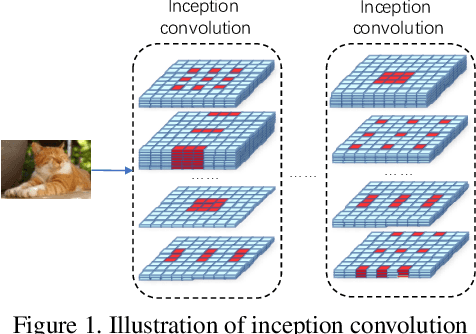
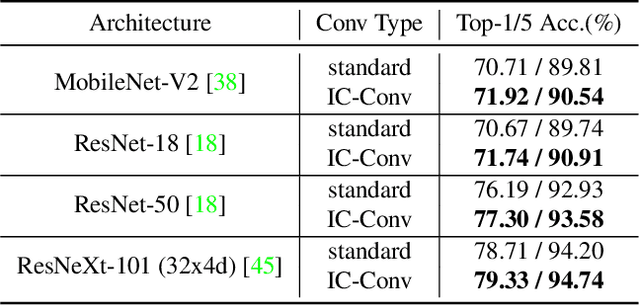
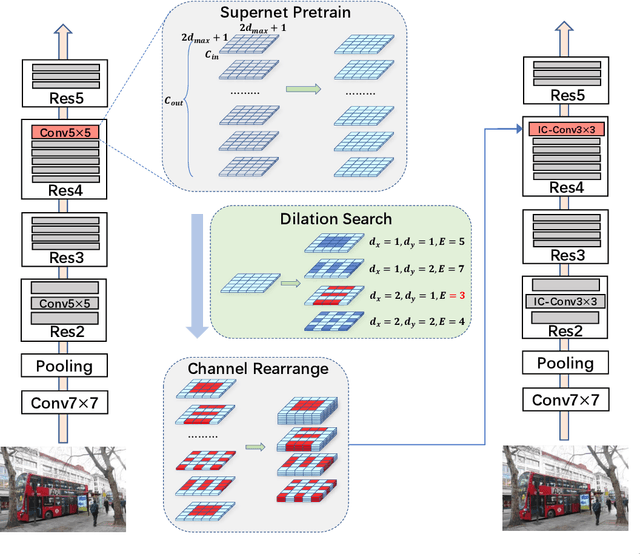

Dilation convolution is a critical mutant of standard convolution neural network to control effective receptive fields and handle large scale variance of objects without introducing additional computation. However, fitting the effective reception field to data with dilated convolution is less discussed in the literature. To fully explore its potentials, we proposed a new mutant of dilated convolution, namely inception (dilated) convolution where the convolutions have independent dilation among different axes, channels and layers. To explore a practical method for fitting the complex inception convolution to the data, a simple while effective dilation search algorithm(EDO) based on statistical optimization is developed. The search method operates in a zero-cost manner which is extremely fast to apply on large scale datasets. Empirical results reveal that our method obtains consistent performance gains in an extensive range of benchmarks. For instance, by simply replace the 3 x 3 standard convolutions in ResNet-50 backbone with inception convolution, we improve the mAP of Faster-RCNN on MS-COCO from 36.4% to 39.2%. Furthermore, using the same replacement in ResNet-101 backbone, we achieve a huge improvement over AP score from 60.2% to 68.5% on COCO val2017 for the bottom up human pose estimation.
