 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow You Act Tells a Lot: Privacy-Leakage Attack on Deep Reinforcement Learning
Apr 24, 2019
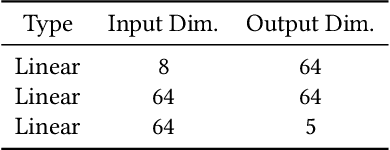
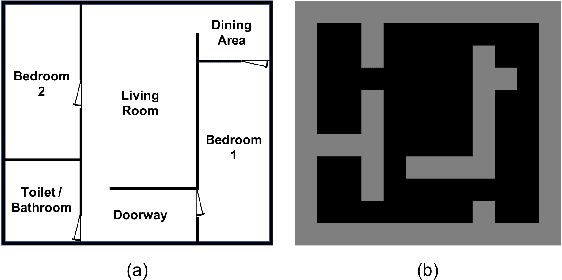
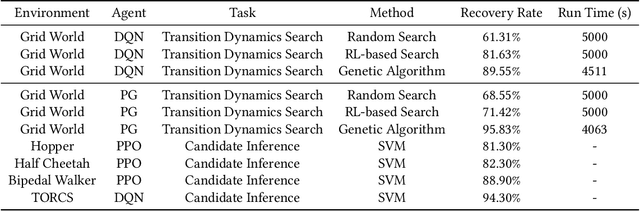
Machine learning has been widely applied to various applications, some of which involve training with privacy-sensitive data. A modest number of data breaches have been studied, including credit card information in natural language data and identities from face dataset. However, most of these studies focus on supervised learning models. As deep reinforcement learning (DRL) has been deployed in a number of real-world systems, such as indoor robot navigation, whether trained DRL policies can leak private information requires in-depth study. To explore such privacy breaches in general, we mainly propose two methods: environment dynamics search via genetic algorithm and candidate inference based on shadow policies. We conduct extensive experiments to demonstrate such privacy vulnerabilities in DRL under various settings. We leverage the proposed algorithms to infer floor plans from some trained Grid World navigation DRL agents with LiDAR perception. The proposed algorithm can correctly infer most of the floor plans and reaches an average recovery rate of 95.83% using policy gradient trained agents. In addition, we are able to recover the robot configuration in continuous control environments and an autonomous driving simulator with high accuracy. To the best of our knowledge, this is the first work to investigate privacy leakage in DRL settings and we show that DRL-based agents do potentially leak privacy-sensitive information from the trained policies.
A Frank-Wolfe Framework for Efficient and Effective Adversarial Attacks
Nov 27, 2018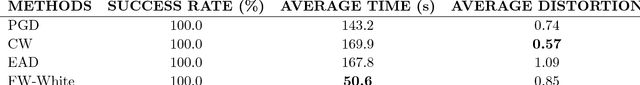
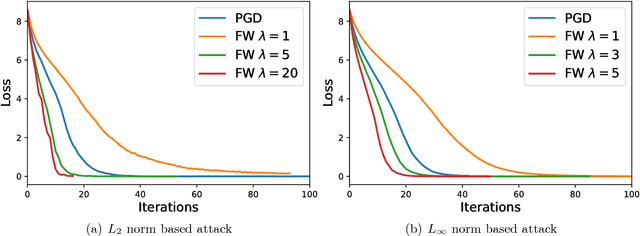
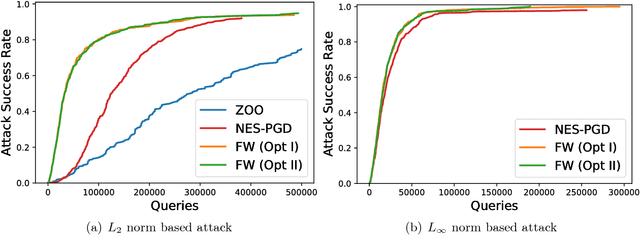
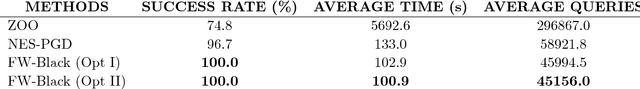
Depending on how much information an adversary can access to, adversarial attacks can be classified as white-box attack and black-box attack. In both cases, optimization-based attack algorithms can achieve relatively low distortions and high attack success rates. However, they usually suffer from poor time and query complexities, thereby limiting their practical usefulness. In this work, we focus on the problem of developing efficient and effective optimization-based adversarial attack algorithms. In particular, we propose a novel adversarial attack framework for both white-box and black-box settings based on the non-convex Frank-Wolfe algorithm. We show in theory that the proposed attack algorithms are efficient with an $O(1/\sqrt{T})$ convergence rate. The empirical results of attacking Inception V3 model and ResNet V2 model on the ImageNet dataset also verify the efficiency and effectiveness of the proposed algorithms. More specific, our proposed algorithms attain the highest attack success rate in both white-box and black-box attacks among all baselines, and are more time and query efficient than the state-of-the-art.
