 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural probabilistic motor primitives for humanoid control
Jan 15, 2019
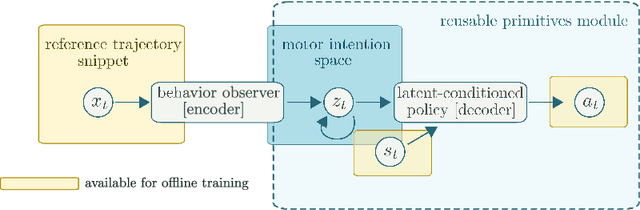
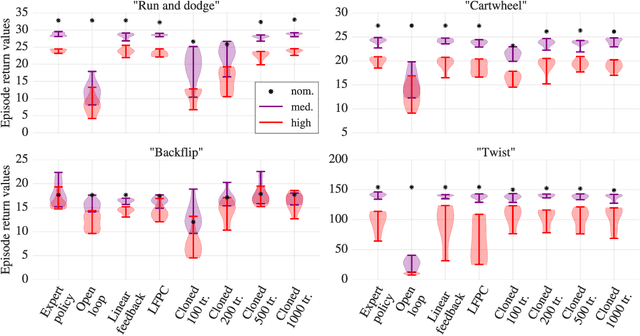
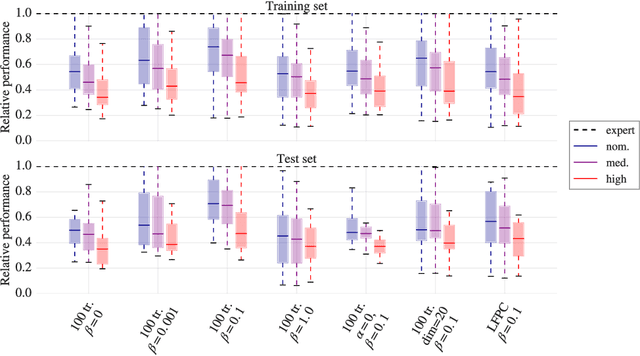
We focus on the problem of learning a single motor module that can flexibly express a range of behaviors for the control of high-dimensional physically simulated humanoids. To do this, we propose a motor architecture that has the general structure of an inverse model with a latent-variable bottleneck. We show that it is possible to train this model entirely offline to compress thousands of expert policies and learn a motor primitive embedding space. The trained neural probabilistic motor primitive system can perform one-shot imitation of whole-body humanoid behaviors, robustly mimicking unseen trajectories. Additionally, we demonstrate that it is also straightforward to train controllers to reuse the learned motor primitive space to solve tasks, and the resulting movements are relatively naturalistic. To support the training of our model, we compare two approaches for offline policy cloning, including an experience efficient method which we call linear feedback policy cloning. We encourage readers to view a supplementary video ( https://youtu.be/CaDEf-QcKwA ) summarizing our results.
Hierarchical visuomotor control of humanoids
Jan 15, 2019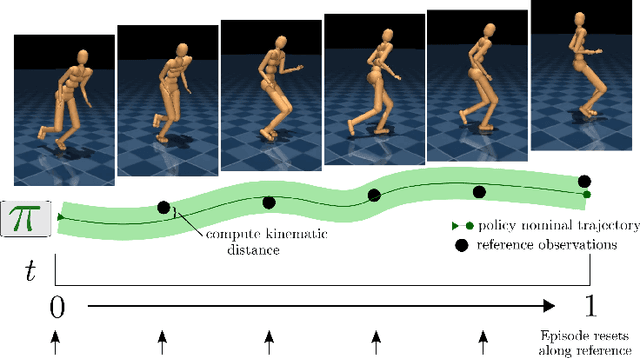

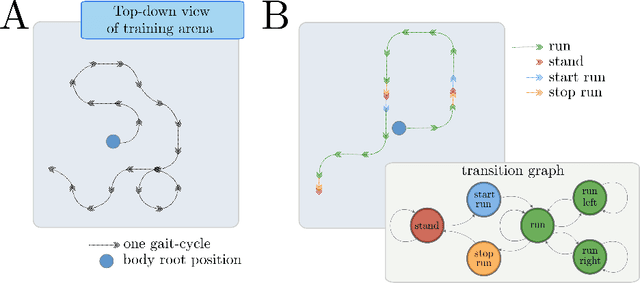

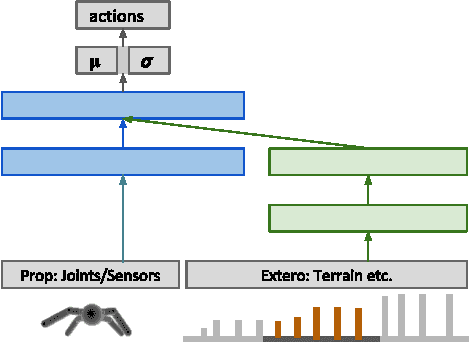
