 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJun Zhou
SIFN: A Sentiment-aware Interactive Fusion Network for Review-based Item Recommendation
Aug 18, 2021
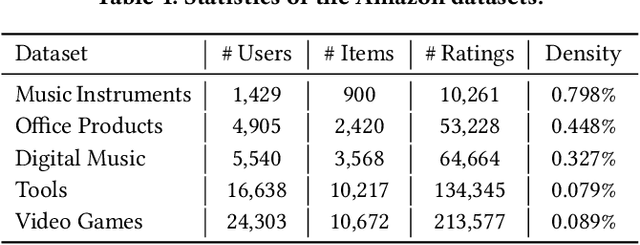
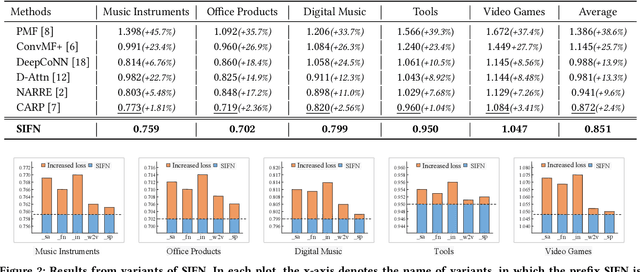
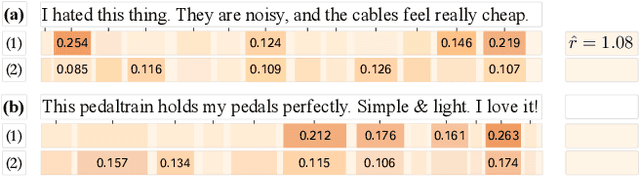
Recent studies in recommender systems have managed to achieve significantly improved performance by leveraging reviews for rating prediction. However, despite being extensively studied, these methods still suffer from some limitations. First, previous studies either encode the document or extract latent sentiment via neural networks, which are difficult to interpret the sentiment of reviewers intuitively. Second, they neglect the personalized interaction of reviews with user/item, i.e., each review has different contributions when modeling the sentiment preference of user/item. To remedy these issues, we propose a Sentiment-aware Interactive Fusion Network (SIFN) for review-based item recommendation. Specifically, we first encode user/item reviews via BERT and propose a light-weighted sentiment learner to extract semantic features of each review. Then, we propose a sentiment prediction task that guides the sentiment learner to extract sentiment-aware features via explicit sentiment labels. Finally, we design a rating prediction task that contains a rating learner with an interactive and fusion module to fuse the identity (i.e., user and item ID) and each review representation so that various interactive features can synergistically influence the final rating score. Experimental results on five real-world datasets demonstrate that the proposed model is superior to state-of-the-art models.
A Unified Framework for Cross-Domain and Cross-System Recommendations
Aug 18, 2021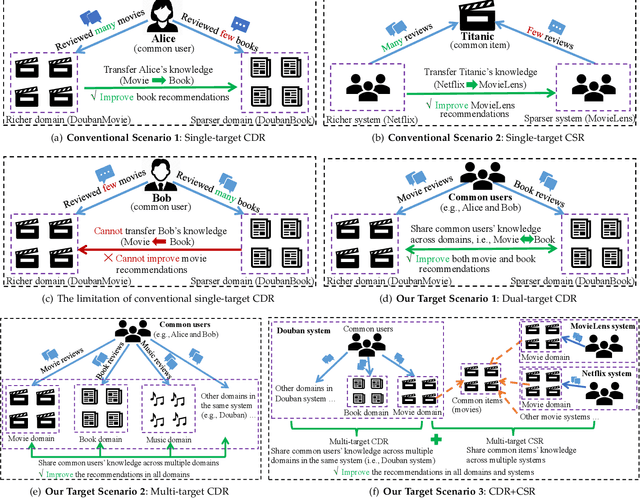

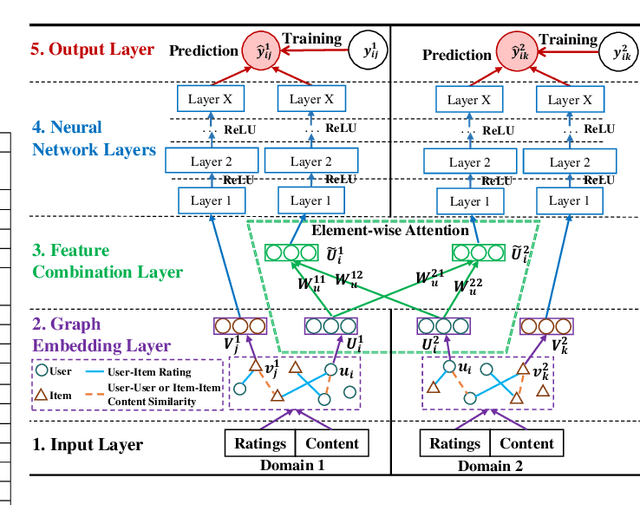
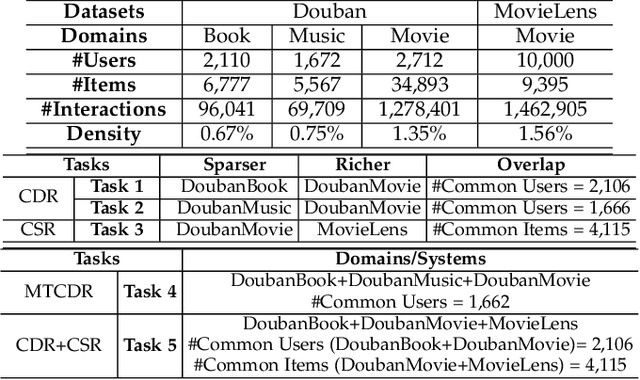
Cross-Domain Recommendation (CDR) and Cross-System Recommendation (CSR) have been proposed to improve the recommendation accuracy in a target dataset (domain/system) with the help of a source one with relatively richer information. However, most existing CDR and CSR approaches are single-target, namely, there is a single target dataset, which can only help the target dataset and thus cannot benefit the source dataset. In this paper, we focus on three new scenarios, i.e., Dual-Target CDR (DTCDR), Multi-Target CDR (MTCDR), and CDR+CSR, and aim to improve the recommendation accuracy in all datasets simultaneously for all scenarios. To do this, we