 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianshou: a Highly Modularized Deep Reinforcement Learning Library
Jul 29, 2021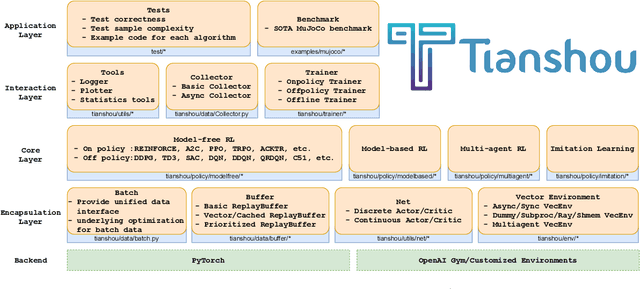

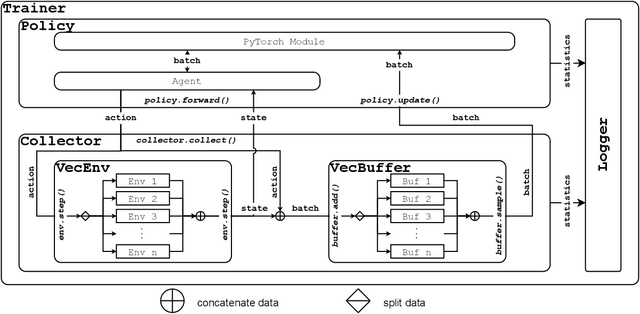

We present Tianshou, a highly modularized python library for deep reinforcement learning (DRL) that uses PyTorch as its backend. Tianshou aims to provide building blocks to replicate common RL experiments and has officially supported more than 15 classic algorithms succinctly. To facilitate related research and prove Tianshou's reliability, we release Tianshou's benchmark of MuJoCo environments, covering 9 classic algorithms and 9/13 Mujoco tasks with state-of-the-art performance. We open-sourced Tianshou at https://github.com/thu-ml/tianshou/, which has received over 3k stars and become one of the most popular PyTorch-based DRL libraries.
Query2Label: A Simple Transformer Way to Multi-Label Classification
Jul 22, 2021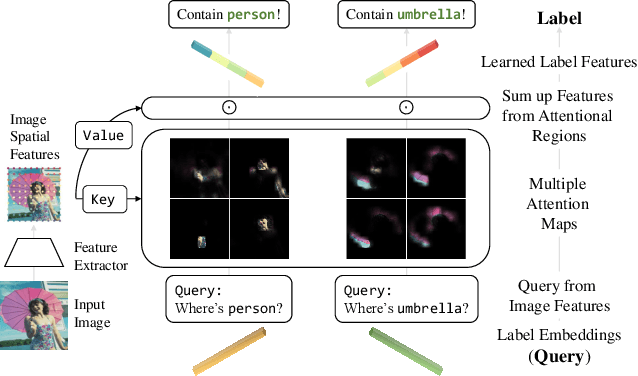
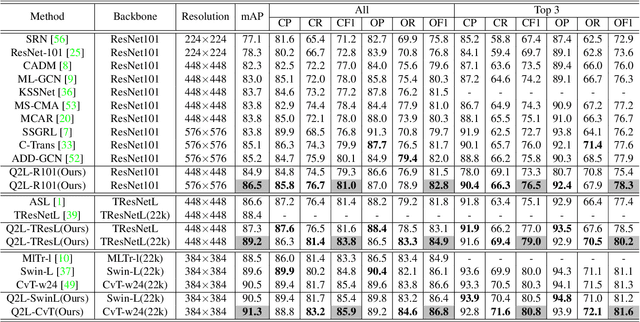
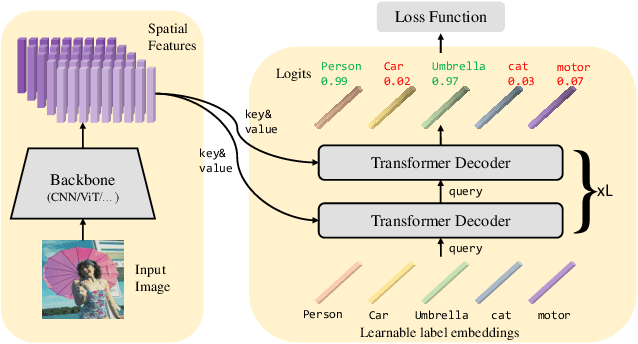
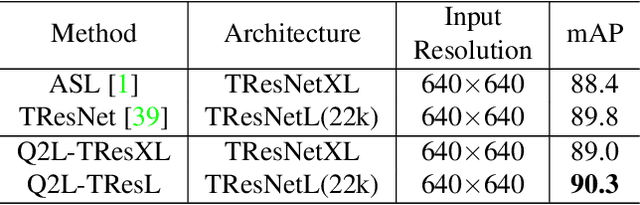
This paper presents a simple and effective approach to solving the multi-label classification problem. The proposed approach leverages Transformer decoders to query the existence of a class label. The use of Transformer is rooted in the need of extracting local discriminative features adaptively for different labels, which is a strongly desired property due to the existence of multiple objects in one image. The built-in cross-attention module in the Transformer decoder offers an effective way to use label embeddings as queries to probe and pool class-related features from a feature map computed by a vision backbone for subsequent binary