 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Jun 09, 2026We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $π_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
Graph Navier Stokes Networks
May 20, 2026Graph Neural Networks (GNNs) have emerged as a cornerstone of deep learning, with most existing methods rooted in graph signal processing and diffusion equations to model message passing. However, these approaches inherently suffer from the oversmoothing problem, where node features become indistinguishable as the network depth increases. Inspired by the Navier Stokes equations, we introduce Graph Navier Stokes Networks (GNSN), a novel architecture that transcends conventional diffusion-based message passing by incorporating convection into graph structures. GNSN defines a dynamic velocity field on the graph to govern convection, enabling more efficient and direct message propagation. By adaptively balancing convection and diffusion, GNSN is able to efficiently handle datasets with varying levels of homophily. Extensive evaluations across twelve real-world datasets demonstrate that GNSN consistently outperforms state-of-the-art baselines in classification accuracy. Moreover, experimental results further emphasize its effectiveness in alleviating the oversmoothing problem.
Analysing the Safety Pitfalls of Steering Vectors
Mar 25, 2026Activation steering has emerged as a powerful tool to shape LLM behavior without the need for weight updates. While its inherent brittleness and unreliability are well-documented, its safety implications remain underexplored. In this work, we present a systematic safety audit of steering vectors obtained with Contrastive Activation Addition (CAA), a widely used steering approach, under a unified evaluation protocol. Using JailbreakBench as benchmark, we show that steering vectors consistently influence the success rate of jailbreak attacks, with stronger amplification under simple template-based attacks. Across LLM families and sizes, steering the model in specific directions can drastically increase (up to 57%) or decrease (up to 50%) its attack success rate (ASR), depending on the targeted behavior. We attribute this phenomenon to the overlap between the steering vectors and the latent directions of refusal behavior. Thus, we offer a traceable explanation for this discovery. Together, our findings reveal the previously unobserved origin of this safety gap in LLMs, highlighting a trade-off between controllability and safety.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
A Modular Framework for Single-View 3D Reconstruction of Indoor Environments
Dec 17, 2025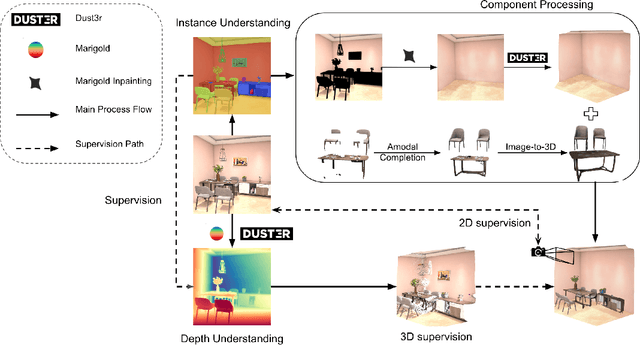

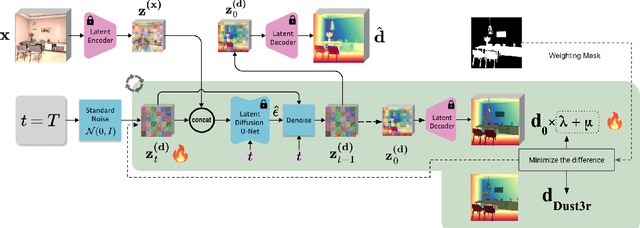
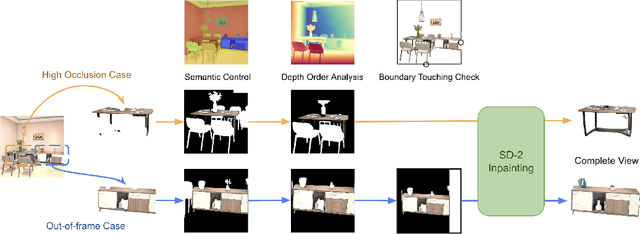
We propose a modular framework for single-view indoor scene 3D reconstruction, where several core modules are powered by diffusion techniques. Traditional approaches for this task often struggle with the complex instance shapes and occlusions inherent in indoor environments. They frequently overshoot by attempting to predict 3D shapes directly from incomplete 2D images, which results in limited reconstruction quality. We aim to overcome this limitation by splitting the process into two steps: first, we employ diffusion-based techniques to predict the complete views of the room background and occluded indoor instances, then transform them into 3D. Our modular framework makes contributions to this field through the following components: an amodal completion module for restoring the full view of occluded instances, an inpainting model specifically trained to predict room layouts, a hybrid depth estimation technique that balances overall geometric accuracy with fine detail expressiveness, and a view-space alignment method that exploits both 2D and 3D cues to ensure precise placement of instances within the scene. This approach effectively reconstructs both foreground instances and the room background from a single image. Extensive experiments on the 3D-Front dataset demonstrate that our method outperforms current state-of-the-art (SOTA) approaches in terms of both visual quality and reconstruction accuracy. The framework holds promising potential for applications in interior design, real estate, and augmented reality.