propose a unified framework, called GA (based on Graph embedding and Attention techniques), for all three scenarios. In GA, we first construct separate heterogeneous graphs to generate more representative user and item embeddings. Then, we propose an element-wise attention mechanism to effectively combine the embeddings of common entities (users/items) learned from different datasets. Moreover, to avoid negative transfer, we further propose a Personalized training strategy to minimize the embedding difference of common entities between a richer dataset and a sparser dataset, deriving three new models, i.e., GA-DTCDR-P, GA-MTCDR-P, and GA-CDR+CSR-P, for the three scenarios respectively. Extensive experiments conducted on four real-world datasets demonstrate that our proposed GA models significantly outperform the state-of-the-art approaches.
Improving Transferability of Adversarial Patches on Face Recognition with Generative Models
Jun 29, 2021
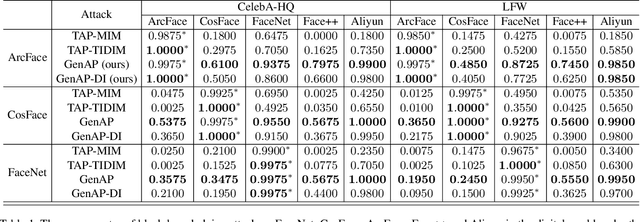
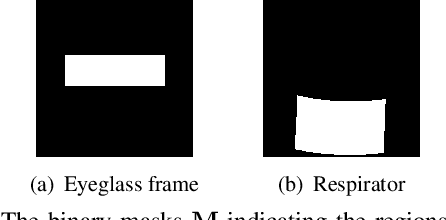
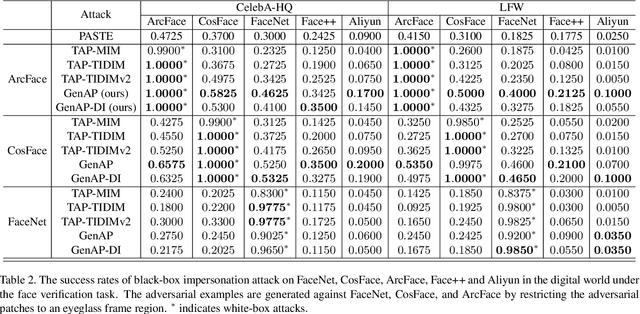
Face recognition is greatly improved by deep convolutional neural networks (CNNs). Recently, these face recognition models have been used for identity authentication in security sensitive applications. However, deep CNNs are vulnerable to adversarial patches, which are physically realizable and stealthy, raising new security concerns on the real-world applications of these models. In this paper, we evaluate the robustness of face recognition models using adversarial patches based on transferability, where the attacker has limited accessibility to the target models. First, we extend the existing transfer-based attack techniques to generate transferable adversarial patches. However, we observe that the transferability is sensitive to initialization and degrades when the perturbation magnitude is large, indicating the overfitting to the substitute models. Second, we propose to regularize the adversarial patches on the low dimensional data manifold. The manifold is represented by generative models pre-trained on legitimate human face images. Using face-like features as adversarial perturbations through optimization on the manifold, we show that the gaps between the responses of substitute models and the target models dramatically decrease, exhibiting a better transferability. Extensive digital world experiments are conducted to demonstrate the superiority of the proposed method in the black-box setting. We apply the proposed method in the physical world as well.