classifications. Compared with prior works, the new framework is simple, using standard Transformers and vision backbones, and effective, consistently outperforming all previous works on five multi-label classification data sets, including MS-COCO, PASCAL VOC, NUS-WIDE, and Visual Genome. Particularly, we establish $91.3\%$ mAP on MS-COCO. We hope its compact structure, simple implementation, and superior performance serve as a strong baseline for multi-label classification tasks and future studies. The code will be available soon at https://github.com/SlongLiu/query2labels.
On the Convergence of Prior-Guided Zeroth-Order Optimization Algorithms
Jul 21, 2021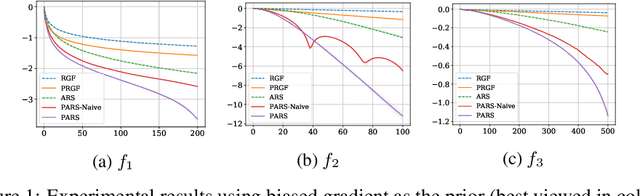
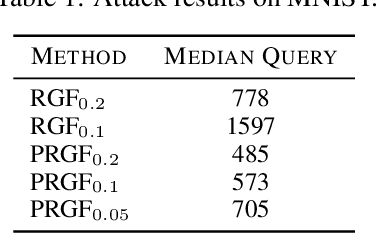
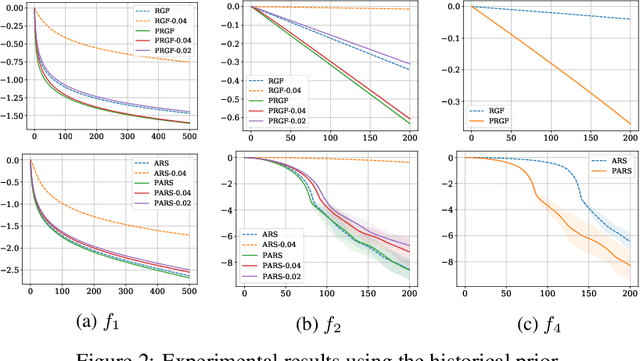
Zeroth-order (ZO) optimization is widely used to handle challenging tasks, such as query-based black-box adversarial attacks and reinforcement learning. Various attempts have been made to integrate prior information into the gradient estimation procedure based on finite differences, with promising empirical results. However, their convergence properties are not well understood. This paper makes an attempt to fill this gap by analyzing the convergence of prior-guided ZO algorithms under a greedy descent framework with various gradient estimators. We provide a convergence guarantee for the prior-guided random gradient-free (PRGF) algorithms. Moreover, to further accelerate over greedy descent methods, we present a new accelerated random search (ARS) algorithm that incorporates prior information, together with a convergence analysis. Finally, our theoretical results are confirmed by experiments on several numerical benchmarks as well as adversarial attacks.