DETR for Pedestrian Detection
Dec 12, 2020
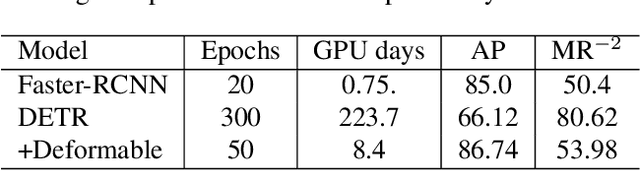
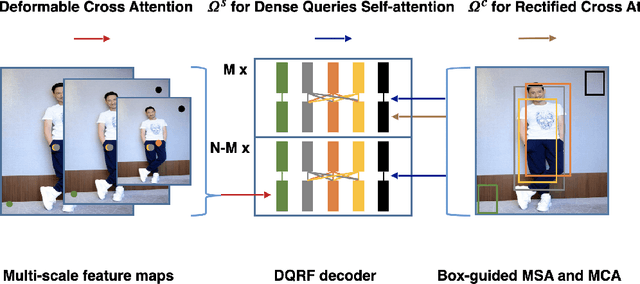

Pedestrian detection in crowd scenes poses a challenging problem due to the heuristic defined mapping from anchors to pedestrians and the conflict between NMS and highly overlapped pedestrians. The recently proposed end-to-end detectors(ED), DETR and deformable DETR, replace hand designed components such as NMS and anchors using the transformer architecture, which gets rid of duplicate predictions by computing all pairwise interactions between queries. Inspired by these works, we explore their performance on crowd pedestrian detection. Surprisingly, compared to Faster-RCNN with FPN, the results are opposite to those obtained on COCO. Furthermore, the bipartite match of ED harms the training efficiency due to the large ground truth number in crowd scenes. In this work, we identify the underlying motives driving ED's poor performance and propose a new decoder to address them. Moreover, we design a mechanism to leverage the less occluded visible parts of pedestrian specifically for ED, and achieve further improvements. A faster bipartite match algorithm is also introduced to make ED training on crowd dataset more practical. The proposed detector PED(Pedestrian End-to-end Detector) outperforms both previous EDs and the baseline Faster-RCNN on CityPersons and CrowdHuman. It also achieves comparable performance with state-of-the-art pedestrian detection methods. Code will be released soon.
Context-Aware Graph Convolution Network for Target Re-identification
Dec 09, 2020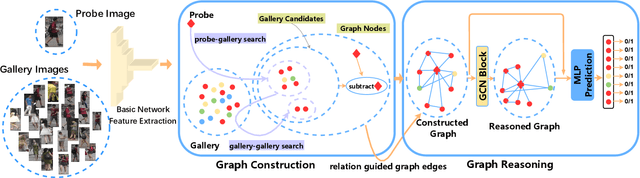
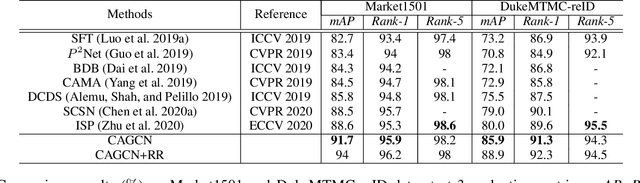

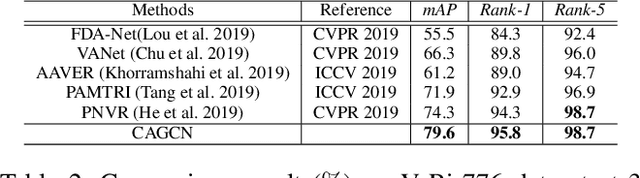
Most existing re-identification methods focus on learning robust and discriminative features with deep convolution networks. However, many of them consider content similarity separately and fail to utilize the context information of the query and gallery sets, e.g. probe-gallery and gallery-gallery relations, thus hard samples may not be well solved due tothe limited or even misleading information. In this paper,we present a novel Context-Aware Graph Convolution Net-work (CAGCN), where the probe-gallery relations are encoded into the graph nodes and the graph edge connections are well controlled by the gallery-gallery relations. In this way, hard samples can be addressed with the context information flows among other easy samples during the graph reasoning. Specifically, we adopt an effective hard gallery sampler to obtain high recall for positive samples while keeping a reasonable graph size, which can also weaken the imbalanced problem in training process with low computation complexity. Experiments show that the proposed method achieves state-of-the-art performance on both person and vehicle re-identification datasets in a plug and play fashion with limited overhead.