A Bi-Level Framework for Learning to Solve Combinatorial Optimization on Graphs
Jun 09, 2021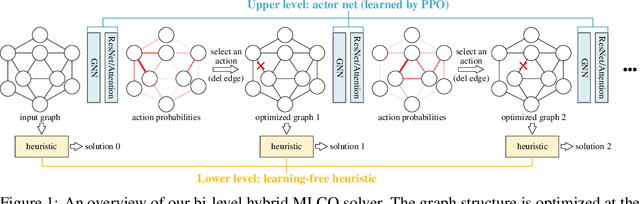
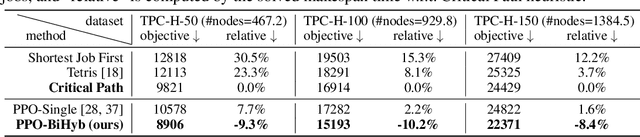
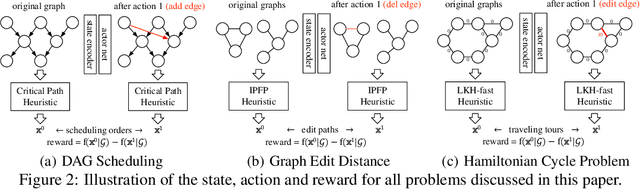
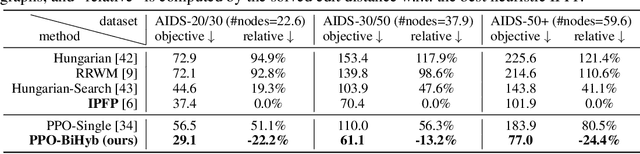
Combinatorial Optimization (CO) has been a long-standing challenging research topic featured by its NP-hard nature. Traditionally such problems are approximately solved with heuristic algorithms which are usually fast but may sacrifice the solution quality. Currently, machine learning for combinatorial optimization (MLCO) has become a trending research topic, but most existing MLCO methods treat CO as a single-level optimization by directly learning the end-to-end solutions, which are hard to scale up and mostly limited by the capacity of ML models given the high complexity of CO. In this paper, we propose a hybrid approach to combine the best of the two worlds, in which a bi-level framework is developed with an upper-level learning method to optimize the graph (e.g. add, delete or modify edges in a graph), fused with a lower-level heuristic algorithm solving on the optimized graph. Such a bi-level approach simplifies the learning on the original hard CO and can effectively mitigate the demand for model capacity. The experiments and results on several popular CO problems like Directed Acyclic Graph scheduling, Graph Edit Distance and Hamiltonian Cycle Problem show its effectiveness over manually designed heuristics and single-level learning methods.
