 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model
Jun 22, 2024



Diffusion models have obtained substantial progress in image-to-video (I2V) generation. However, such models are not fully understood. In this paper, we report a significant but previously overlooked issue in I2V diffusion models (I2V-DMs), namely, conditional image leakage. I2V-DMs tend to over-rely on the conditional image at large time steps, neglecting the crucial task of predicting the clean video from noisy inputs, which results in videos lacking dynamic and vivid motion. We further address this challenge from both inference and training aspects by presenting plug-and-play strategies accordingly. First, we introduce a training-free inference strategy that starts the generation process from an earlier time step to avoid the unreliable late-time steps of I2V-DMs, as well as an initial noise distribution with optimal analytic expressions (Analytic-Init) by minimizing the KL divergence between it and the actual marginal distribution to effectively bridge the training-inference gap. Second, to mitigate conditional image leakage during training, we design a time-dependent noise distribution for the conditional image, which favors high noise levels at large time steps to sufficiently interfere with the conditional image. We validate these strategies on various I2V-DMs using our collected open-domain image benchmark and the UCF101 dataset. Extensive results demonstrate that our methods outperform baselines by producing videos with more dynamic and natural motion without compromising image alignment and temporal consistency. The project page: \url{https://cond-image-leak.github.io/}.
Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study
Jun 11, 2024