PV-NAS: Practical Neural Architecture Search for Video Recognition
Nov 03, 2020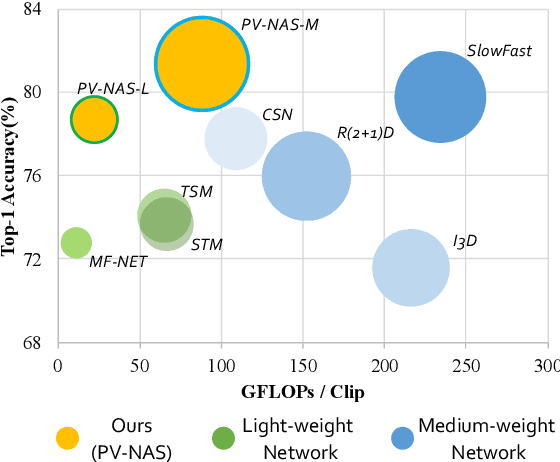
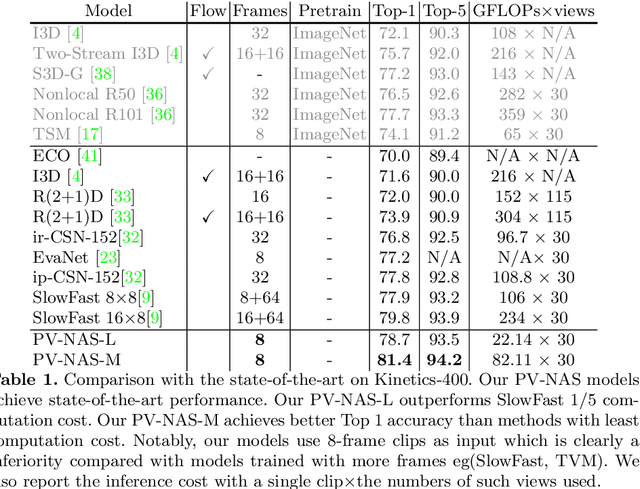
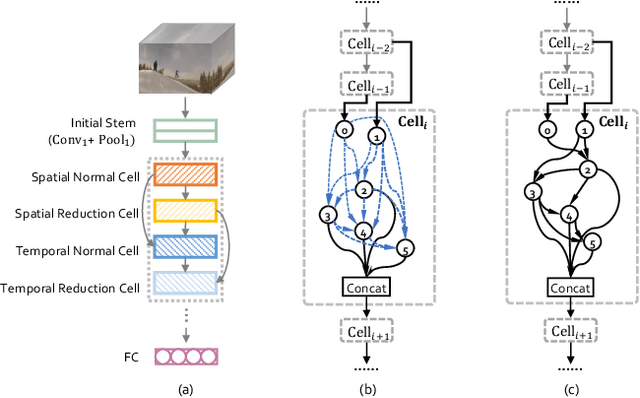

Recently, deep learning has been utilized to solve video recognition problem due to its prominent representation ability. Deep neural networks for video tasks is highly customized and the design of such networks requires domain experts and costly trial and error tests. Recent advance in network architecture search has boosted the image recognition performance in a large margin. However, automatic designing of video recognition network is less explored. In this study, we propose a practical solution, namely Practical Video Neural Architecture Search (PV-NAS).Our PV-NAS can efficiently search across tremendous large scale of architectures in a novel spatial-temporal network search space using the gradient based search methods. To avoid sticking into sub-optimal solutions, we propose a novel learning rate scheduler to encourage sufficient network diversity of the searched models. Extensive empirical evaluations show that the proposed PV-NAS achieves state-of-the-art performance with much fewer computational resources. 1) Within light-weight models, our PV-NAS-L achieves 78.7% and 62.5% Top-1 accuracy on Kinetics-400 and Something-Something V2, which are better than previous state-of-the-art methods (i.e., TSM) with a large margin (4.6% and 3.4% on each dataset, respectively), and 2) among median-weight models, our PV-NAS-M achieves the best performance (also a new record)in the Something-Something V2 dataset.