Improvement of Normal Estimation for PointClouds via Simplifying Surface Fitting
Apr 21, 2021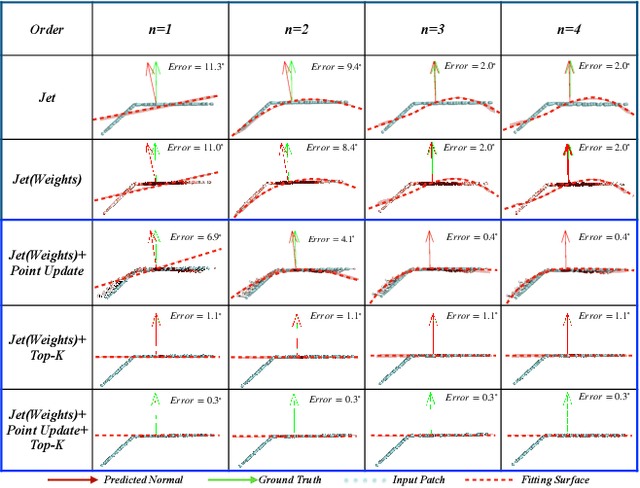
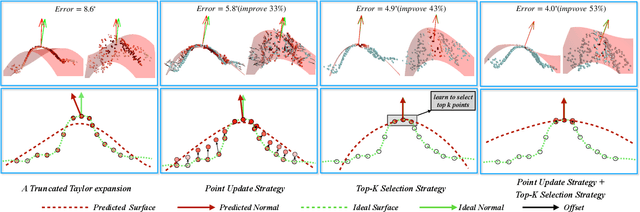
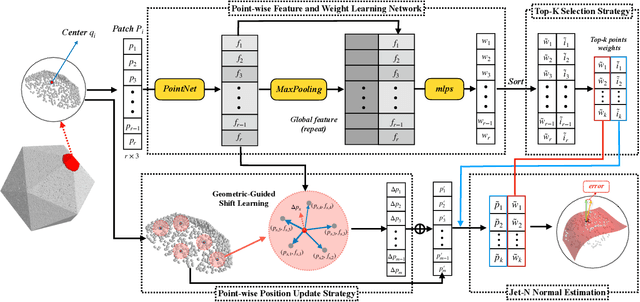
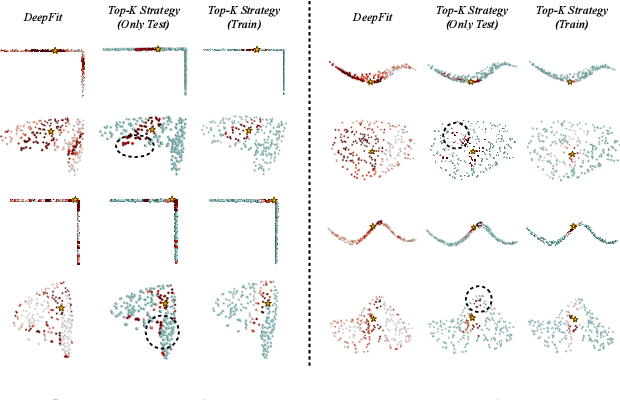
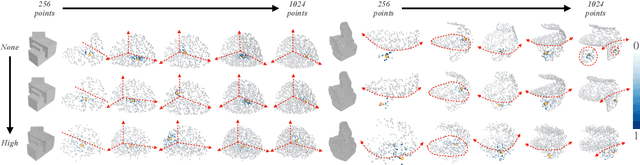
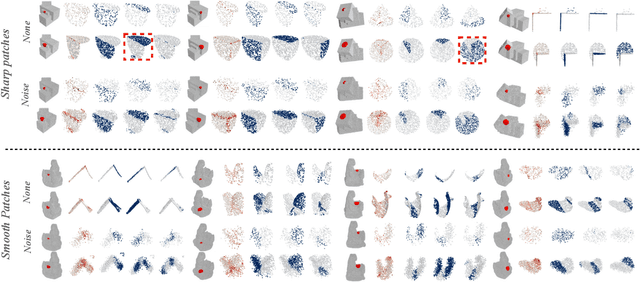
With the burst development of neural networks in recent years, the task of normal estimation has once again become a concern. By introducing the neural networks to classic methods based on problem-specific knowledge, the adaptability of the normal estimation algorithm to noise and scale has been greatly improved. However, the compatibility between neural networks and the traditional methods has not been considered. Similar to the principle of Occam's razor, that is, the simpler is better. We observe that a more simplified process of surface fitting can significantly improve the accuracy of the normal estimation. In this paper, two simple-yet-effective strategies are proposed to address the compatibility between the neural networks and surface fitting process to improve normal estimation. Firstly, a dynamic top-k selection strategy is introduced to better focus on the most critical points of a given patch, and the points selected by our learning method tend to fit a surface by way of a simple tangent plane, which can dramatically improve the normal estimation results of patches with sharp corners or complex patterns. Then, we propose a point update strategy before local surface fitting, which smooths the sharp boundary of the patch to simplify the surface fitting process, significantly reducing the fitting distortion and improving the accuracy of the predicted point normal. The experiments analyze the effectiveness of our proposed strategies and demonstrate that our method achieves SOTA results with the advantage of higher estimation accuracy over most existed approaches.
