 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Apr 21, 2025We introduce Eagle 2.5, a family of frontier vision-language models (VLMs) for long-context multimodal learning. Our work addresses the challenges in long video comprehension and high-resolution image understanding, introducing a generalist framework for both tasks. The proposed training framework incorporates Automatic Degrade Sampling and Image Area Preservation, two techniques that preserve contextual integrity and visual details. The framework also includes numerous efficiency optimizations in the pipeline for long-context data training. Finally, we propose Eagle-Video-110K, a novel dataset that integrates both story-level and clip-level annotations, facilitating long-video understanding. Eagle 2.5 demonstrates substantial improvements on long-context multimodal benchmarks, providing a robust solution to the limitations of existing VLMs. Notably, our best model Eagle 2.5-8B achieves 72.4% on Video-MME with 512 input frames, matching the results of top-tier commercial model such as GPT-4o and large-scale open-source models like Qwen2.5-VL-72B and InternVL2.5-78B.
Token-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025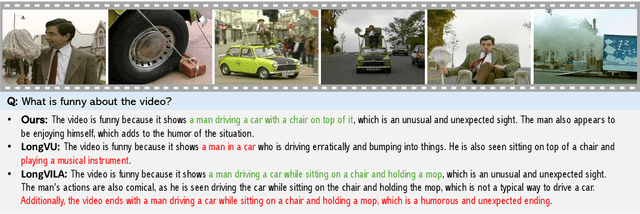
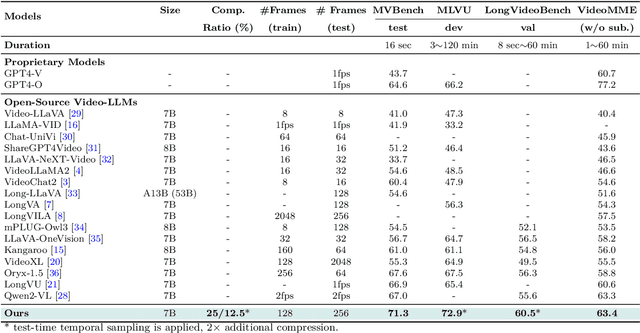
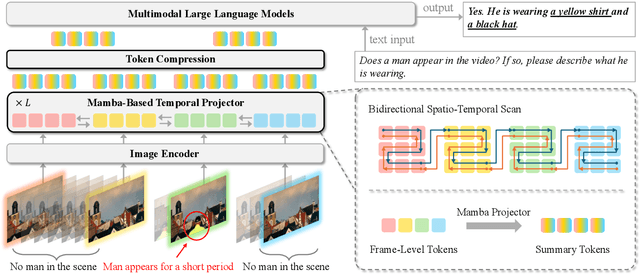
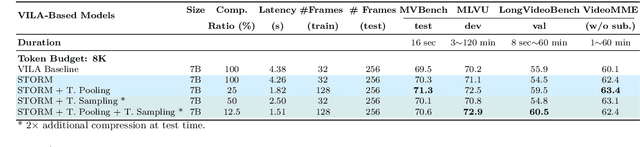
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
$\texttt{PatentAgent}$: Intelligent Agent for Automated Pharmaceutical Patent Analysis
Oct 25, 2024Pharmaceutical patents play a vital role in biochemical industries, especially in drug discovery, providing researchers with unique early access to data, experimental results, and research insights. With the advancement of machine learning, patent analysis has evolved from manual labor to tasks assisted by automatic tools. However, there still lacks an unified agent that assists every aspect of patent analysis, from patent reading to core chemical identification. Leveraging the capabilities of Large Language Models (LLMs) to understand requests and follow instructions, we introduce the $\textbf{first}$ intelligent agent in this domain, $\texttt{PatentAgent}$, poised to advance and potentially revolutionize the landscape of pharmaceutical research. $\texttt{PatentAgent}$ comprises three key end-to-end modules -- $\textit{PA-QA}$, $\textit{PA-Img2Mol}$, and $\textit{PA-CoreId}$ -- that respectively perform (1) patent question-answering, (2) image-to-molecular-structure conversion, and (3) core chemical structure identification, addressing the essential needs of scientists and practitioners in pharmaceutical patent analysis. Each module of $\texttt{PatentAgent}$ demonstrates significant effectiveness with the updated algorithm and the synergistic design of $\texttt{PatentAgent}$ framework. $\textit{PA-Img2Mol}$ outperforms existing methods across CLEF, JPO, UOB, and USPTO patent benchmarks with an accuracy gain between 2.46% and 8.37% while $\textit{PA-CoreId}$ realizes accuracy improvement ranging from 7.15% to 7.62% on PatentNetML benchmark. Our code and dataset will be publicly available.
Slot State Space Models
Jun 18, 2024Recent State Space Models (SSMs) such as S4, S5, and Mamba have shown remarkable computational benefits in long-range temporal dependency modeling. However, in many sequence modeling problems, the underlying process is inherently modular and it is of interest to have inductive biases that mimic this modular structure. In this paper, we introduce SlotSSMs, a novel framework for incorporating independent mechanisms into SSMs to preserve or encourage separation of information. Unlike conventional SSMs that maintain a monolithic state vector, SlotSSMs maintains the state as a collection of multiple vectors called slots. Crucially, the state transitions are performed independently per slot with sparse interactions across slots implemented via the bottleneck of self-attention. In experiments, we evaluate our model in object-centric video understanding, 3D visual reasoning, and video prediction tasks, which involve modeling multiple objects and their long-range temporal dependencies. We find that our proposed design offers substantial performance gains over existing sequence modeling methods.
SceneTextGen: Layout-Agnostic Scene Text Image Synthesis with Diffusion Models
Jun 03, 2024