We aim to build complex humanoid agents that integrate perception, motor control, and memory. In this work, we partly factor this problem into low-level motor control from proprioception and high-level coordination of the low-level skills informed by vision. We develop an architecture capable of surprisingly flexible, task-directed motor control of a relatively high-DoF humanoid body by combining pre-training of low-level motor controllers with a high-level, task-focused controller that switches among low-level sub-policies. The resulting system is able to control a physically-simulated humanoid body to solve tasks that require coupling visual perception from an unstabilized egocentric RGB camera during locomotion in the environment. For a supplementary video link, see https://youtu.be/7GISvfbykLE .
Graph networks as learnable physics engines for inference and control
Jun 04, 2018
Understanding and interacting with everyday physical scenes requires rich knowledge about the structure of the world, represented either implicitly in a value or policy function, or explicitly in a transition model. Here we introduce a new class of learnable models--based on graph networks--which implement an inductive bias for object- and relation-centric representations of complex, dynamical systems. Our results show that as a forward model, our approach supports accurate predictions from real and simulated data, and surprisingly strong and efficient generalization, across eight distinct physical systems which we varied parametrically and structurally. We also found that our inference model can perform system identification. Our models are also differentiable, and support online planning via gradient-based trajectory optimization, as well as offline policy optimization. Our framework offers new opportunities for harnessing and exploiting rich knowledge about the world, and takes a key step toward building machines with more human-like representations of the world.
Reinforcement and Imitation Learning for Diverse Visuomotor Skills
May 27, 2018
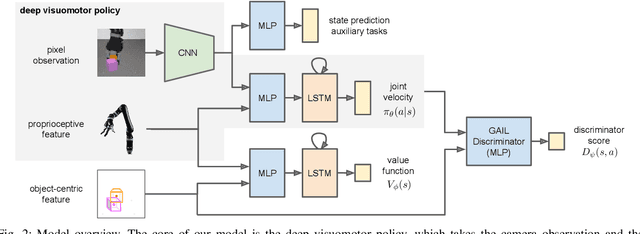
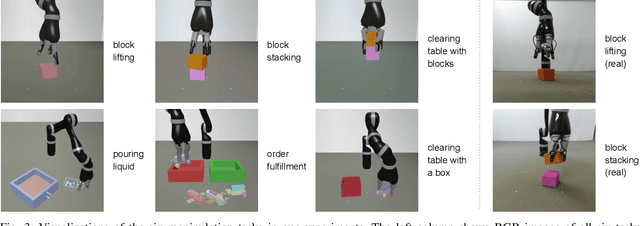
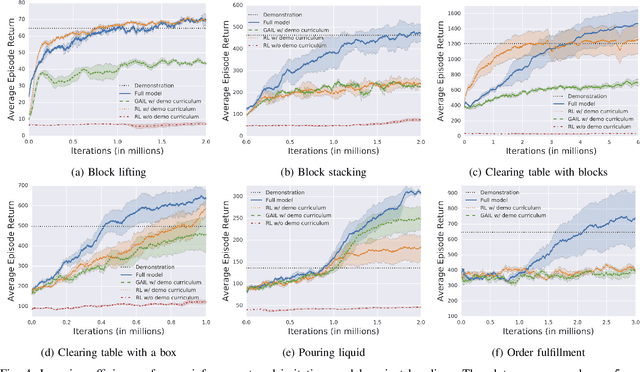
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. A brief visual description of this work can be viewed in https://youtu.be/EDl8SQUNjj0
DeepMind Control Suite
Jan 02, 2018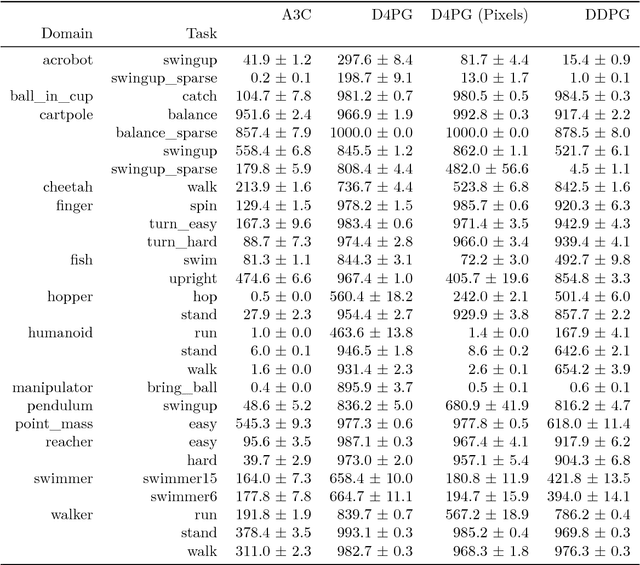
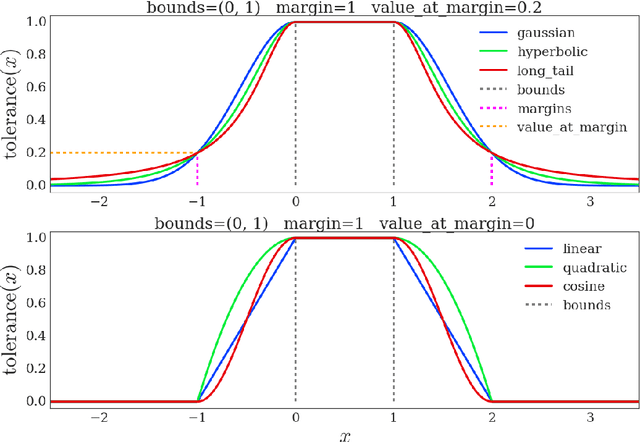
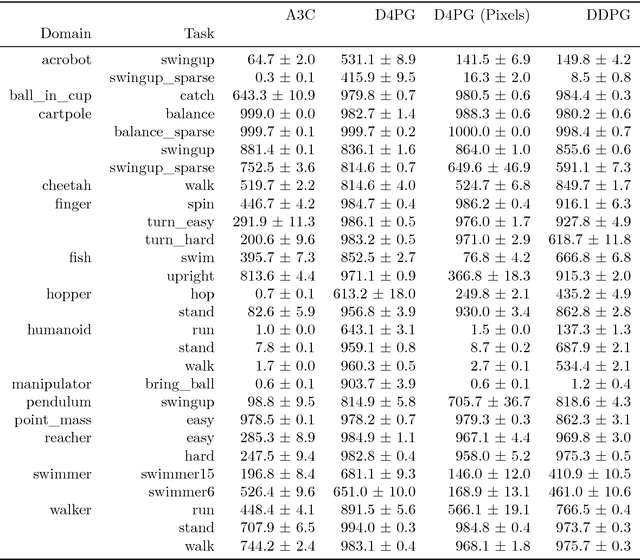
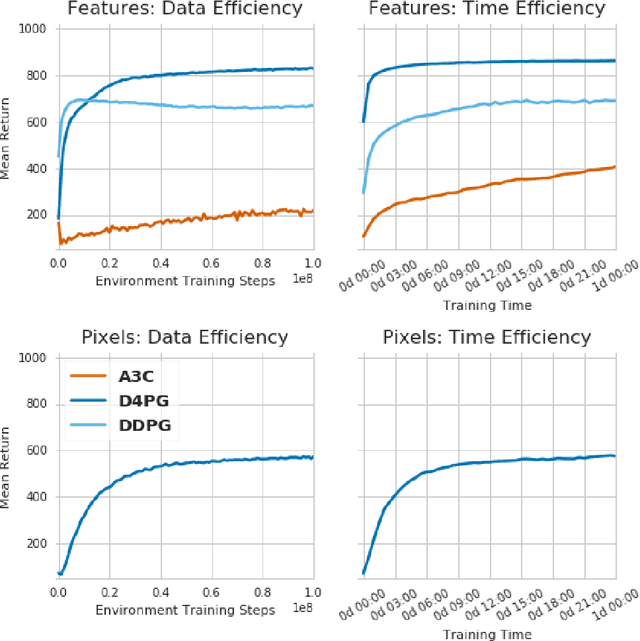
The DeepMind Control Suite is a set of continuous control tasks with a standardised structure and interpretable rewards, intended to serve as performance benchmarks for reinforcement learning agents. The tasks are written in Python and powered by the MuJoCo physics engine, making them easy to use and modify. We include benchmarks for several learning algorithms. The Control Suite is publicly available at https://www.github.com/deepmind/dm_control . A video summary of all tasks is available at http://youtu.be/rAai4QzcYbs .