Fast and Accurate Normal Estimation for Point Cloud via Patch Stitching
Mar 31, 2021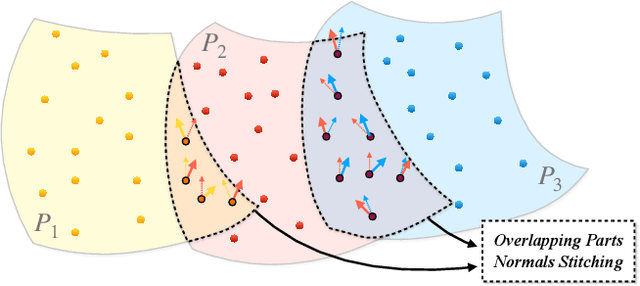
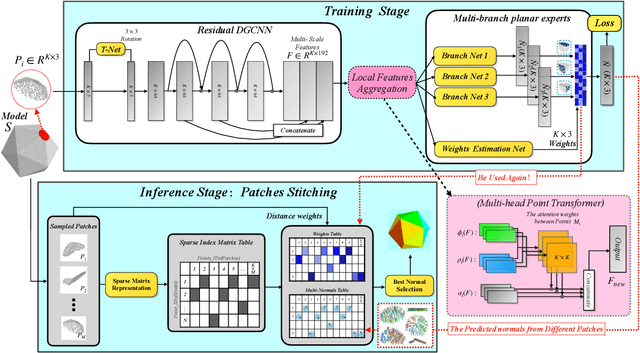
This paper presents an effective normal estimation method adopting multi-patch stitching for an unstructured point cloud. The majority of learning-based approaches encode a local patch around each point of a whole model and estimate the normals in a point-by-point manner. In contrast, we suggest a more efficient pipeline, in which we introduce a patch-level normal estimation architecture to process a series of overlapping patches. Additionally, a multi-normal selection method based on weights, dubbed as multi-patch stitching, integrates the normals from the overlapping patches. To reduce the adverse effects of sharp corners or noise in a patch, we introduce an adaptive local feature aggregation layer to focus on an anisotropic neighborhood. We then utilize a multi-branch planar experts module to break the mutual influence between underlying piecewise surfaces in a patch. At the stitching stage, we use the learned weights of multi-branch planar experts and distance weights between points to select the best normal from the overlapping parts. Furthermore, we put forward constructing a sparse matrix representation to reduce large-scale retrieval overheads for the loop iterations dramatically. Extensive experiments demonstrate that our method achieves SOTA results with the advantage of lower computational costs and higher robustness to noise over most of the existing approaches.
