 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-DOPE: Differentiable Deep Object Pose Estimation
Sep 30, 2023



We introduce Diff-DOPE, a 6-DoF pose refiner that takes as input an image, a 3D textured model of an object, and an initial pose of the object. The method uses differentiable rendering to update the object pose to minimize the visual error between the image and the projection of the model. We show that this simple, yet effective, idea is able to achieve state-of-the-art results on pose estimation datasets. Our approach is a departure from recent methods in which the pose refiner is a deep neural network trained on a large synthetic dataset to map inputs to refinement steps. Rather, our use of differentiable rendering allows us to avoid training altogether. Our approach performs multiple gradient descent optimizations in parallel with different random learning rates to avoid local minima from symmetric objects, similar appearances, or wrong step size. Various modalities can be used, e.g., RGB, depth, intensity edges, and object segmentation masks. We present experiments examining the effect of various choices, showing that the best results are found when the RGB image is accompanied by an object mask and depth image to guide the optimization process.
HANDAL: A Dataset of Real-World Manipulable Object Categories with Pose Annotations, Affordances, and Reconstructions
Aug 02, 2023We present the HANDAL dataset for category-level object pose estimation and affordance prediction. Unlike previous datasets, ours is focused on robotics-ready manipulable objects that are of the proper size and shape for functional grasping by robot manipulators, such as pliers, utensils, and screwdrivers. Our annotation process is streamlined, requiring only a single off-the-shelf camera and semi-automated processing, allowing us to produce high-quality 3D annotations without crowd-sourcing. The dataset consists of 308k annotated image frames from 2.2k videos of 212 real-world objects in 17 categories. We focus on hardware and kitchen tool objects to facilitate research in practical scenarios in which a robot manipulator needs to interact with the environment beyond simple pushing or indiscriminate grasping. We outline the usefulness of our dataset for 6-DoF category-level pose+scale estimation and related tasks. We also provide 3D reconstructed meshes of all objects, and we outline some of the bottlenecks to be addressed for democratizing the collection of datasets like this one.
Partial-View Object View Synthesis via Filtered Inversion
Apr 03, 2023



We propose Filtering Inversion (FINV), a learning framework and optimization process that predicts a renderable 3D object representation from one or few partial views. FINV addresses the challenge of synthesizing novel views of objects from partial observations, spanning cases where the object is not entirely in view, is partially occluded, or is only observed from similar views. To achieve this, FINV learns shape priors by training a 3D generative model. At inference, given one or more views of a novel real-world object, FINV first finds a set of latent codes for the object by inverting the generative model from multiple initial seeds. Maintaining the set of latent codes, FINV filters and resamples them after receiving each new observation, akin to particle filtering. The generator is then finetuned for each latent code on the available views in order to adapt to novel objects. We show that FINV successfully synthesizes novel views of real-world objects (e.g., chairs, tables, and cars), even if the generative prior is trained only on synthetic objects. The ability to address the sim-to-real problem allows FINV to be used for object categories without real-world datasets. FINV achieves state-of-the-art performance on multiple real-world datasets, recovers object shape and texture from partial and sparse views, is robust to occlusion, and is able to incrementally improve its representation with more observations.
TTA-COPE: Test-Time Adaptation for Category-Level Object Pose Estimation
Mar 29, 2023



Test-time adaptation methods have been gaining attention recently as a practical solution for addressing source-to-target domain gaps by gradually updating the model without requiring labels on the target data. In this paper, we propose a method of test-time adaptation for category-level object pose estimation called TTA-COPE. We design a pose ensemble approach with a self-training loss using pose-aware confidence. Unlike previous unsupervised domain adaptation methods for category-level object pose estimation, our approach processes the test data in a sequential, online manner, and it does not require access to the source domain at runtime. Extensive experimental results demonstrate that the proposed pose ensemble and the self-training loss improve category-level object pose performance during test time under both semi-supervised and unsupervised settings. Project page: https://taeyeop.com/ttacope
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Mar 24, 2023We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture is largely absent. The object is assumed to be segmented in the first frame only. No additional information is required, and no assumption is made about the interaction agent. Key to our method is a Neural Object Field that is learned concurrently with a pose graph optimization process in order to robustly accumulate information into a consistent 3D representation capturing both geometry and appearance. A dynamic pool of posed memory frames is automatically maintained to facilitate communication between these threads. Our approach handles challenging sequences with large pose changes, partial and full occlusion, untextured surfaces, and specular highlights. We show results on HO3D, YCBInEOAT, and BEHAVE datasets, demonstrating that our method significantly outperforms existing approaches. Project page: https://bundlesdf.github.io
MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare
Dec 13, 2022