Robust Imitation of Diverse Behaviors
Jul 14, 2017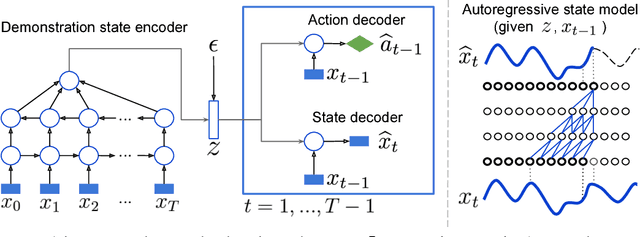
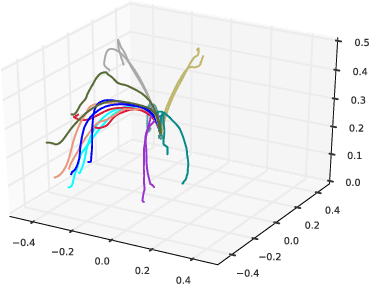
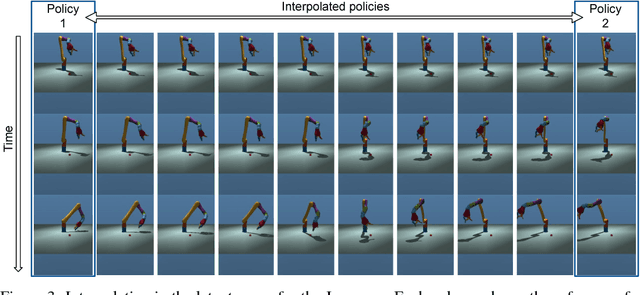
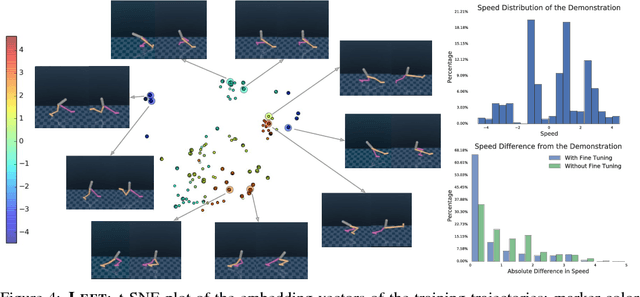
Deep generative models have recently shown great promise in imitation learning for motor control. Given enough data, even supervised approaches can do one-shot imitation learning; however, they are vulnerable to cascading failures when the agent trajectory diverges from the demonstrations. Compared to purely supervised methods, Generative Adversarial Imitation Learning (GAIL) can learn more robust controllers from fewer demonstrations, but is inherently mode-seeking and more difficult to train. In this paper, we show how to combine the favourable aspects of these two approaches. The base of our model is a new type of variational autoencoder on demonstration trajectories that learns semantic policy embeddings. We show that these embeddings can be learned on a 9 DoF Jaco robot arm in reaching tasks, and then smoothly interpolated with a resulting smooth interpolation of reaching behavior. Leveraging these policy representations, we develop a new version of GAIL that (1) is much more robust than the purely-supervised controller, especially with few demonstrations, and (2) avoids mode collapse, capturing many diverse behaviors when GAIL on its own does not. We demonstrate our approach on learning diverse gaits from demonstration on a 2D biped and a 62 DoF 3D humanoid in the MuJoCo physics environment.
