 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPD-1: Generative Pre-training for Driving
Dec 11, 2024



Modeling the evolutions of driving scenarios is important for the evaluation and decision-making of autonomous driving systems. Most existing methods focus on one aspect of scene evolution such as map generation, motion prediction, and trajectory planning. In this paper, we propose a unified Generative Pre-training for Driving (GPD-1) model to accomplish all these tasks altogether without additional fine-tuning. We represent each scene with ego, agent, and map tokens and formulate autonomous driving as a unified token generation problem. We adopt the autoregressive transformer architecture and use a scene-level attention mask to enable intra-scene bi-directional interactions. For the ego and agent tokens, we propose a hierarchical positional tokenizer to effectively encode both 2D positions and headings. For the map tokens, we train a map vector-quantized autoencoder to efficiently compress ego-centric semantic maps into discrete tokens. We pre-train our GPD-1 on the large-scale nuPlan dataset and conduct extensive experiments to evaluate its effectiveness. With different prompts, our GPD-1 successfully generalizes to various tasks without finetuning, including scene generation, traffic simulation, closed-loop simulation, map prediction, and motion planning. Code: https://github.com/wzzheng/GPD.
Bridging the Divide: Reconsidering Softmax and Linear Attention
Dec 09, 2024



Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.
Driv3R: Learning Dense 4D Reconstruction for Autonomous Driving
Dec 09, 2024



Realtime 4D reconstruction for dynamic scenes remains a crucial challenge for autonomous driving perception. Most existing methods rely on depth estimation through self-supervision or multi-modality sensor fusion. In this paper, we propose Driv3R, a DUSt3R-based framework that directly regresses per-frame point maps from multi-view image sequences. To achieve streaming dense reconstruction, we maintain a memory pool to reason both spatial relationships across sensors and dynamic temporal contexts to enhance multi-view 3D consistency and temporal integration. Furthermore, we employ a 4D flow predictor to identify moving objects within the scene to direct our network focus more on reconstructing these dynamic regions. Finally, we align all per-frame pointmaps consistently to the world coordinate system in an optimization-free manner. We conduct extensive experiments on the large-scale nuScenes dataset to evaluate the effectiveness of our method. Driv3R outperforms previous frameworks in 4D dynamic scene reconstruction, achieving 15x faster inference speed compared to methods requiring global alignment. Code: https://github.com/Barrybarry-Smith/Driv3R.
GaussianFormer-2: Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Dec 06, 2024



3D semantic occupancy prediction is an important task for robust vision-centric autonomous driving, which predicts fine-grained geometry and semantics of the surrounding scene. Most existing methods leverage dense grid-based scene representations, overlooking the spatial sparsity of the driving scenes. Although 3D semantic Gaussian serves as an object-centric sparse alternative, most of the Gaussians still describe the empty region with low efficiency. To address this, we propose a probabilistic Gaussian superposition model which interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. Furthermore, we adopt the exact Gaussian mixture model for semantics calculation to avoid unnecessary overlapping of Gaussians. To effectively initialize Gaussians in non-empty region, we design a distribution-based initialization module which learns the pixel-aligned occupancy distribution instead of the depth of surfaces. We conduct extensive experiments on nuScenes and KITTI-360 datasets and our GaussianFormer-2 achieves state-of-the-art performance with high efficiency. Code: https://github.com/huang-yh/GaussianFormer.
Stag-1: Towards Realistic 4D Driving Simulation with Video Generation Model
Dec 06, 2024



4D driving simulation is essential for developing realistic autonomous driving simulators. Despite advancements in existing methods for generating driving scenes, significant challenges remain in view transformation and spatial-temporal dynamic modeling. To address these limitations, we propose a Spatial-Temporal simulAtion for drivinG (Stag-1) model to reconstruct real-world scenes and design a controllable generative network to achieve 4D simulation. Stag-1 constructs continuous 4D point cloud scenes using surround-view data from autonomous vehicles. It decouples spatial-temporal relationships and produces coherent keyframe videos. Additionally, Stag-1 leverages video generation models to obtain photo-realistic and controllable 4D driving simulation videos from any perspective. To expand the range of view generation, we train vehicle motion videos based on decomposed camera poses, enhancing modeling capabilities for distant scenes. Furthermore, we reconstruct vehicle camera trajectories to integrate 3D points across consecutive views, enabling comprehensive scene understanding along the temporal dimension. Following extensive multi-level scene training, Stag-1 can simulate from any desired viewpoint and achieve a deep understanding of scene evolution under static spatial-temporal conditions. Compared to existing methods, our approach shows promising performance in multi-view scene consistency, background coherence, and accuracy, and contributes to the ongoing advancements in realistic autonomous driving simulation. Code: https://github.com/wzzheng/Stag.
Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Dec 05, 20243D semantic occupancy prediction is an important task for robust vision-centric autonomous driving, which predicts fine-grained geometry and semantics of the surrounding scene. Most existing methods leverage dense grid-based scene representations, overlooking the spatial sparsity of the driving scenes. Although 3D semantic Gaussian serves as an object-centric sparse alternative, most of the Gaussians still describe the empty region with low efficiency. To address this, we propose a probabilistic Gaussian superposition model which interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. Furthermore, we adopt the exact Gaussian mixture model for semantics calculation to avoid unnecessary overlapping of Gaussians. To effectively initialize Gaussians in non-empty region, we design a distribution-based initialization module which learns the pixel-aligned occupancy distribution instead of the depth of surfaces. We conduct extensive experiments on nuScenes and KITTI-360 datasets and our GaussianFormer-2 achieves state-of-the-art performance with high efficiency. Code: https://github.com/huang-yh/GaussianFormer.
EmbodiedOcc: Embodied 3D Occupancy Prediction for Vision-based Online Scene Understanding
Dec 05, 2024