Injecting Falsehoods: Adversarial Man-in-the-Middle Attacks Undermining Factual Recall in LLMs
Nov 08, 2025LLMs are now an integral part of information retrieval. As such, their role as question answering chatbots raises significant concerns due to their shown vulnerability to adversarial man-in-the-middle (MitM) attacks. Here, we propose the first principled attack evaluation on LLM factual memory under prompt injection via Xmera, our novel, theory-grounded MitM framework. By perturbing the input given to "victim" LLMs in three closed-book and fact-based QA settings, we undermine the correctness of the responses and assess the uncertainty of their generation process. Surprisingly, trivial instruction-based attacks report the highest success rate (up to ~85.3%) while simultaneously having a high uncertainty for incorrectly answered questions. To provide a simple defense mechanism against Xmera, we train Random Forest classifiers on the response uncertainty levels to distinguish between attacked and unattacked queries (average AUC of up to ~96%). We believe that signaling users to be cautious about the answers they receive from black-box and potentially corrupt LLMs is a first checkpoint toward user cyberspace safety.
Image-to-Image Translation with Diffusion Transformers and CLIP-Based Image Conditioning
May 21, 2025Image-to-image translation aims to learn a mapping between a source and a target domain, enabling tasks such as style transfer, appearance transformation, and domain adaptation. In this work, we explore a diffusion-based framework for image-to-image translation by adapting Diffusion Transformers (DiT), which combine the denoising capabilities of diffusion models with the global modeling power of transformers. To guide the translation process, we condition the model on image embeddings extracted from a pre-trained CLIP encoder, allowing for fine-grained and structurally consistent translations without relying on text or class labels. We incorporate both a CLIP similarity loss to enforce semantic consistency and an LPIPS perceptual loss to enhance visual fidelity during training. We validate our approach on two benchmark datasets: face2comics, which translates real human faces to comic-style illustrations, and edges2shoes, which translates edge maps to realistic shoe images. Experimental results demonstrate that DiT, combined with CLIP-based conditioning and perceptual similarity objectives, achieves high-quality, semantically faithful translations, offering a promising alternative to GAN-based models for paired image-to-image translation tasks.
CT-PatchTST: Channel-Time Patch Time-Series Transformer for Long-Term Renewable Energy Forecasting
Jan 15, 2025Accurately predicting renewable energy output is crucial for the efficient integration of solar and wind power into modern energy systems. This study develops and evaluates an advanced deep learning model, Channel-Time Patch Time-Series Transformer (CT-PatchTST), to forecast the power output of photovoltaic and wind energy systems using annual offshore wind power, onshore wind power, and solar power generation data from Denmark. While the original Patch Time-Series Transformer(PatchTST) model employs a channel-independent (CI) approach, it tends to overlook inter-channel relationships during training, potentially leading to a loss of critical information. To address this limitation and further leverage the benefits of increased data granularity brought by CI, we propose CT-PatchTST. This enhanced model improves the processing of inter-channel information while maintaining the advantages of the channel-independent approach. The predictive performance of CT-PatchTST is rigorously analyzed, demonstrating its ability to provide precise and reliable energy forecasts. This work contributes to improving the predictability of renewable energy systems, supporting their broader adoption and integration into energy grids.
Generalization from Starvation: Hints of Universality in LLM Knowledge Graph Learning
Oct 10, 2024



Motivated by interpretability and reliability, we investigate how neural networks represent knowledge during graph learning, We find hints of universality, where equivalent representations are learned across a range of model sizes (from $10^2$ to $10^9$ parameters) and contexts (MLP toy models, LLM in-context learning and LLM training). We show that these attractor representations optimize generalization to unseen examples by exploiting properties of knowledge graph relations (e.g. symmetry and meta-transitivity). We find experimental support for such universality by showing that LLMs and simpler neural networks can be stitched, i.e., by stitching the first part of one model to the last part of another, mediated only by an affine or almost affine transformation. We hypothesize that this dynamic toward simplicity and generalization is driven by "intelligence from starvation": where overfitting is minimized by pressure to minimize the use of resources that are either scarce or competed for against other tasks.
CellAgent: An LLM-driven Multi-Agent Framework for Automated Single-cell Data Analysis
Jul 13, 2024Single-cell RNA sequencing (scRNA-seq) data analysis is crucial for biological research, as it enables the precise characterization of cellular heterogeneity. However, manual manipulation of various tools to achieve desired outcomes can be labor-intensive for researchers. To address this, we introduce CellAgent (http://cell.agent4science.cn/), an LLM-driven multi-agent framework, specifically designed for the automatic processing and execution of scRNA-seq data analysis tasks, providing high-quality results with no human intervention. Firstly, to adapt general LLMs to the biological field, CellAgent constructs LLM-driven biological expert roles - planner, executor, and evaluator - each with specific responsibilities. Then, CellAgent introduces a hierarchical decision-making mechanism to coordinate these biological experts, effectively driving the planning and step-by-step execution of complex data analysis tasks. Furthermore, we propose a self-iterative optimization mechanism, enabling CellAgent to autonomously evaluate and optimize solutions, thereby guaranteeing output quality. We evaluate CellAgent on a comprehensive benchmark dataset encompassing dozens of tissues and hundreds of distinct cell types. Evaluation results consistently show that CellAgent effectively identifies the most suitable tools and hyperparameters for single-cell analysis tasks, achieving optimal performance. This automated framework dramatically reduces the workload for science data analyses, bringing us into the "Agent for Science" era.