 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethink Sparse Signals for Pose-guided Text-to-image Generation
Jun 26, 2025Recent works favored dense signals (e.g., depth, DensePose), as an alternative to sparse signals (e.g., OpenPose), to provide detailed spatial guidance for pose-guided text-to-image generation. However, dense representations raised new challenges, including editing difficulties and potential inconsistencies with textual prompts. This fact motivates us to revisit sparse signals for pose guidance, owing to their simplicity and shape-agnostic nature, which remains underexplored. This paper proposes a novel Spatial-Pose ControlNet(SP-Ctrl), equipping sparse signals with robust controllability for pose-guided image generation. Specifically, we extend OpenPose to a learnable spatial representation, making keypoint embeddings discriminative and expressive. Additionally, we introduce keypoint concept learning, which encourages keypoint tokens to attend to the spatial positions of each keypoint, thus improving pose alignment. Experiments on animal- and human-centric image generation tasks demonstrate that our method outperforms recent spatially controllable T2I generation approaches under sparse-pose guidance and even matches the performance of dense signal-based methods. Moreover, SP-Ctrl shows promising capabilities in diverse and cross-species generation through sparse signals. Codes will be available at https://github.com/DREAMXFAR/SP-Ctrl.
Genome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025

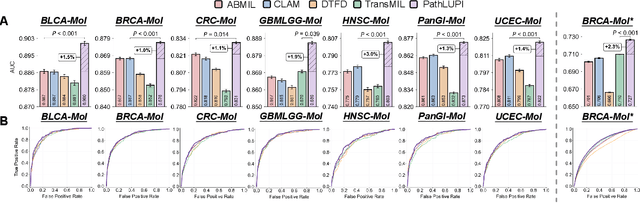

Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
Progressive Modality Cooperation for Multi-Modality Domain Adaptation
Jun 24, 2025In this work, we propose a new generic multi-modality domain adaptation framework called Progressive Modality Cooperation (PMC) to transfer the knowledge learned from the source domain to the target domain by exploiting multiple modality clues (\eg, RGB and depth) under the multi-modality domain adaptation (MMDA) and the more general multi-modality domain adaptation using privileged information (MMDA-PI) settings. Under the MMDA setting, the samples in both domains have all the modalities. In two newly proposed modules of our PMC, the multiple modalities are cooperated for selecting the reliable pseudo-labeled target samples, which captures the modality-specific information and modality-integrated information, respectively. Under the MMDA-PI setting, some modalities are missing in the target domain. Hence, to better exploit the multi-modality data in the source domain, we further propose the PMC with privileged information (PMC-PI) method by proposing a new multi-modality data generation (MMG) network. MMG generates the missing modalities in the target domain based on the source domain data by considering both domain distribution mismatch and semantics preservation, which are respectively achieved by using adversarial learning and conditioning on weighted pseudo semantics. Extensive experiments on three image datasets and eight video datasets for various multi-modality cross-domain visual recognition tasks under both MMDA and MMDA-PI settings clearly demonstrate the effectiveness of our proposed PMC framework.
ELBO-T2IAlign: A Generic ELBO-Based Method for Calibrating Pixel-level Text-Image Alignment in Diffusion Models
Jun 11, 2025Diffusion models excel at image generation. Recent studies have shown that these models not only generate high-quality images but also encode text-image alignment information through attention maps or loss functions. This information is valuable for various downstream tasks, including segmentation, text-guided image editing, and compositional image generation. However, current methods heavily rely on the assumption of perfect text-image alignment in diffusion models, which is not the case. In this paper, we propose using zero-shot referring image segmentation as a proxy task to evaluate the pixel-level image and class-level text alignment of popular diffusion models. We conduct an in-depth analysis of pixel-text misalignment in diffusion models from the perspective of