Despite the superior capabilities of Multimodal Large Language Models (MLLMs) across diverse tasks, they still face significant trustworthiness challenges. Yet, current literature on the assessment of trustworthy MLLMs remains limited, lacking a holistic evaluation to offer thorough insights into future improvements. In this work, we establish MultiTrust, the first comprehensive and unified benchmark on the trustworthiness of MLLMs across five primary aspects: truthfulness, safety, robustness, fairness, and privacy. Our benchmark employs a rigorous evaluation strategy that addresses both multimodal risks and cross-modal impacts, encompassing 32 diverse tasks with self-curated datasets. Extensive experiments with 21 modern MLLMs reveal some previously unexplored trustworthiness issues and risks, highlighting the complexities introduced by the multimodality and underscoring the necessity for advanced methodologies to enhance their reliability. For instance, typical proprietary models still struggle with the perception of visually confusing images and are vulnerable to multimodal jailbreaking and adversarial attacks; MLLMs are more inclined to disclose privacy in text and reveal ideological and cultural biases even when paired with irrelevant images in inference, indicating that the multimodality amplifies the internal risks from base LLMs. Additionally, we release a scalable toolbox for standardized trustworthiness research, aiming to facilitate future advancements in this important field. Code and resources are publicly available at: https://multi-trust.github.io/.
Freeplane: Unlocking Free Lunch in Triplane-Based Sparse-View Reconstruction Models
Jun 02, 2024Creating 3D assets from single-view images is a complex task that demands a deep understanding of the world. Recently, feed-forward 3D generative models have made significant progress by training large reconstruction models on extensive 3D datasets, with triplanes being the preferred 3D geometry representation. However, effectively utilizing the geometric priors of triplanes, while minimizing artifacts caused by generated inconsistent multi-view images, remains a challenge. In this work, we present \textbf{Fre}quency modulat\textbf{e}d tri\textbf{plane} (\textbf{Freeplane}), a simple yet effective method to improve the generation quality of feed-forward models without additional training. We first analyze the role of triplanes in feed-forward methods and find that the inconsistent multi-view images introduce high-frequency artifacts on triplanes, leading to low-quality 3D meshes. Based on this observation, we propose strategically filtering triplane features and combining triplanes before and after filtering to produce high-quality textured meshes. These techniques incur no additional cost and can be seamlessly integrated into pre-trained feed-forward models to enhance their robustness against the inconsistency of generated multi-view images. Both qualitative and quantitative results demonstrate that our method improves the performance of feed-forward models by simply modulating triplanes. All you need is to modulate the triplanes during inference.
Fourier Controller Networks for Real-Time Decision-Making in Embodied Learning
May 30, 2024Reinforcement learning is able to obtain generalized low-level robot policies on diverse robotics datasets in embodied learning scenarios, and Transformer has been widely used to model time-varying features. However, it still suffers from the issues of low data efficiency and high inference latency. In this paper, we propose to investigate the task from a new perspective of the frequency domain. We first observe that the energy density in the frequency domain of a robot's trajectory is mainly concentrated in the low-frequency part. Then, we present the Fourier Controller Network (FCNet), a new network that utilizes the Short-Time Fourier Transform (STFT) to extract and encode time-varying features through frequency domain interpolation. We further achieve parallel training and efficient recurrent inference by using FFT and Sliding DFT methods in the model architecture for real-time decision-making. Comprehensive analyses in both simulated (e.g., D4RL) and real-world environments (e.g., robot locomotion) demonstrate FCNet's substantial efficiency and effectiveness over existing methods such as Transformer, e.g., FCNet outperforms Transformer on multi-environmental robotics datasets of all types of sizes (from 1.9M to 120M). The project page and code can be found https://thkkk.github.io/fcnet.
Accurate and Reliable Predictions with Mutual-Transport Ensemble
May 30, 2024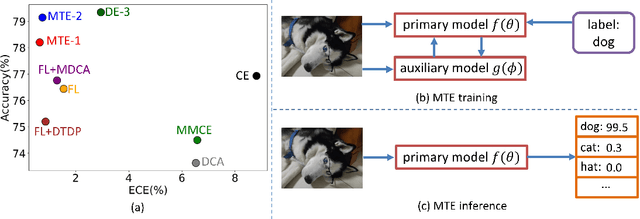
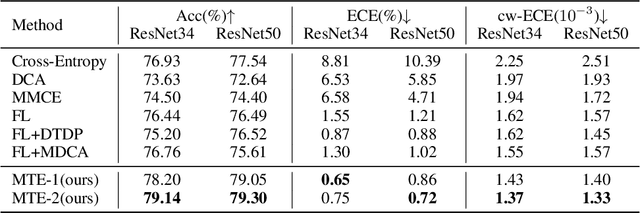
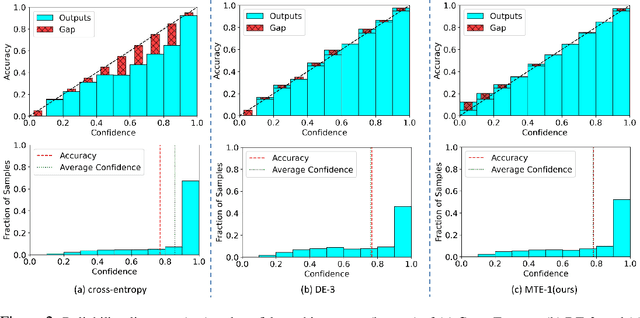
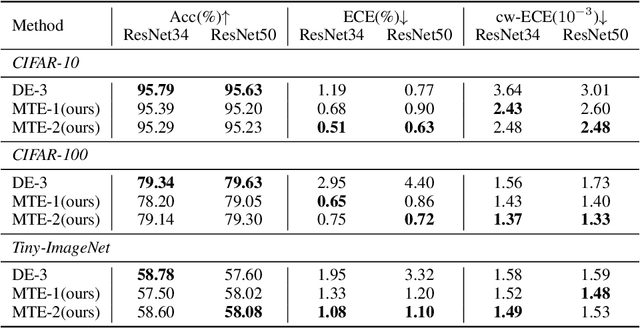
Deep Neural Networks (DNNs) have achieved remarkable success in a variety of tasks, especially when it comes to prediction accuracy. However, in complex real-world scenarios, particularly in safety-critical applications, high accuracy alone is not enough. Reliable uncertainty estimates are crucial. Modern DNNs, often trained with cross-entropy loss, tend to be overconfident, especially with ambiguous samples. To improve uncertainty calibration, many techniques have been developed, but they often compromise prediction accuracy. To tackle this challenge, we propose the ``mutual-transport ensemble'' (MTE). This approach introduces a co-trained auxiliary model and adaptively regularizes the cross-entropy loss using Kullback-Leibler (KL) divergence between the prediction distributions of the primary and auxiliary models. We conducted extensive studies on various benchmarks to validate the effectiveness of our method. The results show that MTE can simultaneously enhance both accuracy and uncertainty calibration. For example, on the CIFAR-100 dataset, our MTE method on ResNet34/50 achieved significant improvements compared to previous state-of-the-art method, with absolute accuracy increases of 2.4%/3.7%, relative reductions in ECE of $42.3%/29.4%, and relative reductions in classwise-ECE of 11.6%/15.3%.
Efficient Black-box Adversarial Attacks via Bayesian Optimization Guided by a Function Prior
May 29, 2024This paper studies the challenging black-box adversarial attack that aims to generate adversarial examples against a black-box model by only using output feedback of the model to input queries. Some previous methods improve the query efficiency by incorporating the gradient of a surrogate white-box model into query-based attacks due to the adversarial transferability. However, the localized gradient is not informative enough, making these methods still query-intensive. In this paper, we propose a Prior-guided Bayesian Optimization (P-BO) algorithm that leverages the surrogate model as a global function prior in black-box adversarial attacks. As the surrogate model contains rich prior information of the black-box one, P-BO models the attack objective with a Gaussian process whose mean function is initialized as the surrogate model's loss. Our theoretical analysis on the regret bound indicates that the performance of P-BO may be affected by a bad prior. Therefore, we further propose an adaptive integration strategy to automatically adjust a coefficient on the function prior by minimizing the regret bound. Extensive experiments on image classifiers and large vision-language models demonstrate the superiority of the proposed algorithm in reducing queries and improving attack success rates compared with the state-of-the-art black-box attacks. Code is available at https://github.com/yibo-miao/PBO-Attack.
PivotMesh: Generic 3D Mesh Generation via Pivot Vertices Guidance
May 27, 2024