Emergence of Locomotion Behaviours in Rich Environments
Jul 10, 2017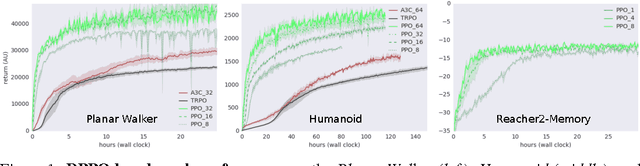


The reinforcement learning paradigm allows, in principle, for complex behaviours to be learned directly from simple reward signals. In practice, however, it is common to carefully hand-design the reward function to encourage a particular solution, or to derive it from demonstration data. In this paper explore how a rich environment can help to promote the learning of complex behavior. Specifically, we train agents in diverse environmental contexts, and find that this encourages the emergence of robust behaviours that perform well across a suite of tasks. We demonstrate this principle for locomotion -- behaviours that are known for their sensitivity to the choice of reward. We train several simulated bodies on a diverse set of challenging terrains and obstacles, using a simple reward function based on forward progress. Using a novel scalable variant of policy gradient reinforcement learning, our agents learn to run, jump, crouch and turn as required by the environment without explicit reward-based guidance. A visual depiction of highlights of the learned behavior can be viewed following https://youtu.be/hx_bgoTF7bs .
Learning human behaviors from motion capture by adversarial imitation
Jul 10, 2017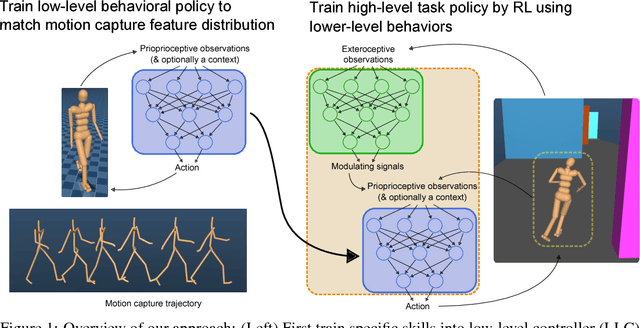
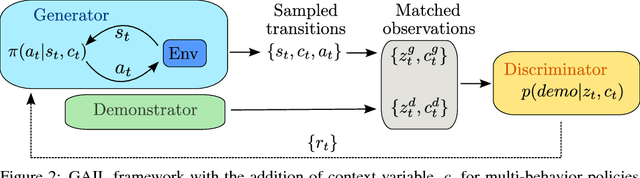
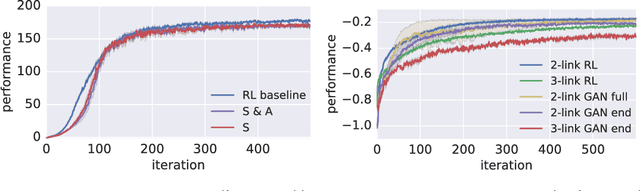
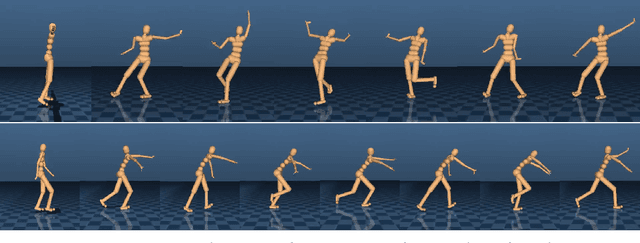
Rapid progress in deep reinforcement learning has made it increasingly feasible to train controllers for high-dimensional humanoid bodies. However, methods that use pure reinforcement learning with simple reward functions tend to produce non-humanlike and overly stereotyped movement behaviors. In this work, we extend generative adversarial imitation learning to enable training of generic neural network policies to produce humanlike movement patterns from limited demonstrations consisting only of partially observed state features, without access to actions, even when the demonstrations come from a body with different and unknown physical parameters. We leverage this approach to build sub-skill policies from motion capture data and show that they can be reused to solve tasks when controlled by a higher level controller.