Goal-Oriented Gaze Estimation for Zero-Shot Learning
Mar 05, 2021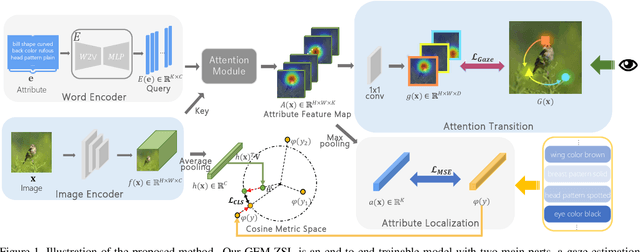
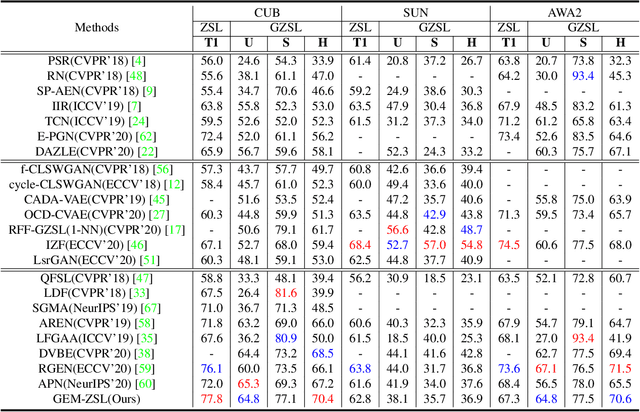
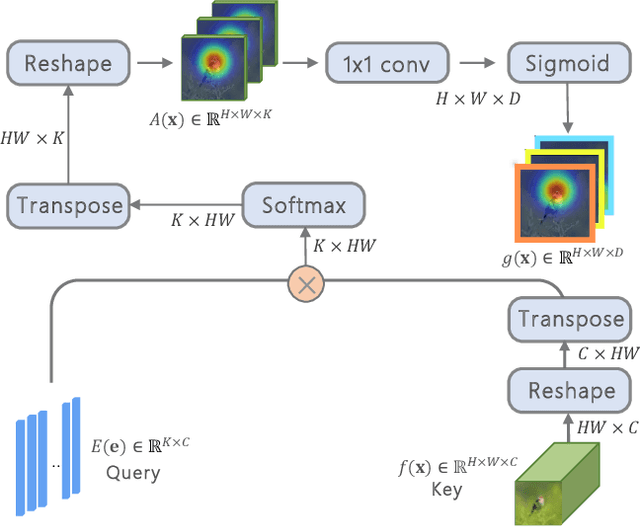
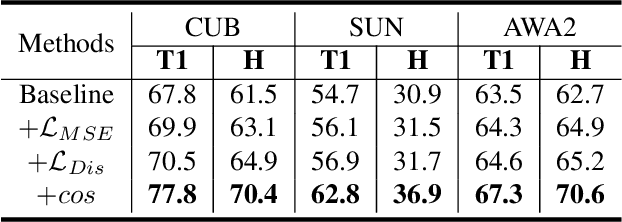
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen classes. Since semantic knowledge is built on attributes shared between different classes, which are highly local, strong prior for localization of object attribute is beneficial for visual-semantic embedding. Interestingly, when recognizing unseen images, human would also automatically gaze at regions with certain semantic clue. Therefore, we introduce a novel goal-oriented gaze estimation module (GEM) to improve the discriminative attribute localization based on the class-level attributes for ZSL. We aim to predict the actual human gaze location to get the visual attention regions for recognizing a novel object guided by attribute description. Specifically, the task-dependent attention is learned with the goal-oriented GEM, and the global image features are simultaneously optimized with the regression of local attribute features. Experiments on three ZSL benchmarks, i.e., CUB, SUN and AWA2, show the superiority or competitiveness of our proposed method against the state-of-the-art ZSL methods. The ablation analysis on real gaze data CUB-VWSW also validates the benefits and accuracy of our gaze estimation module. This work implies the promising benefits of collecting human gaze dataset and automatic gaze estimation algorithms on high-level computer vision tasks. The code is available at https://github.com/osierboy/GEM-ZSL.