Random Warping Series: A Random Features Method for Time-Series Embedding
Sep 14, 2018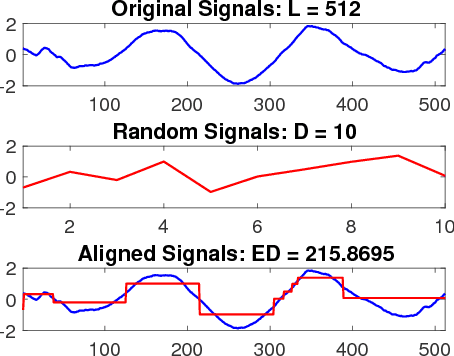
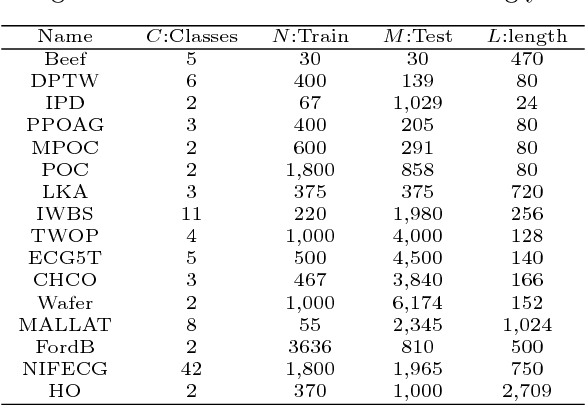
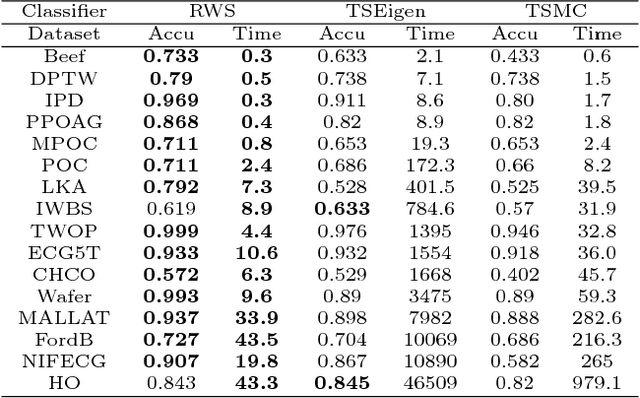
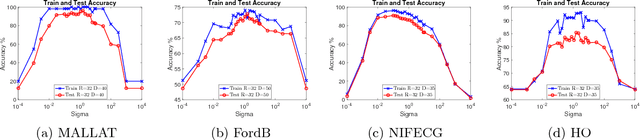
Time series data analytics has been a problem of substantial interests for decades, and Dynamic Time Warping (DTW) has been the most widely adopted technique to measure dissimilarity between time series. A number of global-alignment kernels have since been proposed in the spirit of DTW to extend its use to kernel-based estimation method such as support vector machine. However, those kernels suffer from diagonal dominance of the Gram matrix and a quadratic complexity w.r.t. the sample size. In this work, we study a family of alignment-aware positive definite (p.d.) kernels, with its feature embedding given by a distribution of \emph{Random Warping Series (RWS)}. The proposed kernel does not suffer from the issue of diagonal dominance while naturally enjoys a \emph{Random Features} (RF) approximation, which reduces the computational complexity of existing DTW-based techniques from quadratic to linear in terms of both the number and the length of time-series. We also study the convergence of the RF approximation for the domain of time series of unbounded length. Our extensive experiments on 16 benchmark datasets demonstrate that RWS outperforms or matches state-of-the-art classification and clustering methods in both accuracy and computational time. Our code and data is available at { \url{https://github.com/IBM/RandomWarpingSeries}}.