Improving Auto-Augment via Augmentation-Wise Weight Sharing
Oct 22, 2020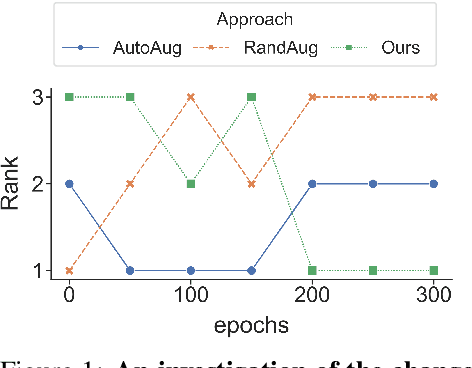
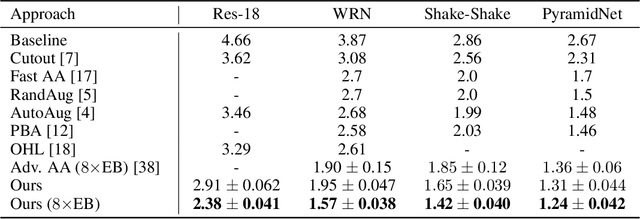
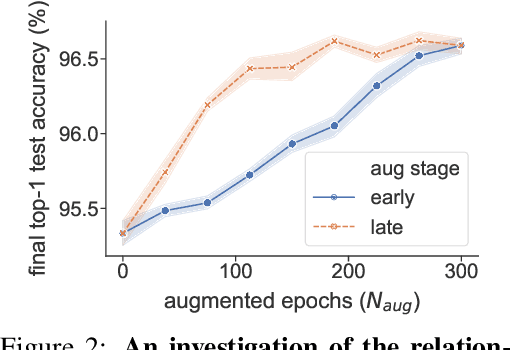
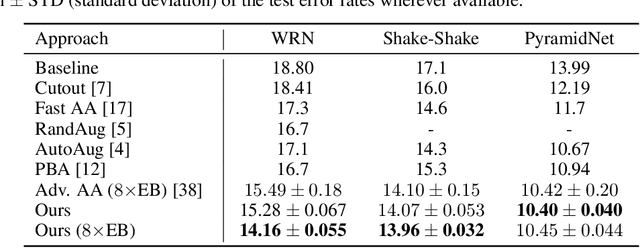
The recent progress on automatically searching augmentation policies has boosted the performance substantially for various tasks. A key component of automatic augmentation search is the evaluation process for a particular augmentation policy, which is utilized to return reward and usually runs thousands of times. A plain evaluation process, which includes full model training and validation, would be time-consuming. To achieve efficiency, many choose to sacrifice evaluation reliability for speed. In this paper, we dive into the dynamics of augmented training of the model. This inspires us to design a powerful and efficient proxy task based on the Augmentation-Wise Weight Sharing (AWS) to form a fast yet accurate evaluation process in an elegant way. Comprehensive analysis verifies the superiority of this approach in terms of effectiveness and efficiency. The augmentation policies found by our method achieve superior accuracies compared with existing auto-augmentation search methods. On CIFAR-10, we achieve a top-1 error rate of 1.24%, which is currently the best performing single model without extra training data. On ImageNet, we get a top-1 error rate of 20.36% for ResNet-50, which leads to 3.34% absolute error rate reduction over the baseline augmentation.
Adaptive Gradient Method with Resilience and Momentum
Oct 21, 2020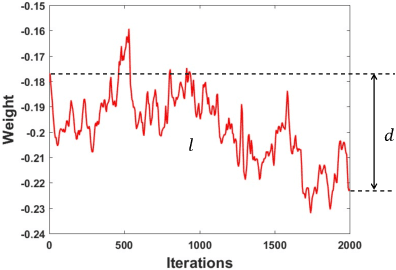
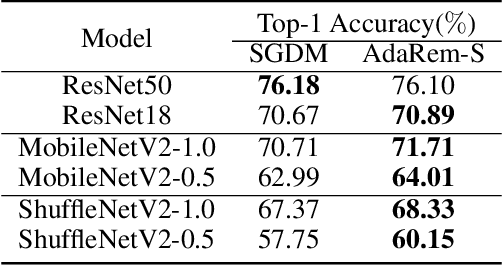
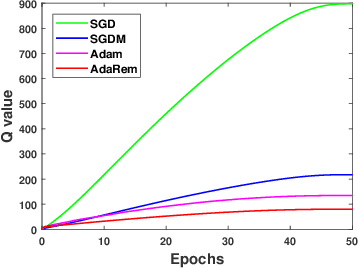

Several variants of stochastic gradient descent (SGD) have been proposed to improve the learning effectiveness and efficiency when training deep neural networks, among which some recent influential attempts would like to adaptively control the parameter-wise learning rate (e.g., Adam and RMSProp). Although they show a large improvement in convergence speed, most adaptive learning rate methods suffer from compromised generalization compared with SGD. In this paper, we proposed an Adaptive Gradient Method with Resilience and Momentum (AdaRem), motivated by the observation that the oscillations of network parameters slow the training, and give a theoretical proof of convergence. For each parameter, AdaRem adjusts the parameter-wise learning rate according to whether the direction of one parameter changes in the past is aligned with the direction of the current gradient, and thus encourages long-term consistent parameter updating with much fewer oscillations. Comprehensive experiments have been conducted to verify the effectiveness of AdaRem when training various models on a large-scale image recognition dataset, e.g., ImageNet, which also demonstrate that our method outperforms previous adaptive learning rate-based algorithms in terms of the training speed and the test error, respectively.