training data bias. We find that misalignment occurs in images with small sized, occluded, or rare object classes. Therefore, we propose ELBO-T2IAlign, a simple yet effective method to calibrate pixel-text alignment in diffusion models based on the evidence lower bound (ELBO) of likelihood. Our method is training-free and generic, eliminating the need to identify the specific cause of misalignment and works well across various diffusion model architectures. Extensive experiments on commonly used benchmark datasets on image segmentation and generation have verified the effectiveness of our proposed calibration approach.
Reason-SVG: Hybrid Reward RL for Aha-Moments in Vector Graphics Generation
May 30, 2025Generating high-quality Scalable Vector Graphics (SVGs) is challenging for Large Language Models (LLMs), as it requires advanced reasoning for structural validity, semantic faithfulness, and visual coherence -- capabilities in which current LLMs often fall short. In this work, we introduce Reason-SVG, a novel framework designed to enhance LLM reasoning for SVG generation. Reason-SVG pioneers the "Drawing-with-Thought" (DwT) paradigm, in which models generate both SVG code and explicit design rationales, mimicking the human creative process. Reason-SVG adopts a two-stage training strategy: First, Supervised Fine-Tuning (SFT) trains the LLM on the DwT paradigm to activate foundational reasoning abilities. Second, Reinforcement Learning (RL), utilizing Group Relative Policy Optimization (GRPO), empowers the model to generate both DwT and SVGs rationales through refined, reward-driven reasoning. To facilitate reasoning-driven SVG generation, we design a Hybrid Reward function that evaluates the presence and utility of DwT reasoning, along with structural validity, semantic alignment, and visual quality. We also introduce the SVGX-DwT-10k dataset, a high-quality corpus of 10,000 SVG-DwT pairs, where each SVG code is generated based on explicit DwT reasoning. By integrating DwT, SFT, and Hybrid Reward-guided RL, Reason-SVG significantly improves LLM performance in generating accurate and visually compelling SVGs, potentially fostering "Aha moments" in design.
The Meeseeks Mesh: Spatially Consistent 3D Adversarial Objects for BEV Detector
May 29, 20253D object detection is a critical component in autonomous driving systems. It allows real-time recognition and detection of vehicles, pedestrians and obstacles under varying environmental conditions. Among existing methods, 3D object detection in the Bird's Eye View (BEV) has emerged as the mainstream framework. To guarantee a safe, robust and trustworthy 3D object detection, 3D adversarial attacks are investigated, where attacks are placed in 3D environments to evaluate the model performance, e.g. putting a film on a car, clothing a pedestrian. The vulnerability of 3D object detection models to 3D adversarial attacks serves as an important indicator to evaluate the robustness of the model against perturbations. To investigate this vulnerability, we generate non-invasive 3D adversarial objects tailored for real-world attack scenarios. Our method verifies the existence of universal adversarial objects that are spatially consistent across time and camera views. Specifically, we employ differentiable rendering techniques to accurately model the spatial relationship between adversarial objects and the target vehicle. Furthermore, we introduce an occlusion-aware module to enhance visual consistency and realism under different viewpoints. To maintain attack effectiveness across multiple frames, we design a BEV spatial feature-guided optimization strategy. Experimental results demonstrate that our approach can reliably suppress vehicle predictions from state-of-the-art 3D object detectors, serving as an important tool to test robustness of 3D object detection models before deployment. Moreover, the generated adversarial objects exhibit strong generalization capabilities, retaining its effectiveness at various positions and distances in the scene.
GoMatching++: Parameter- and Data-Efficient Arbitrary-Shaped Video Text Spotting and Benchmarking
May 28, 2025