Boosting Transferability of Targeted Adversarial Examples via Hierarchical Generative Networks
Jul 05, 2021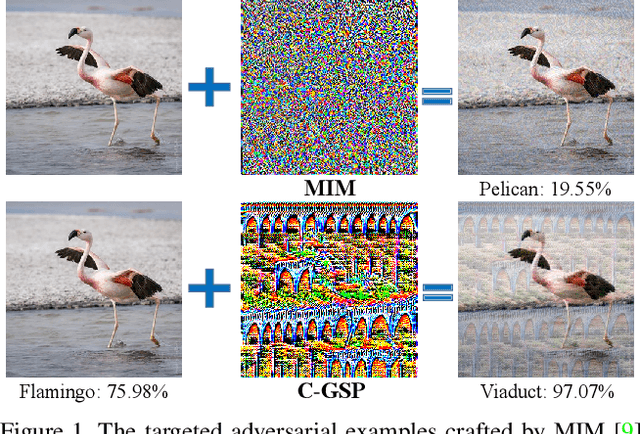
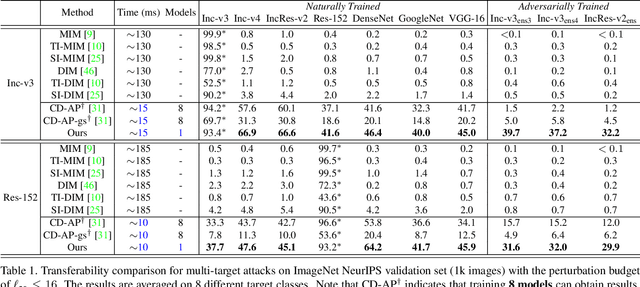
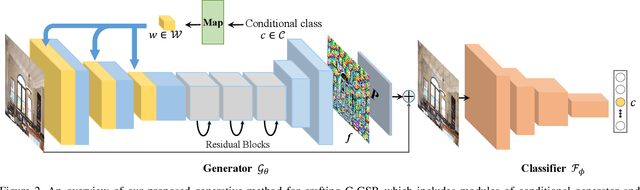
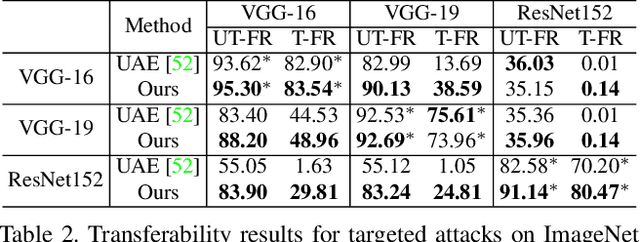
Transfer-based adversarial attacks can effectively evaluate model robustness in the black-box setting. Though several methods have demonstrated impressive transferability of untargeted adversarial examples, targeted adversarial transferability is still challenging. The existing methods either have low targeted transferability or sacrifice computational efficiency. In this paper, we develop a simple yet practical framework to efficiently craft targeted transfer-based adversarial examples. Specifically, we propose a conditional generative attacking model, which can generate the adversarial examples targeted at different classes by simply altering the class embedding and share a single backbone. Extensive experiments demonstrate that our method improves the success rates of targeted black-box attacks by a significant margin over the existing methods -- it reaches an average success rate of 29.6\% against six diverse models based only on one substitute white-box model in the standard testing of NeurIPS 2017 competition, which outperforms the state-of-the-art gradient-based attack methods (with an average success rate of $<$2\%) by a large margin. Moreover, the proposed method is also more efficient beyond an order of magnitude than gradient-based methods.