We introduce MegaPose, a method to estimate the 6D pose of novel objects, that is, objects unseen during training. At inference time, the method only assumes knowledge of (i) a region of interest displaying the object in the image and (ii) a CAD model of the observed object. The contributions of this work are threefold. First, we present a 6D pose refiner based on a render&compare strategy which can be applied to novel objects. The shape and coordinate system of the novel object are provided as inputs to the network by rendering multiple synthetic views of the object's CAD model. Second, we introduce a novel approach for coarse pose estimation which leverages a network trained to classify whether the pose error between a synthetic rendering and an observed image of the same object can be corrected by the refiner. Third, we introduce a large-scale synthetic dataset of photorealistic images of thousands of objects with diverse visual and shape properties and show that this diversity is crucial to obtain good generalization performance on novel objects. We train our approach on this large synthetic dataset and apply it without retraining to hundreds of novel objects in real images from several pose estimation benchmarks. Our approach achieves state-of-the-art performance on the ModelNet and YCB-Video datasets. An extensive evaluation on the 7 core datasets of the BOP challenge demonstrates that our approach achieves performance competitive with existing approaches that require access to the target objects during training. Code, dataset and trained models are available on the project page: https://megapose6d.github.io/.
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022

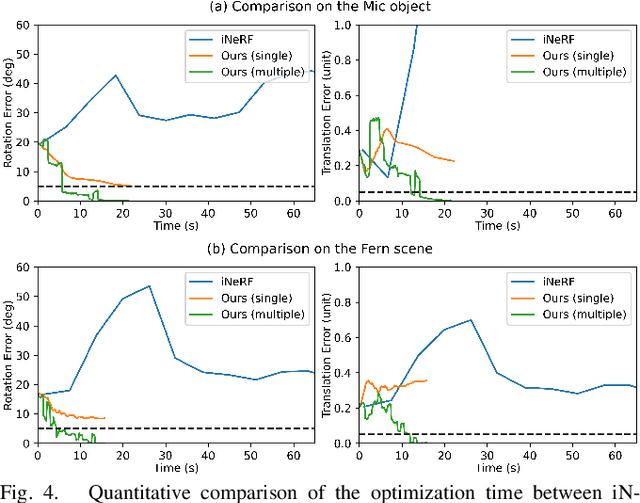

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022
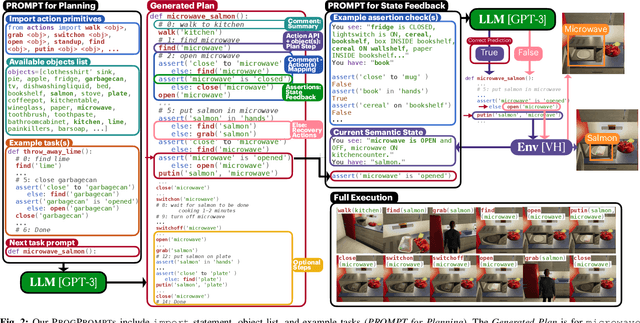


Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io
Variable Bitrate Neural Fields
Jun 15, 2022
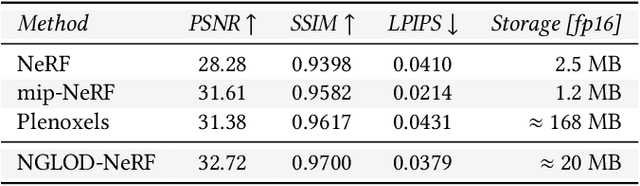