Once Quantized for All: Progressively Searching for Quantized Efficient Models
Oct 09, 2020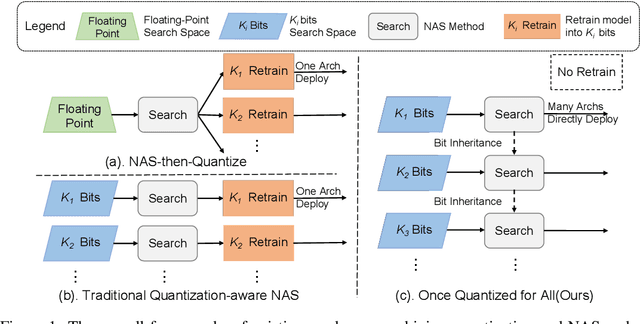

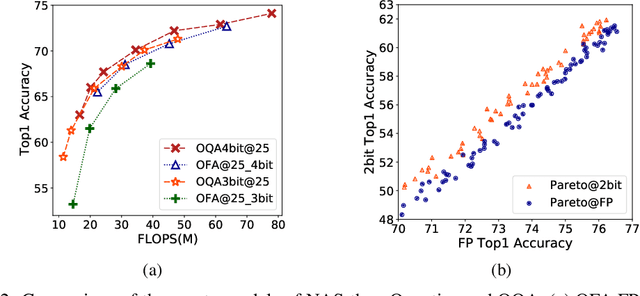
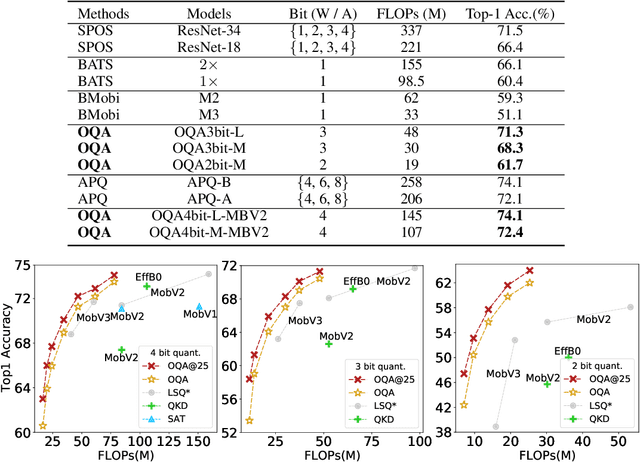
Automatic search of Quantized Neural Networks has attracted a lot of attention. However, the existing quantization aware Neural Architecture Search (NAS) approaches inherit a two-stage search-retrain schema, which is not only time-consuming but also adversely affected by the unreliable ranking of architectures during the search. To avoid the undesirable effect of the search-retrain schema, we present Once Quantized for All (OQA), a novel framework that searches for quantized efficient models and deploys their quantized weights at the same time without additional post-process. While supporting a huge architecture search space, our OQA can produce a series of ultra-low bit-width(e.g. 4/3/2 bit) quantized efficient models. A progressive bit inheritance procedure is introduced to support ultra-low bit-width. Our discovered model family, OQANets, achieves a new state-of-the-art (SOTA) on quantized efficient models compared with various quantization methods and bit-widths. In particular, OQA2bit-L achieves 64.0% ImageNet Top-1 accuracy, outperforming its 2-bit counterpart EfficientNet-B0@QKD by a large margin of 14% using 30% less computation budget. Code is available at https://github.com/LaVieEnRoseSMZ/OQA.