Query-Efficient Black-Box Attack by Active Learning
Sep 13, 2018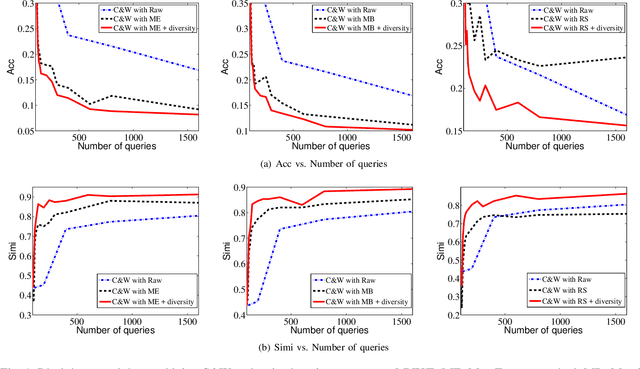
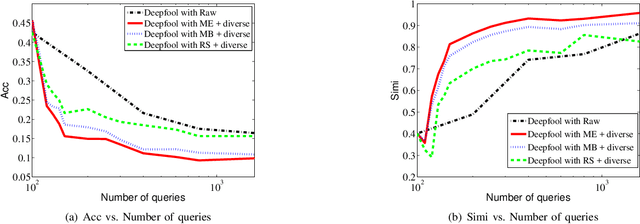
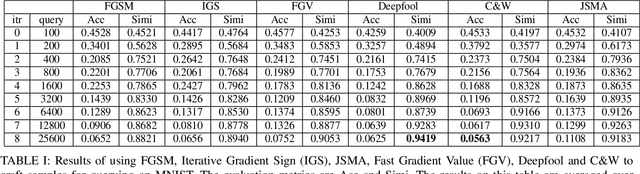
Deep neural network (DNN) as a popular machine learning model is found to be vulnerable to adversarial attack. This attack constructs adversarial examples by adding small perturbations to the raw input, while appearing unmodified to human eyes but will be misclassified by a well-trained classifier. In this paper, we focus on the black-box attack setting where attackers have almost no access to the underlying models. To conduct black-box attack, a popular approach aims to train a substitute model based on the information queried from the target DNN. The substitute model can then be attacked using existing white-box attack approaches, and the generated adversarial examples will be used to attack the target DNN. Despite its encouraging results, this approach suffers from poor query efficiency, i.e., attackers usually needs to query a huge amount of times to collect enough information for training an accurate substitute model. To this end, we first utilize state-of-the-art white-box attack methods to generate samples for querying, and then introduce an active learning strategy to significantly reduce the number of queries needed. Besides, we also propose a diversity criterion to avoid the sampling bias. Our extensive experimental results on MNIST and CIFAR-10 show that the proposed method can reduce more than $90\%$ of queries while preserve attacking success rates and obtain an accurate substitute model which is more than $85\%$ similar with the target oracle.