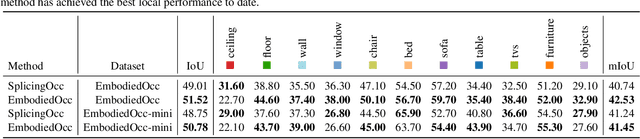

3D occupancy prediction provides a comprehensive description of the surrounding scenes and has become an essential task for 3D perception. Most existing methods focus on offline perception from one or a few views and cannot be applied to embodied agents which demands to gradually perceive the scene through progressive embodied exploration. In this paper, we formulate an embodied 3D occupancy prediction task to target this practical scenario and propose a Gaussian-based EmbodiedOcc framework to accomplish it. We initialize the global scene with uniform 3D semantic Gaussians and progressively update local regions observed by the embodied agent. For each update, we extract semantic and structural features from the observed image and efficiently incorporate them via deformable cross-attention to refine the regional Gaussians. Finally, we employ Gaussian-to-voxel splatting to obtain the global 3D occupancy from the updated 3D Gaussians. Our EmbodiedOcc assumes an unknown (i.e., uniformly distributed) environment and maintains an explicit global memory of it with 3D Gaussians. It gradually gains knowledge through local refinement of regional Gaussians, which is consistent with how humans understand new scenes through embodied exploration. We reorganize an EmbodiedOcc-ScanNet benchmark based on local annotations to facilitate the evaluation of the embodied 3D occupancy prediction task. Experiments demonstrate that our EmbodiedOcc outperforms existing local prediction methods and accomplishes the embodied occupancy prediction with high accuracy and strong expandability. Our code is available at: https://github.com/YkiWu/EmbodiedOcc.
XMask3D: Cross-modal Mask Reasoning for Open Vocabulary 3D Semantic Segmentation
Nov 20, 2024



Existing methodologies in open vocabulary 3D semantic segmentation primarily concentrate on establishing a unified feature space encompassing 3D, 2D, and textual modalities. Nevertheless, traditional techniques such as global feature alignment or vision-language model distillation tend to impose only approximate correspondence, struggling notably with delineating fine-grained segmentation boundaries. To address this gap, we propose a more meticulous mask-level alignment between 3D features and the 2D-text embedding space through a cross-modal mask reasoning framework, XMask3D. In our approach, we developed a mask generator based on the denoising UNet from a pre-trained diffusion model, leveraging its capability for precise textual control over dense pixel representations and enhancing the open-world adaptability of the generated masks. We further integrate 3D global features as implicit conditions into the pre-trained 2D denoising UNet, enabling the generation of segmentation masks with additional 3D geometry awareness. Subsequently, the generated 2D masks are employed to align mask-level 3D representations with the vision-language feature space, thereby augmenting the open vocabulary capability of 3D geometry embeddings. Finally, we fuse complementary 2D and 3D mask features, resulting in competitive performance across multiple benchmarks for 3D open vocabulary semantic segmentation. Code is available at https://github.com/wangzy22/XMask3D.
PixelGaussian: Generalizable 3D Gaussian Reconstruction from Arbitrary Views
Oct 24, 2024We propose PixelGaussian, an efficient feed-forward framework for learning generalizable 3D Gaussian reconstruction from arbitrary views. Most existing methods rely on uniform pixel-wise Gaussian representations, which learn a fixed number of 3D Gaussians for each view and cannot generalize well to more input views. Differently, our PixelGaussian dynamically adapts both the Gaussian distribution and quantity based on geometric complexity, leading to more efficient representations and significant improvements in reconstruction quality. Specifically, we introduce a Cascade Gaussian Adapter to adjust Gaussian distribution according to local geometry complexity identified by a keypoint scorer. CGA leverages deformable attention in context-aware hypernetworks to guide Gaussian pruning and splitting, ensuring accurate representation in complex regions while reducing redundancy. Furthermore, we design a transformer-based Iterative Gaussian Refiner module that refines Gaussian representations through direct image-Gaussian interactions. Our PixelGaussian can effectively reduce Gaussian redundancy as input views increase. We conduct extensive experiments on the large-scale ACID and RealEstate10K datasets, where our method achieves state-of-the-art performance with good generalization to various numbers of views. Code: https://github.com/Barrybarry-Smith/PixelGaussian.
V2M: Visual 2-Dimensional Mamba for Image Representation Learning
Oct 14, 2024



Mamba has garnered widespread attention due to its flexible design and efficient hardware performance to process 1D sequences based on the state space model (SSM). Recent studies have attempted to apply Mamba to the visual domain by flattening 2D images into patches and then regarding them as a 1D sequence. To compensate for the 2D structure information loss (e.g., local similarity) of the original image, most existing methods focus on designing different orders to sequentially process the tokens, which could only alleviate this issue to some extent. In this paper, we propose a Visual 2-Dimensional Mamba (V2M) model as a complete solution, which directly processes image tokens in the 2D space. We first generalize SSM to the 2-dimensional space which generates the next state considering two adjacent states on both dimensions (e.g., columns and rows). We then construct our V2M based on the 2-dimensional SSM formulation and incorporate Mamba to achieve hardware-efficient parallel processing. The proposed V2M effectively incorporates the 2D locality prior yet inherits the efficiency and input-dependent scalability of Mamba. Extensive experimental results on ImageNet classification and downstream visual tasks including object detection and instance segmentation on COCO and semantic segmentation on ADE20K demonstrate the effectiveness of our V2M compared with other visual backbones.