Neuroprosthetic decoder training as imitation learning
Mar 14, 2016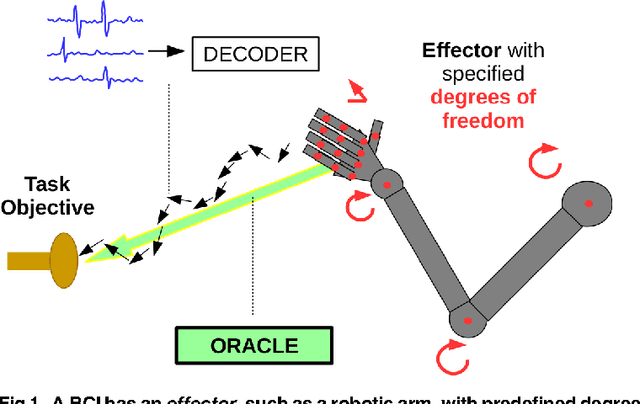

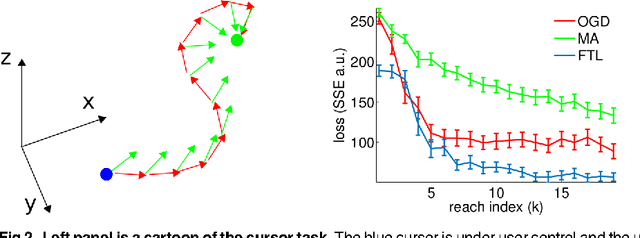
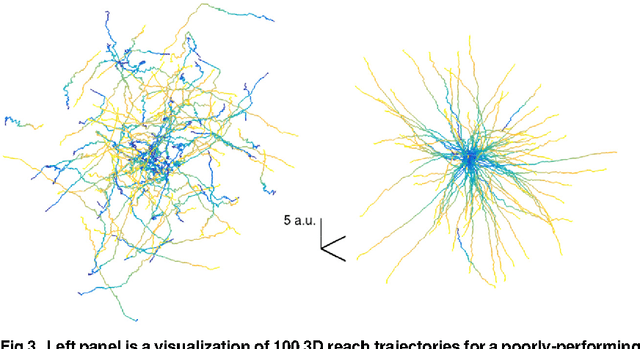
Neuroprosthetic brain-computer interfaces function via an algorithm which decodes neural activity of the user into movements of an end effector, such as a cursor or robotic arm. In practice, the decoder is often learned by updating its parameters while the user performs a task. When the user's intention is not directly observable, recent methods have demonstrated value in training the decoder against a surrogate for the user's intended movement. We describe how training a decoder in this way is a novel variant of an imitation learning problem, where an oracle or expert is employed for supervised training in lieu of direct observations, which are not available. Specifically, we describe how a generic imitation learning meta-algorithm, dataset aggregation (DAgger, [1]), can be adapted to train a generic brain-computer interface. By deriving existing learning algorithms for brain-computer interfaces in this framework, we provide a novel analysis of regret (an important metric of learning efficacy) for brain-computer interfaces. This analysis allows us to characterize the space of algorithmic variants and bounds on their regret rates. Existing approaches for decoder learning have been performed in the cursor control setting, but the available design principles for these decoders are such that it has been impossible to scale them to naturalistic settings. Leveraging our findings, we then offer an algorithm that combines imitation learning with optimal control, which should allow for training of arbitrary effectors for which optimal control can generate goal-oriented control. We demonstrate this novel and general BCI algorithm with simulated neuroprosthetic control of a 26 degree-of-freedom model of an arm, a sophisticated and realistic end effector.