Towards Query Efficient Black-box Attacks: An Input-free Perspective
Sep 09, 2018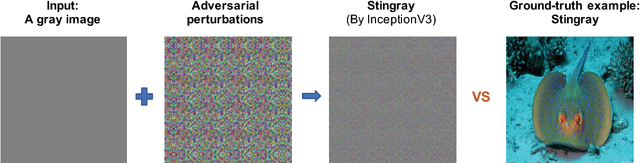
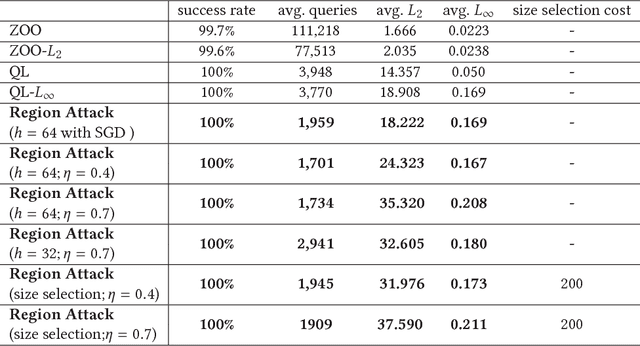
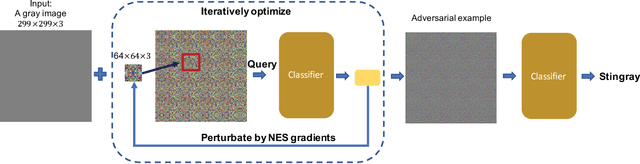
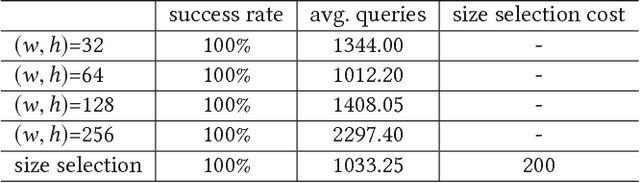
Recent studies have highlighted that deep neural networks (DNNs) are vulnerable to adversarial attacks, even in a black-box scenario. However, most of the existing black-box attack algorithms need to make a huge amount of queries to perform attacks, which is not practical in the real world. We note one of the main reasons for the massive queries is that the adversarial example is required to be visually similar to the original image, but in many cases, how adversarial examples look like does not matter much. It inspires us to introduce a new attack called \emph{input-free} attack, under which an adversary can choose an arbitrary image to start with and is allowed to add perceptible perturbations on it. Following this approach, we propose two techniques to significantly reduce the query complexity. First, we initialize an adversarial example with a gray color image on which every pixel has roughly the same importance for the target model. Then we shrink the dimension of the attack space by perturbing a small region and tiling it to cover the input image. To make our algorithm more effective, we stabilize a projected gradient ascent algorithm with momentum, and also propose a heuristic approach for region size selection. Through extensive experiments, we show that with only 1,701 queries on average, we can perturb a gray image to any target class of ImageNet with a 100\% success rate on InceptionV3. Besides, our algorithm has successfully defeated two real-world systems, the Clarifai food detection API and the Baidu Animal Identification API.
AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks
Sep 06, 2018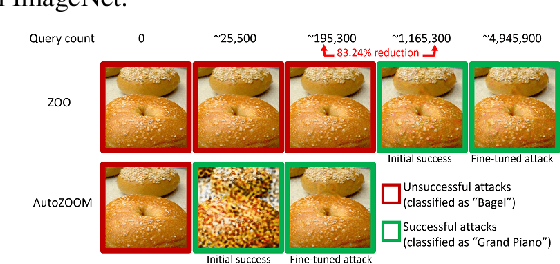
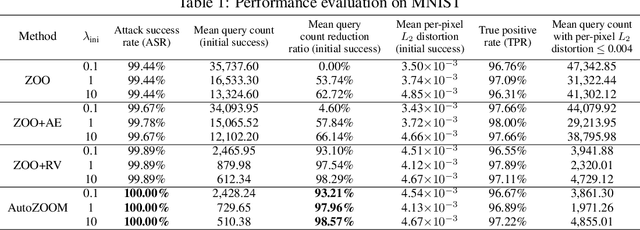
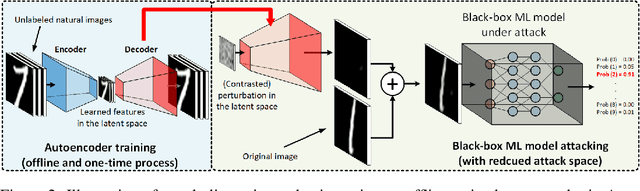
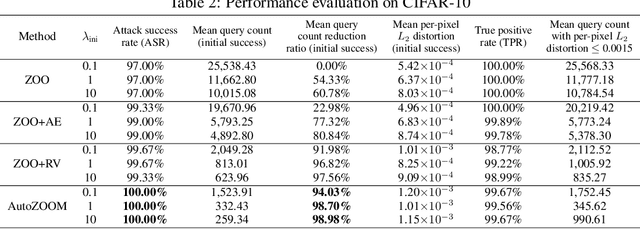
Recent studies have shown that adversarial examples in state-of-the-art image classifiers trained by deep neural networks (DNN) can be easily generated when the target model is transparent to an attacker, known as the white-box setting. However, when attacking a deployed machine learning service, one can only acquire the input-output correspondences of the target model; this is the so-called black-box attack setting. The major drawback of existing black-box attacks is the need for excessive model queries, which may give a false sense of model robustness due to inefficient query designs. To bridge this gap, we propose a generic framework for query-efficient black-box attacks. Our framework, AutoZOOM, which is short for Autoencoder-based Zeroth Order Optimization Method, has two novel building blocks towards efficient black-box attacks: (i) an adaptive random gradient estimation strategy to balance query counts and distortion, and (ii) an autoencoder that is either trained offline with unlabeled data or a bilinear resizing operation for attack acceleration. Experimental results suggest that, by applying AutoZOOM to a state-of-the-art black-box attack (ZOO), a significant reduction in model queries can be achieved without sacrificing the attack success rate and the visual quality of the resulting adversarial examples. In particular, when compared to the standard ZOO method, AutoZOOM can consistently reduce the mean query counts in finding successful adversarial examples (or reaching the same distortion level) by at least 93% on MNIST, CIFAR-10 and ImageNet datasets, leading to novel insights on adversarial robustness.
Universal Stagewise Learning for Non-Convex Problems with Convergence on Averaged Solutions
Sep 04, 2018Although stochastic gradient descent (SGD) method and its variants (e.g., stochastic momentum methods, AdaGrad) are the choice of algorithms for solving non-convex problems (especially deep learning), there still remain big gaps between the theory and the practice with many questions unresolved. For example, there is still a lack of theories of convergence for SGD and its variants that use stagewise step size and return an averaged solution in practice. In addition, theoretical insights of why adaptive step size of AdaGrad could improve non-adaptive step size of {\sgd} is still missing for non-convex optimization. This paper aims to address these questions and fill the gap between theory and practice. We propose a universal stagewise optimization framework for a broad family of {\bf non-smooth non-convex} (namely weakly convex) problems with the following key features: (i) at each stage any suitable stochastic convex optimization algorithms (e.g., SGD or AdaGrad) that return an averaged solution can be employed for minimizing a regularized convex problem; (ii) the step size is decreased in a stagewise manner; (iii) an averaged solution is returned as the final solution that is selected from all stagewise averaged solutions with sampling probabilities {\it increasing} as the stage number. Our theoretical results of stagewise AdaGrad exhibit its adaptive convergence, therefore shed insights on its faster convergence for problems with sparse stochastic gradients than stagewise SGD. To the best of our knowledge, these new results are the first of their kind for addressing the unresolved issues of existing theories mentioned earlier.