Generating compact and sharply detailed 3D meshes poses a significant challenge for current 3D generative models. Different from extracting dense meshes from neural representation, some recent works try to model the native mesh distribution (i.e., a set of triangles), which generates more compact results as humans crafted. However, due to the complexity and variety of mesh topology, these methods are typically limited to small datasets with specific categories and are hard to extend. In this paper, we introduce a generic and scalable mesh generation framework PivotMesh, which makes an initial attempt to extend the native mesh generation to large-scale datasets. We employ a transformer-based auto-encoder to encode meshes into discrete tokens and decode them from face level to vertex level hierarchically. Subsequently, to model the complex typology, we first learn to generate pivot vertices as coarse mesh representation and then generate the complete mesh tokens with the same auto-regressive Transformer. This reduces the difficulty compared with directly modeling the mesh distribution and further improves the model controllability. PivotMesh demonstrates its versatility by effectively learning from both small datasets like Shapenet, and large-scale datasets like Objaverse and Objaverse-xl. Extensive experiments indicate that PivotMesh can generate compact and sharp 3D meshes across various categories, highlighting its great potential for native mesh modeling.
On Mesa-Optimization in Autoregressively Trained Transformers: Emergence and Capability
May 27, 2024



Autoregressively trained transformers have brought a profound revolution to the world, especially with their in-context learning (ICL) ability to address downstream tasks. Recently, several studies suggest that transformers learn a mesa-optimizer during autoregressive (AR) pretraining to implement ICL. Namely, the forward pass of the trained transformer is equivalent to optimizing an inner objective function in-context. However, whether the practical non-convex training dynamics will converge to the ideal mesa-optimizer is still unclear. Towards filling this gap, we investigate the non-convex dynamics of a one-layer linear causal self-attention model autoregressively trained by gradient flow, where the sequences are generated by an AR process $x_{t+1} = W x_t$. First, under a certain condition of data distribution, we prove that an autoregressively trained transformer learns $W$ by implementing one step of gradient descent to minimize an ordinary least squares (OLS) problem in-context. It then applies the learned $\widehat{W}$ for next-token prediction, thereby verifying the mesa-optimization hypothesis. Next, under the same data conditions, we explore the capability limitations of the obtained mesa-optimizer. We show that a stronger assumption related to the moments of data is the sufficient and necessary condition that the learned mesa-optimizer recovers the distribution. Besides, we conduct exploratory analyses beyond the first data condition and prove that generally, the trained transformer will not perform vanilla gradient descent for the OLS problem. Finally, our simulation results verify the theoretical results.
Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels
May 27, 2024Video generative models are receiving particular attention given their ability to generate realistic and imaginative frames. Besides, these models are also observed to exhibit strong 3D consistency, significantly enhancing their potential to act as world simulators. In this work, we present Vidu4D, a novel reconstruction model that excels in accurately reconstructing 4D (i.e., sequential 3D) representations from single generated videos, addressing challenges associated with non-rigidity and frame distortion. This capability is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. At the core of Vidu4D is our proposed Dynamic Gaussian Surfels (DGS) technique. DGS optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. This transformation enables a precise depiction of motion and deformation over time. To preserve the structural integrity of surface-aligned Gaussian surfels, we design the warped-state geometric regularization based on continuous warping fields for estimating normals. Additionally, we learn refinements on rotation and scaling parameters of Gaussian surfels, which greatly alleviates texture flickering during the warping process and enhances the capture of fine-grained appearance details. Vidu4D also contains a novel initialization state that provides a proper start for the warping fields in DGS. Equipping Vidu4D with an existing video generative model, the overall framework demonstrates high-fidelity text-to-4D generation in both appearance and geometry.
Diffusion Bridge Implicit Models
May 24, 2024



Denoising diffusion bridge models (DDBMs) are a powerful variant of diffusion models for interpolating between two arbitrary paired distributions given as endpoints. Despite their promising performance in tasks like image translation, DDBMs require a computationally intensive sampling process that involves the simulation of a (stochastic) differential equation through hundreds of network evaluations. In this work, we present diffusion bridge implicit models (DBIMs) for accelerated sampling of diffusion bridges without extra training. We generalize DDBMs via a class of non-Markovian diffusion bridges defined on the discretized timesteps concerning sampling, which share the same training objective as DDBMs. These generalized diffusion bridges give rise to generative processes ranging from stochastic to deterministic (i.e., an implicit probabilistic model) while being up to 25$\times$ faster than the vanilla sampler of DDBMs. Moreover, the deterministic sampling procedure yielded by DBIMs enables faithful encoding and reconstruction by a booting noise used in the initial sampling step, and allows us to perform semantically meaningful interpolation in image translation tasks by regarding the booting noise as the latent variable.