Dynamic Graph: Learning Instance-aware Connectivity for Neural Networks
Oct 02, 2020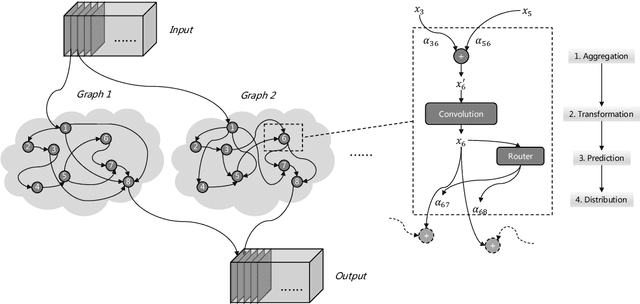
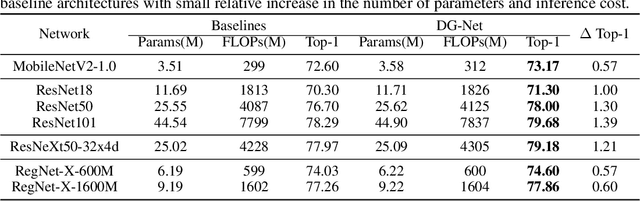
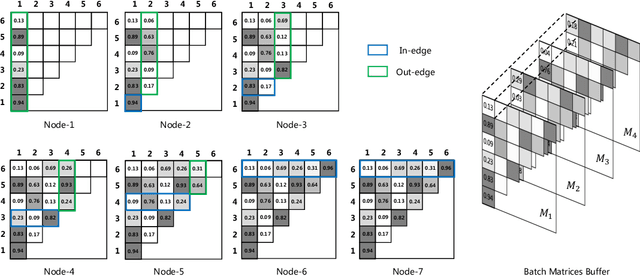
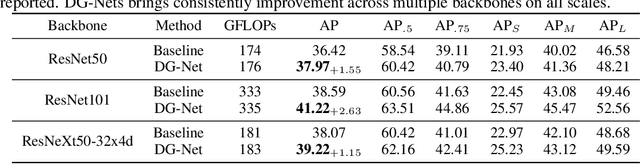
One practice of employing deep neural networks is to apply the same architecture to all the input instances. However, a fixed architecture may not be representative enough for data with high diversity. To promote the model capacity, existing approaches usually employ larger convolutional kernels or deeper network structure, which may increase the computational cost. In this paper, we address this issue by raising the Dynamic Graph Network (DG-Net). The network learns the instance-aware connectivity, which creates different forward paths for different instances. Specifically, the network is initialized as a complete directed acyclic graph, where the nodes represent convolutional blocks and the edges represent the connection paths. We generate edge weights by a learnable module \textit{router} and select the edges whose weights are larger than a threshold, to adjust the connectivity of the neural network structure. Instead of using the same path of the network, DG-Net aggregates features dynamically in each node, which allows the network to have more representation ability. To facilitate the training, we represent the network connectivity of each sample in an adjacency matrix. The matrix is updated to aggregate features in the forward pass, cached in the memory, and used for gradient computing in the backward pass. We verify the effectiveness of our method with several static architectures, including MobileNetV2, ResNet, ResNeXt, and RegNet. Extensive experiments are performed on ImageNet classification and COCO object detection, which shows the effectiveness and generalization ability of our approach.
MimicDet: Bridging the Gap Between One-Stage and Two-Stage Object Detection
Sep 24, 2020
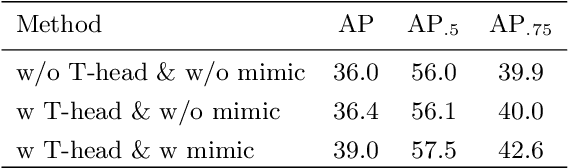
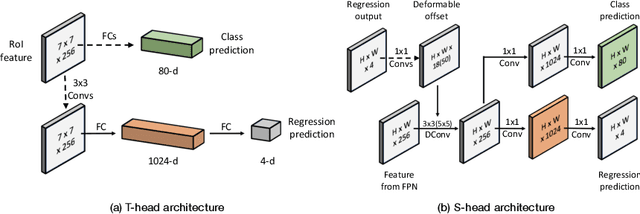
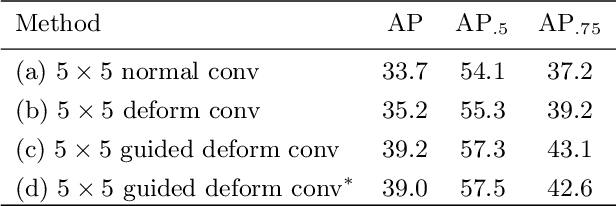
Modern object detection methods can be divided into one-stage approaches and two-stage ones. One-stage detectors are more efficient owing to straightforward architectures, but the two-stage detectors still take the lead in accuracy. Although recent work try to improve the one-stage detectors by imitating the structural design of the two-stage ones, the accuracy gap is still significant. In this paper, we propose MimicDet, a novel and efficient framework to train a one-stage detector by directly mimic the two-stage features, aiming to bridge the accuracy gap between one-stage and two-stage detectors. Unlike conventional mimic methods, MimicDet has a shared backbone for one-stage and two-stage detectors, then it branches into two heads which are well designed to have compatible features for mimicking. Thus MimicDet can be end-to-end trained without the pre-train of the teacher network. And the cost does not increase much, which makes it practical to adopt large networks as backbones. We also make several specialized designs such as dual-path mimicking and staggered feature pyramid to facilitate the mimicking process. Experiments on the challenging COCO detection benchmark demonstrate the effectiveness of MimicDet. It achieves 46.1 mAP with ResNeXt-101 backbone on the COCO test-dev set, which significantly surpasses current state-of-the-art methods.