Understanding Adversarial Attacks on Observations in Deep Reinforcement Learning
Jun 30, 2021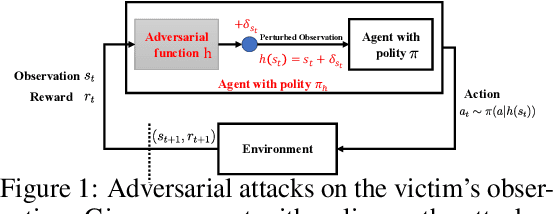
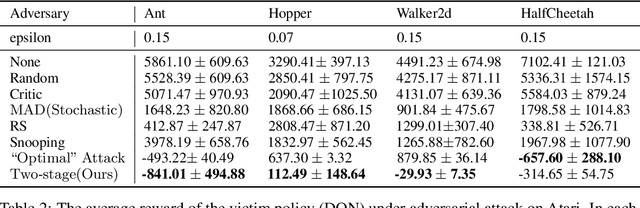
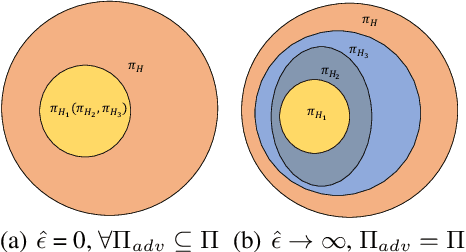
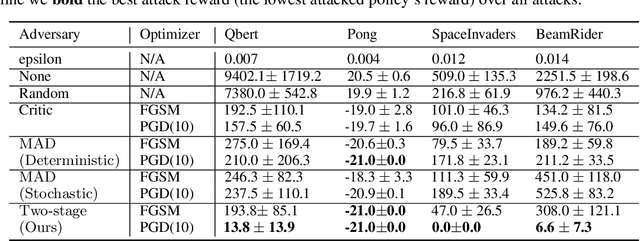
Recent works demonstrate that deep reinforcement learning (DRL) models are vulnerable to adversarial attacks which can decrease the victim's total reward by manipulating the observations. Compared with adversarial attacks in supervised learning, it is much more challenging to deceive a DRL model since the adversary has to infer the environmental dynamics. To address this issue, we reformulate the problem of adversarial attacks in function space and separate the previous gradient based attacks into several subspace. Following the analysis of the function space, we design a generic two-stage framework in the subspace where the adversary lures the agent to a target trajectory or a deceptive policy. In the first stage, we train a deceptive policy by hacking the environment, and discover a set of trajectories routing to the lowest reward. The adversary then misleads the victim to imitate the deceptive policy by perturbing the observations. Our method provides a tighter theoretical upper bound for the attacked agent's performance than the existing approaches. Extensive experiments demonstrate the superiority of our method and we achieve the state-of-the-art performance on both Atari and MuJoCo environments.
Regularized OFU: an Efficient UCB Estimator forNon-linear Contextual Bandit
Jun 29, 2021
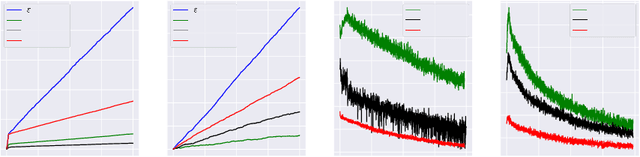
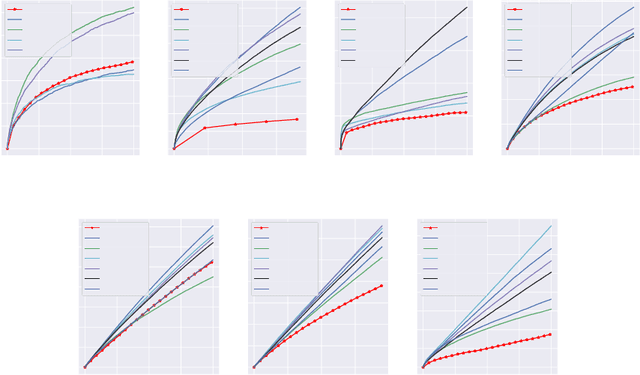

Balancing exploration and exploitation (EE) is a fundamental problem in contex-tual bandit. One powerful principle for EE trade-off isOptimism in Face of Uncer-tainty(OFU), in which the agent takes the action according to an upper confidencebound (UCB) of reward. OFU has achieved (near-)optimal regret bound for lin-ear/kernel contextual bandits. However, it is in general unknown how to deriveefficient and effective EE trade-off methods for non-linearcomplex tasks, suchas contextual bandit with deep neural network as the reward function. In thispaper, we propose a novel OFU algorithm namedregularized OFU(ROFU). InROFU, we measure the uncertainty of the reward by a differentiable function andcompute the upper confidence bound by solving a regularized optimization prob-lem. We prove that, for multi-armed bandit, kernel contextual bandit and neuraltangent kernel bandit, ROFU achieves (near-)optimal regret bounds with certainuncertainty measure, which theoretically justifies its effectiveness on EE trade-off.Importantly, ROFU admits a very efficient implementation with gradient-basedoptimizer, which easily extends to general deep neural network models beyondneural tangent kernel, in sharp contrast with previous OFU methods. The em-pirical evaluation demonstrates that ROFU works extremelywell for contextualbandits under various settings.