Cross-Domain Recommendation: Challenges, Progress, and Prospects
Mar 02, 2021
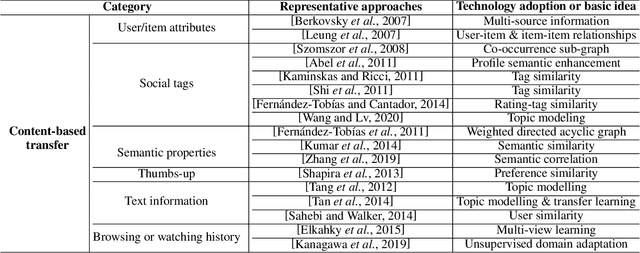
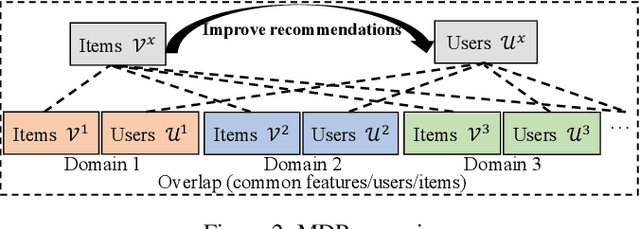
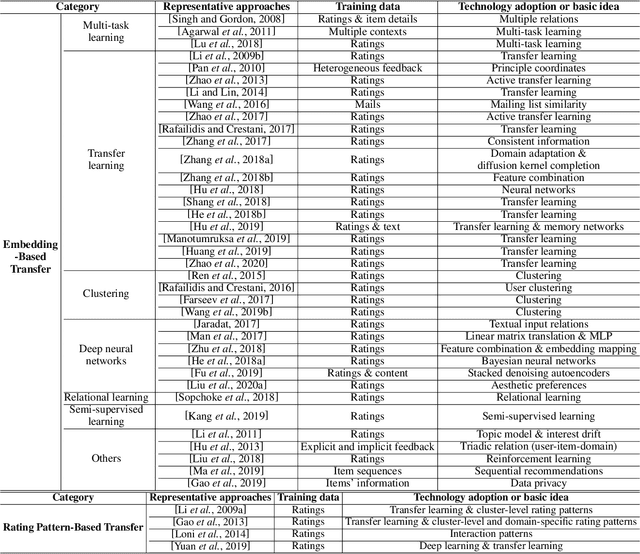
To address the long-standing data sparsity problem in recommender systems (RSs), cross-domain recommendation (CDR) has been proposed to leverage the relatively richer information from a richer domain to improve the recommendation performance in a sparser domain. Although CDR has been extensively studied in recent years, there is a lack of a systematic review of the existing CDR approaches. To fill this gap, in this paper, we provide a comprehensive review of existing CDR approaches, including challenges, research progress, and future directions. Specifically, we first summarize existing CDR approaches into four types, including single-target CDR, multi-domain recommendation, dual-target CDR, and multi-target CDR. We then present the definitions and challenges of these CDR approaches. Next, we propose a full-view categorization and new taxonomies on these approaches and report their research progress in detail. In the end, we share several promising research directions in CDR.
STNet: Scale Tree Network with Multi-level Auxiliator for Crowd Counting
Dec 18, 2020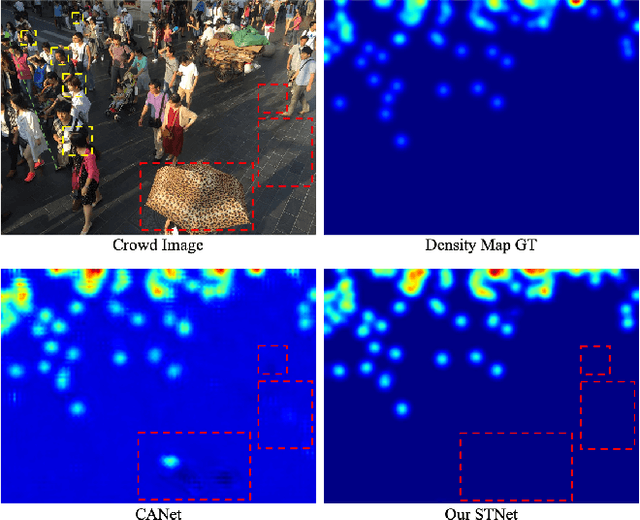
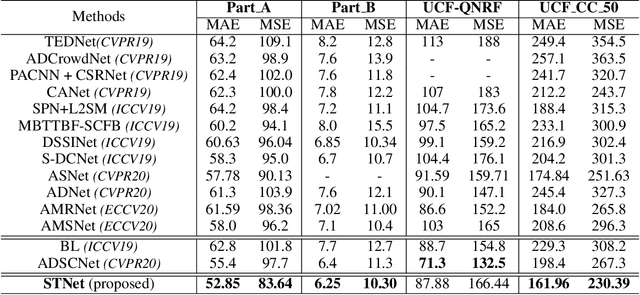
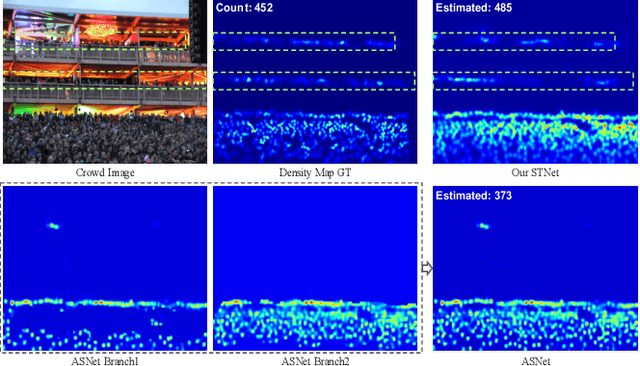
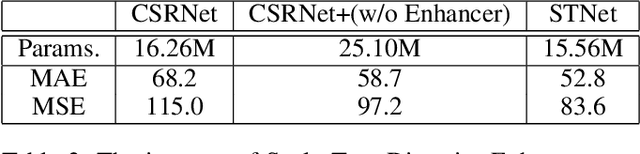
Crowd counting remains a challenging task because the presence of drastic scale variation, density inconsistency, and complex background can seriously degrade the counting accuracy. To battle the ingrained issue of accuracy degradation, we propose a novel and powerful network called Scale Tree Network (STNet) for accurate crowd counting. STNet consists of two key components: a Scale-Tree Diversity Enhancer and a Semi-supervised Multi-level Auxiliator. Specifically, the Diversity Enhancer is designed to enrich scale diversity, which alleviates limitations of existing methods caused by insufficient level of scales. A novel tree structure is adopted to hierarchically parse coarse-to-fine crowd regions. Furthermore, a