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
Aug 05, 2018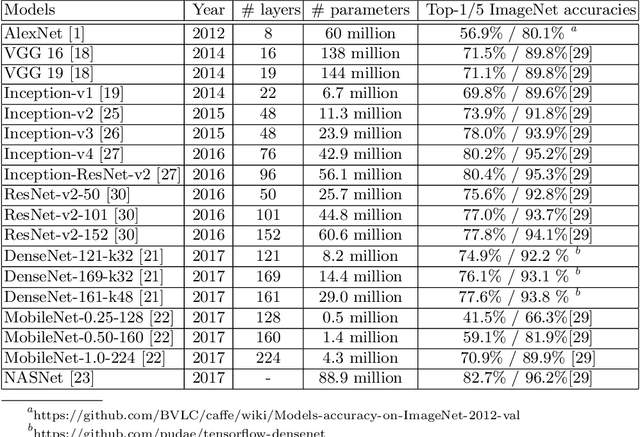
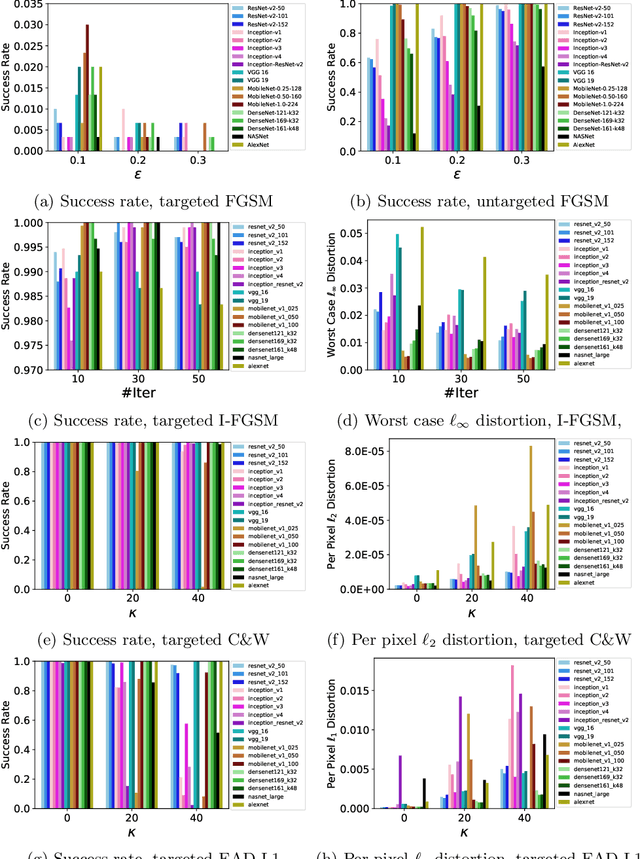
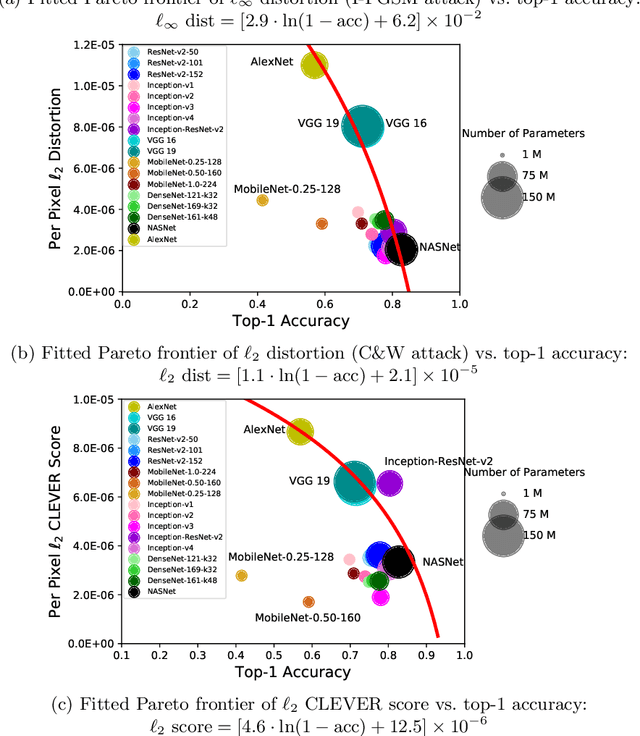
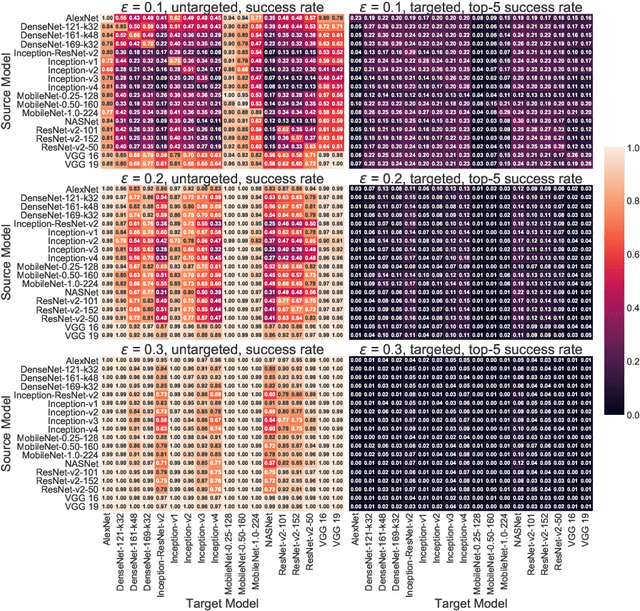
The prediction accuracy has been the long-lasting and sole standard for comparing the performance of different image classification models, including the ImageNet competition. However, recent studies have highlighted the lack of robustness in well-trained deep neural networks to adversarial examples. Visually imperceptible perturbations to natural images can easily be crafted and mislead the image classifiers towards misclassification. To demystify the trade-offs between robustness and accuracy, in this paper we thoroughly benchmark 18 ImageNet models using multiple robustness metrics, including the distortion, success rate and transferability of adversarial examples between 306 pairs of models. Our extensive experimental results reveal several new insights: (1) linear scaling law - the empirical $\ell_2$ and $\ell_\infty$ distortion metrics scale linearly with the logarithm of classification error; (2) model architecture is a more critical factor to robustness than model size, and the disclosed accuracy-robustness Pareto frontier can be used as an evaluation criterion for ImageNet model designers; (3) for a similar network architecture, increasing network depth slightly improves robustness in $\ell_\infty$ distortion; (4) there exist models (in VGG family) that exhibit high adversarial transferability, while most adversarial examples crafted from one model can only be transferred within the same family. Experiment code is publicly available at \url{https://github.com/huanzhang12/Adversarial_Survey}.