Improving Transferability of Adversarial Patches on Face Recognition with Generative Models
Jun 29, 2021
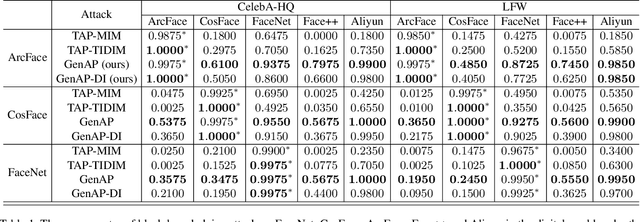
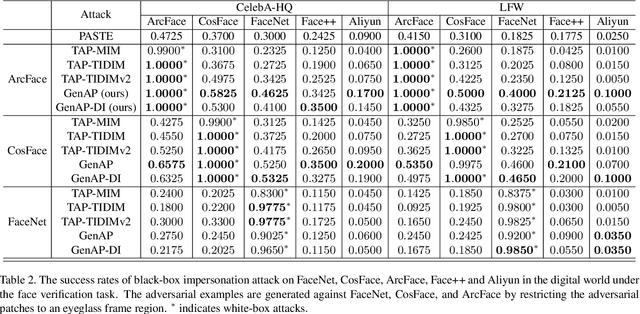
Face recognition is greatly improved by deep convolutional neural networks (CNNs). Recently, these face recognition models have been used for identity authentication in security sensitive applications. However, deep CNNs are vulnerable to adversarial patches, which are physically realizable and stealthy, raising new security concerns on the real-world applications of these models. In this paper, we evaluate the robustness of face recognition models using adversarial patches based on transferability, where the attacker has limited accessibility to the target models. First, we extend the existing transfer-based attack techniques to generate transferable adversarial patches. However, we observe that the transferability is sensitive to initialization and degrades when the perturbation magnitude is large, indicating the overfitting to the substitute models. Second, we propose to regularize the adversarial patches on the low dimensional data manifold. The manifold is represented by generative models pre-trained on legitimate human face images. Using face-like features as adversarial perturbations through optimization on the manifold, we show that the gaps between the responses of substitute models and the target models dramatically decrease, exhibiting a better transferability. Extensive digital world experiments are conducted to demonstrate the superiority of the proposed method in the black-box setting. We apply the proposed method in the physical world as well.