Video text spotting (VTS) extends image text spotting (ITS) by adding text tracking, significantly increasing task complexity. Despite progress in VTS, existing methods still fall short of the performance seen in ITS. This paper identifies a key limitation in current video text spotters: limited recognition capability, even after extensive end-to-end training. To address this, we propose GoMatching++, a parameter- and data-efficient method that transforms an off-the-shelf image text spotter into a video specialist. The core idea lies in freezing the image text spotter and introducing a lightweight, trainable tracker, which can be optimized efficiently with minimal training data. Our approach includes two key components: (1) a rescoring mechanism to bridge the domain gap between image and video data, and (2) the LST-Matcher, which enhances the frozen image text spotter's ability to handle video text. We explore various architectures for LST-Matcher to ensure efficiency in both parameters and training data. As a result, GoMatching++ sets new performance records on challenging benchmarks such as ICDAR15-video, DSText, and BOVText, while significantly reducing training costs. To address the lack of curved text datasets in VTS, we introduce ArTVideo, a new benchmark featuring over 30% curved text with detailed annotations. We also provide a comprehensive statistical analysis and experimental results for ArTVideo. We believe that GoMatching++ and the ArTVideo benchmark will drive future advancements in video text spotting. The source code, models and dataset are publicly available at https://github.com/Hxyz-123/GoMatching.
What Makes for Text to 360-degree Panorama Generation with Stable Diffusion?
May 28, 2025Recent prosperity of text-to-image diffusion models, e.g. Stable Diffusion, has stimulated research to adapt them to 360-degree panorama generation. Prior work has demonstrated the feasibility of using conventional low-rank adaptation techniques on pre-trained diffusion models to generate panoramic images. However, the substantial domain gap between perspective and panoramic images raises questions about the underlying mechanisms enabling this empirical success. We hypothesize and examine that the trainable counterparts exhibit distinct behaviors when fine-tuned on panoramic data, and such an adaptation conceals some intrinsic mechanism to leverage the prior knowledge within the pre-trained diffusion models. Our analysis reveals the following: 1) the query and key matrices in the attention modules are responsible for common information that can be shared between the panoramic and perspective domains, thus are less relevant to panorama generation; and 2) the value and output weight matrices specialize in adapting pre-trained knowledge to the panoramic domain, playing a more critical role during fine-tuning for panorama generation. We empirically verify these insights by introducing a simple framework called UniPano, with the objective of establishing an elegant baseline for future research. UniPano not only outperforms existing methods but also significantly reduces memory usage and training time compared to prior dual-branch approaches, making it scalable for end-to-end panorama generation with higher resolution. The code will be released.
Prototype Embedding Optimization for Human-Object Interaction Detection in Livestreaming
May 28, 2025Livestreaming often involves interactions between streamers and objects, which is critical for understanding and regulating web content. While human-object interaction (HOI) detection has made some progress in general-purpose video downstream tasks, when applied to recognize the interaction behaviors between a streamer and different objects in livestreaming, it tends to focuses too much on the objects and neglects their interactions with the streamer, which leads to object bias. To solve this issue, we propose a prototype embedding optimization for human-object interaction detection (PeO-HOI). First, the livestreaming is preprocessed using object detection and tracking techniques to extract features of the human-object (HO) pairs. Then, prototype embedding optimization is adopted to mitigate the effect of object bias on HOI. Finally, after modelling the spatio-temporal context between HO pairs, the HOI detection results are obtained by the prediction head. The experimental results show that the detection accuracy of the proposed PeO-HOI method has detection accuracies of 37.19%@full, 51.42%@non-rare, 26.20%@rare on the publicly available dataset VidHOI, 45.13%@full, 62.78%@non-rare and 30.37%@rare on the self-built dataset BJUT-HOI, which effectively improves the HOI detection performance in livestreaming.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025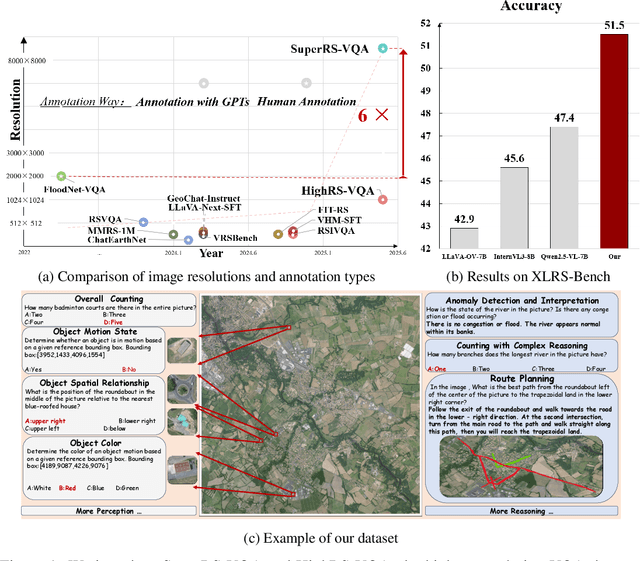

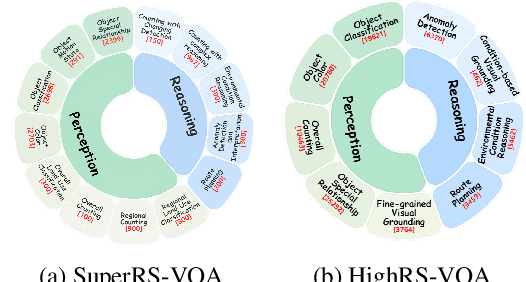

Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.