Defend Deep Neural Networks Against Adversarial Examples via Fixed andDynamic Quantized Activation Functions
Jul 18, 2018
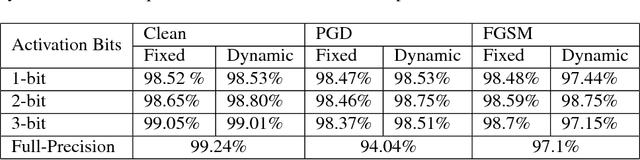
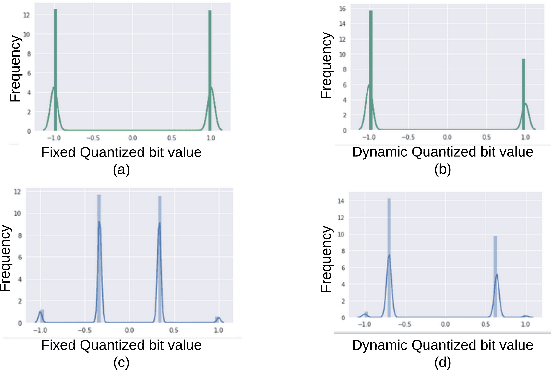
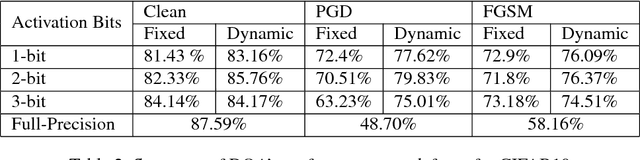
Recent studies have shown that deep neural networks (DNNs) are vulnerable to adversarial attacks. To this end, many defense approaches that attempt to improve the robustness of DNNs have been proposed. In a separate and yet related area, recent works have explored to quantize neural network weights and activation functions into low bit-width to compress model size and reduce computational complexity. In this work,we find that these two different tracks, namely the pursuit of network compactness and robustness, can bemerged into one and give rise to networks of both advantages. To the best of our knowledge, this is the first work that uses quantization of activation functions to defend against adversarial examples. We also propose to train robust neural networks by using adaptive quantization techniques for the activation functions. Our proposed Dynamic Quantized Activation (DQA) is verified through a wide range of experiments with the MNIST and CIFAR-10 datasets under different white-box attack methods, including FGSM, PGD, andC&W attacks. Furthermore, Zeroth Order Optimization and substitute model based black-box attacks are also considered in this work. The experimental results clearly show that the robustness of DNNs could be greatly improved using the proposed DQA.