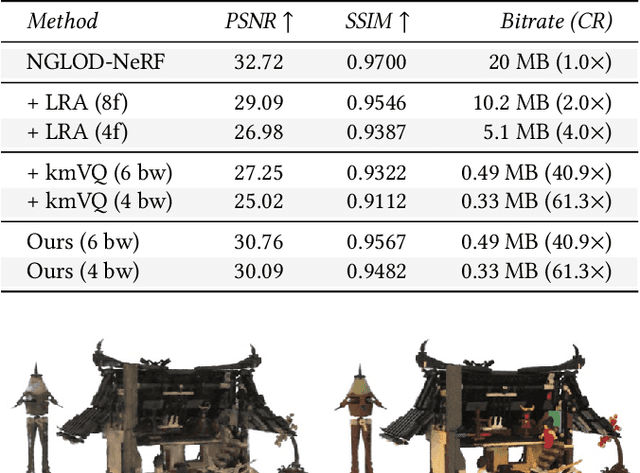
Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad.
Keypoint-Based Category-Level Object Pose Tracking from an RGB Sequence with Uncertainty Estimation
May 23, 2022
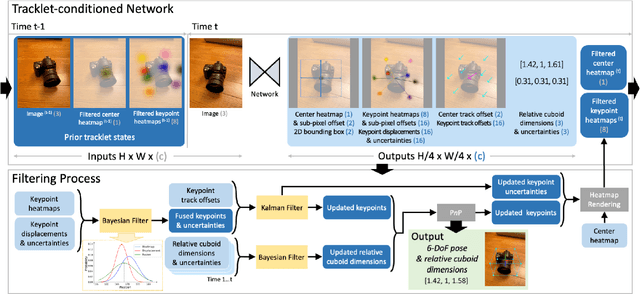
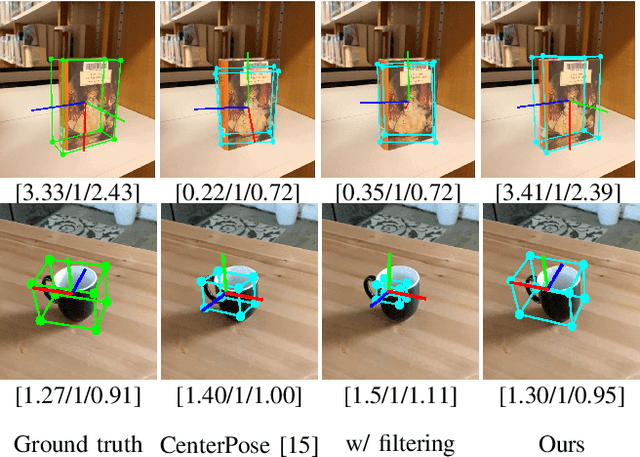
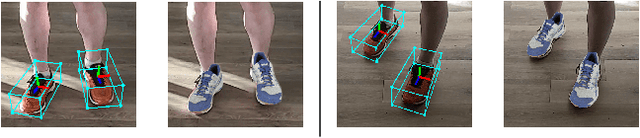
We propose a single-stage, category-level 6-DoF pose estimation algorithm that simultaneously detects and tracks instances of objects within a known category. Our method takes as input the previous and current frame from a monocular RGB video, as well as predictions from the previous frame, to predict the bounding cuboid and 6-DoF pose (up to scale). Internally, a deep network predicts distributions over object keypoints (vertices of the bounding cuboid) in image coordinates, after which a novel probabilistic filtering process integrates across estimates before computing the final pose using PnP. Our framework allows the system to take previous uncertainties into consideration when predicting the current frame, resulting in predictions that are more accurate and stable than single frame methods. Extensive experiments show that our method outperforms existing approaches on the challenging Objectron benchmark of annotated object videos. We also demonstrate the usability of our work in an augmented reality setting.