Collaborative Distillation in the Parameter and Spectrum Domains for Video Action Recognition
Sep 15, 2020
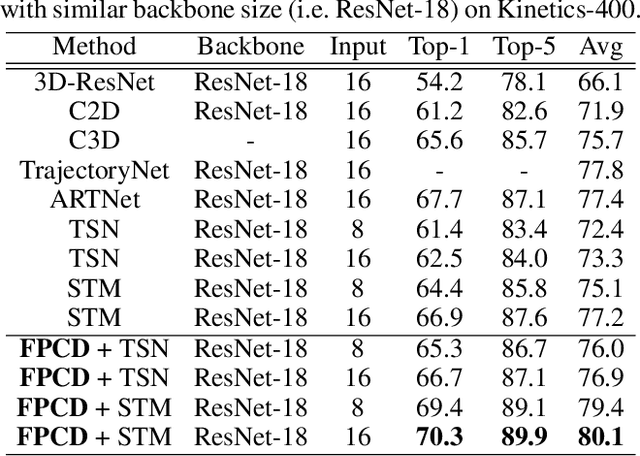
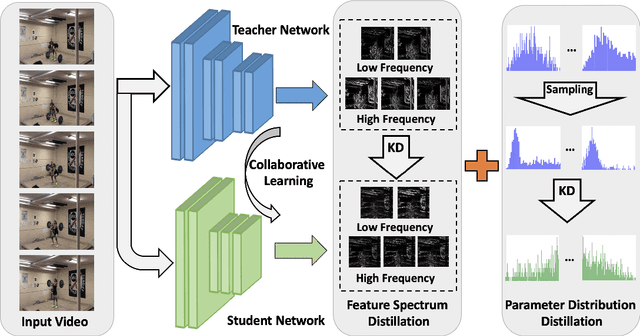
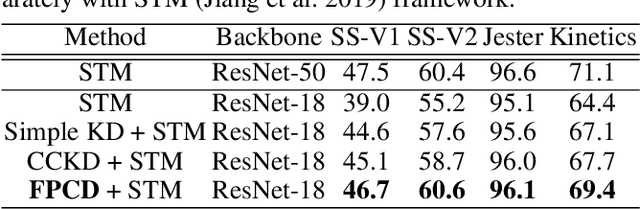
Recent years have witnessed the significant progress of action recognition task with deep networks. However, most of current video networks require large memory and computational resources, which hinders their applications in practice. Existing knowledge distillation methods are limited to the image-level spatial domain, ignoring the temporal and frequency information which provide structural knowledge and are important for video analysis. This paper explores how to train small and efficient networks for action recognition. Specifically, we propose two distillation strategies in the frequency domain, namely the feature spectrum and parameter distribution distillations respectively. Our insight is that appealing performance of action recognition requires \textit{explicitly} modeling the temporal frequency spectrum of video features. Therefore, we introduce a spectrum loss that enforces the student network to mimic the temporal frequency spectrum from the teacher network, instead of \textit{implicitly} distilling features as many previous works. Second, the parameter frequency distribution is further adopted to guide the student network to learn the appearance modeling process from the teacher. Besides, a collaborative learning strategy is presented to optimize the training process from a probabilistic view. Extensive experiments are conducted on several action recognition benchmarks, such as Kinetics, Something-Something, and Jester, which consistently verify effectiveness of our approach, and demonstrate that our method can achieve higher performance than state-of-the-art methods with the same backbone.