Accumulative Poisoning Attacks on Real-time Data
Jun 18, 2021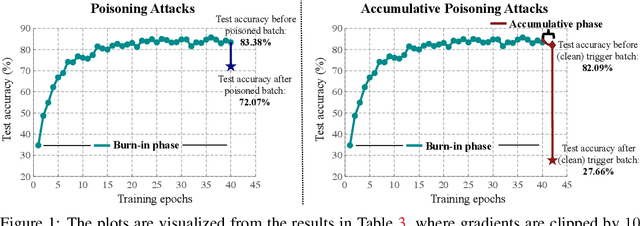
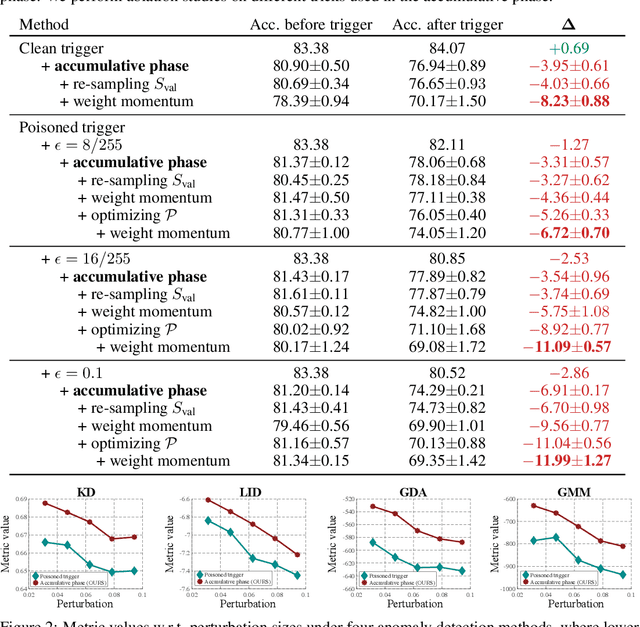
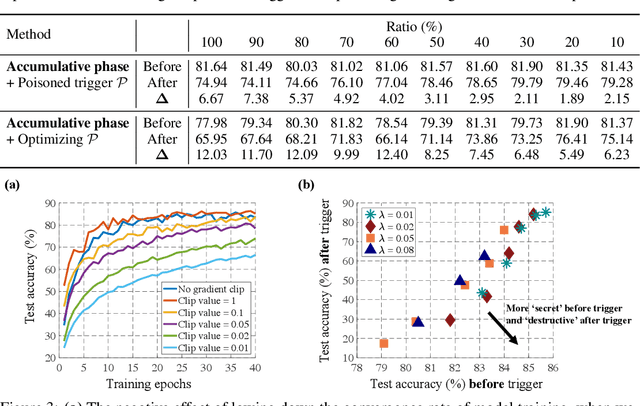
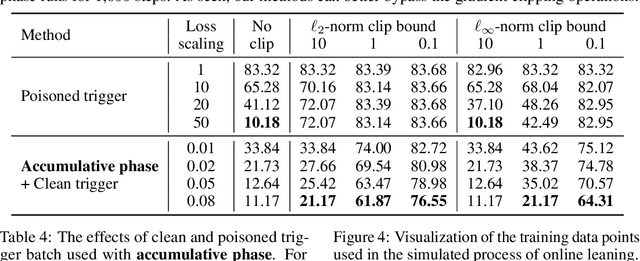
Collecting training data from untrusted sources exposes machine learning services to poisoning adversaries, who maliciously manipulate training data to degrade the model accuracy. When trained on offline datasets, poisoning adversaries have to inject the poisoned data in advance before training, and the order of feeding these poisoned batches into the model is stochastic. In contrast, practical systems are more usually trained/fine-tuned on sequentially captured real-time data, in which case poisoning adversaries could dynamically poison each data batch according to the current model state. In this paper, we focus on the real-time settings and propose a new attacking strategy, which affiliates an accumulative phase with poisoning attacks to secretly (i.e., without affecting accuracy) magnify the destructive effect of a (poisoned) trigger batch. By mimicking online learning and federated learning on CIFAR-10, we show that the model accuracy will significantly drop by a single update step on the trigger batch after the accumulative phase. Our work validates that a well-designed but straightforward attacking strategy can dramatically amplify the poisoning effects, with no need to explore complex techniques.
Scalable Quasi-Bayesian Inference for Instrumental Variable Regression
Jun 16, 2021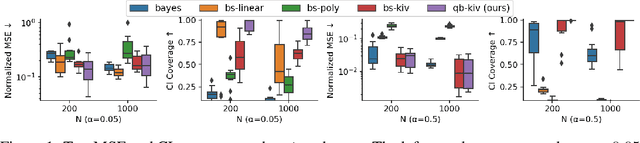

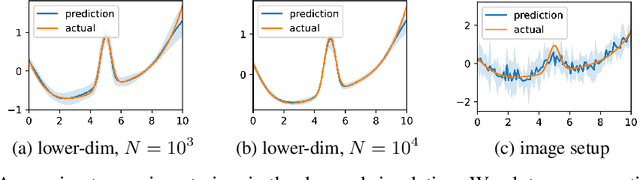

Recent years have witnessed an upsurge of interest in employing flexible machine learning models for instrumental variable (IV) regression, but the development of uncertainty quantification methodology is still lacking. In this work we present a scalable quasi-Bayesian procedure for IV regression, building upon the recently developed kernelized IV models. Contrary to Bayesian modeling for IV, our approach does not require additional assumptions on the data generating process, and leads to a scalable approximate inference algorithm with time cost comparable to the corresponding point estimation methods. Our algorithm can be further extended to work with neural network models. We analyze the theoretical properties of the proposed quasi-posterior, and demonstrate through empirical evaluation the competitive performance of our method.