Query-Efficient Hard-label Black-box Attack:An Optimization-based Approach
Jul 12, 2018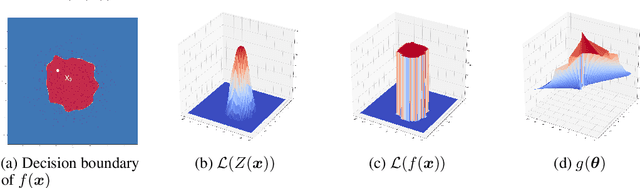
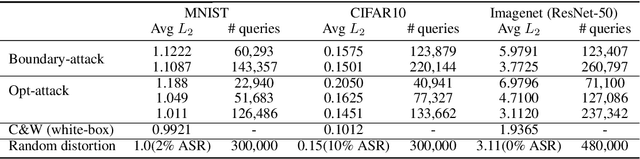
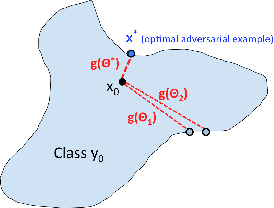
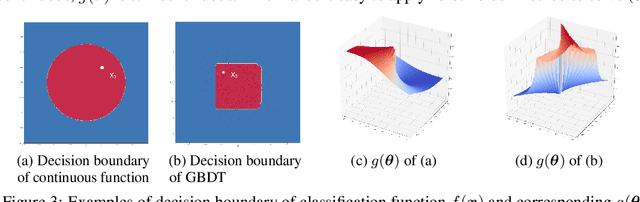
We study the problem of attacking a machine learning model in the hard-label black-box setting, where no model information is revealed except that the attacker can make queries to probe the corresponding hard-label decisions. This is a very challenging problem since the direct extension of state-of-the-art white-box attacks (e.g., CW or PGD) to the hard-label black-box setting will require minimizing a non-continuous step function, which is combinatorial and cannot be solved by a gradient-based optimizer. The only current approach is based on random walk on the boundary, which requires lots of queries and lacks convergence guarantees. We propose a novel way to formulate the hard-label black-box attack as a real-valued optimization problem which is usually continuous and can be solved by any zeroth order optimization algorithm. For example, using the Randomized Gradient-Free method, we are able to bound the number of iterations needed for our algorithm to achieve stationary points. We demonstrate that our proposed method outperforms the previous random walk approach to attacking convolutional neural networks on MNIST, CIFAR, and ImageNet datasets. More interestingly, we show that the proposed algorithm can also be used to attack other discrete and non-continuous machine learning models, such as Gradient Boosting Decision Trees (GBDT).