simple yet effective Multi-level Auxiliator is presented to aid in exploiting generalisable shared characteristics at multiple levels, allowing more accurate pixel-wise background cognition. The overall STNet is trained in an end-to-end manner, without the needs for manually tuning loss weights between the main and the auxiliary tasks. Extensive experiments on four challenging crowd datasets demonstrate the superiority of the proposed method.
Towards Scalable and Privacy-Preserving Deep Neural Network via Algorithmic-Cryptographic Co-design
Dec 17, 2020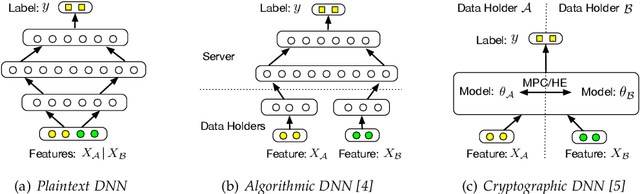
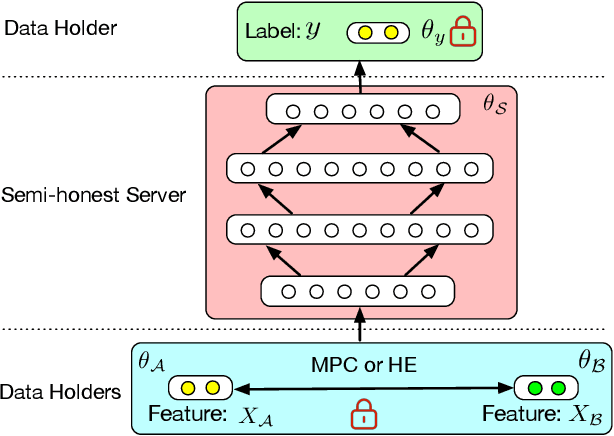

Deep Neural Networks (DNNs) have achieved remarkable progress in various real-world applications, especially when abundant training data are provided. However, data isolation has become a serious problem currently. Existing works build privacy preserving DNN models from either algorithmic perspective or cryptographic perspective. The former mainly splits the DNN computation graph between data holders or between data holders and server, which demonstrates good scalability but suffers from accuracy loss and potential privacy risks. In contrast, the latter leverages time-consuming cryptographic techniques, which has strong privacy guarantee but poor scalability. In this paper, we propose SPNN - a Scalable and Privacy-preserving deep Neural Network learning framework, from algorithmic-cryptographic co-perspective. From algorithmic perspective, we split the computation graph of DNN models into two parts, i.e., the private data related computations that are performed by data holders and the rest heavy computations that are delegated to a server with high computation ability. From cryptographic perspective, we propose using two types of cryptographic techniques, i.e., secret sharing and homomorphic encryption, for the isolated data holders to conduct private data related computations privately and cooperatively. Furthermore, we implement SPNN in a decentralized setting and introduce user-friendly APIs. Experimental results conducted on real-world datasets demonstrate the superiority of SPNN.