Pre-Trained Models: Past, Present and Future
Jun 15, 2021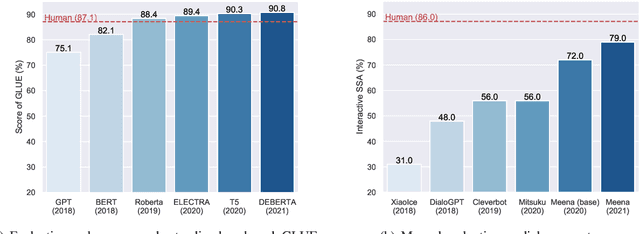
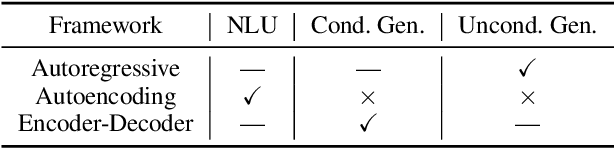
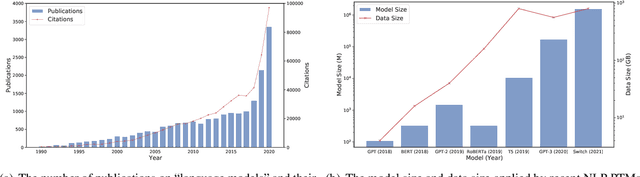
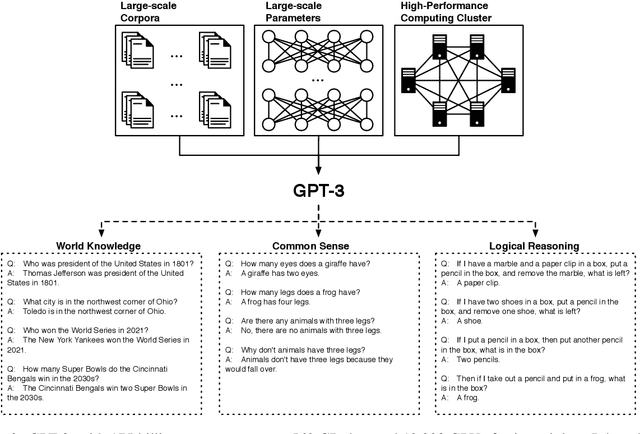
Large-scale pre-trained models (PTMs) such as BERT and GPT have recently achieved great success and become a milestone in the field of artificial intelligence (AI). Owing to sophisticated pre-training objectives and huge model parameters, large-scale PTMs can effectively capture knowledge from massive labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning on specific tasks, the rich knowledge implicitly encoded in huge parameters can benefit a variety of downstream tasks, which has been extensively demonstrated via experimental verification and empirical analysis. It is now the consensus of the AI community to adopt PTMs as backbone for downstream tasks rather than learning models from scratch. In this paper, we take a deep look into the history of pre-training, especially its special relation with transfer learning and self-supervised learning, to reveal the crucial position of PTMs in the AI development spectrum. Further, we comprehensively review the latest breakthroughs of PTMs. These breakthroughs are driven by the surge of computational power and the increasing availability of data, towards four important directions: designing effective architectures, utilizing rich contexts, improving computational efficiency, and conducting interpretation and theoretical analysis. Finally, we discuss a series of open problems and research directions of PTMs, and hope our view can inspire and advance the future study of PTMs.