While diffusion models have significantly advanced the quality of image generation, their capability to accurately and coherently render text within these images remains a substantial challenge. Conventional diffusion-based methods for scene text generation are typically limited by their reliance on an intermediate layout output. This dependency often results in a constrained diversity of text styles and fonts, an inherent limitation stemming from the deterministic nature of the layout generation phase. To address these challenges, this paper introduces SceneTextGen, a novel diffusion-based model specifically designed to circumvent the need for a predefined layout stage. By doing so, SceneTextGen facilitates a more natural and varied representation of text. The novelty of SceneTextGen lies in its integration of three key components: a character-level encoder for capturing detailed typographic properties, coupled with a character-level instance segmentation model and a word-level spotting model to address the issues of unwanted text generation and minor character inaccuracies. We validate the performance of our method by demonstrating improved character recognition rates on generated images across different public visual text datasets in comparison to both standard diffusion based methods and text specific methods.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023



DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Object-Centric Slot Diffusion
Mar 20, 2023



Despite remarkable recent advances, making object-centric learning work for complex natural scenes remains the main challenge. The recent success of adopting the transformer-based image generative model in object-centric learning suggests that having a highly expressive image generator is crucial for dealing with complex scenes. In this paper, inspired by this observation, we aim to answer the following question: can we benefit from the other pillar of modern deep generative models, i.e., the diffusion models, for object-centric learning and what are the pros and cons of such a model? To this end, we propose a new object-centric learning model, Latent Slot Diffusion (LSD). LSD can be seen from two perspectives. From the perspective of object-centric learning, it replaces the conventional slot decoders with a latent diffusion model conditioned on the object slots. Conversely, from the perspective of diffusion models, it is the first unsupervised compositional conditional diffusion model which, unlike traditional diffusion models, does not require supervised annotation such as a text description to learn to compose. In experiments on various object-centric tasks, including the FFHQ dataset for the first time in this line of research, we demonstrate that LSD significantly outperforms the state-of-the-art transformer-based decoder, particularly when the scene is more complex. We also show a superior quality in unsupervised compositional generation.
Generative Neurosymbolic Machines
Oct 23, 2020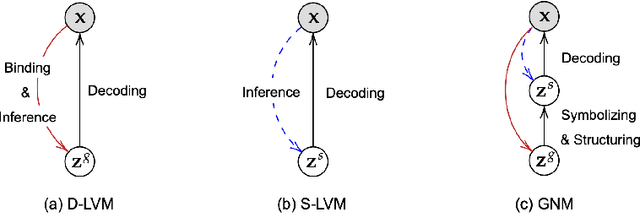
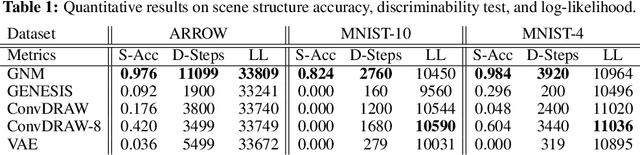


Reconciling symbolic and distributed representations is a crucial challenge that can potentially resolve the limitations of current deep learning. Remarkable advances in this direction have been achieved recently via generative object-centric representation models. While learning a recognition model that infers object-centric symbolic representations like bounding boxes from raw images in an unsupervised way, no such model can provide another important ability of a generative model, i.e., generating (sampling) according to the structure of learned world density. In this paper, we propose Generative Neurosymbolic Machines, a generative model that combines the benefits of distributed and symbolic representations to support both structured representations of symbolic components and density-based generation. These two crucial properties are achieved by a two-layer latent hierarchy with the global distributed latent for flexible density modeling and the structured symbolic latent map. To increase the model flexibility in this hierarchical structure, we also propose the StructDRAW prior. In experiments, we show that the proposed model significantly outperforms the previous structured representation models as well as the state-of-the-art non-structured generative models in terms of both structure accuracy and image generation quality.
Improving Generative Imagination in Object-Centric World Models
Oct 05, 2020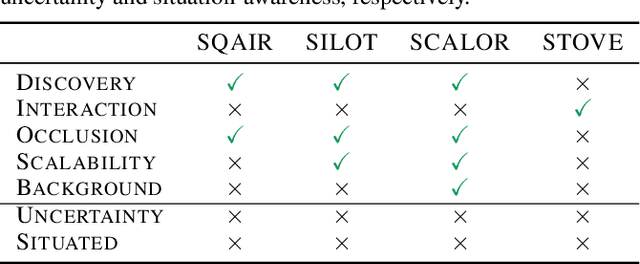
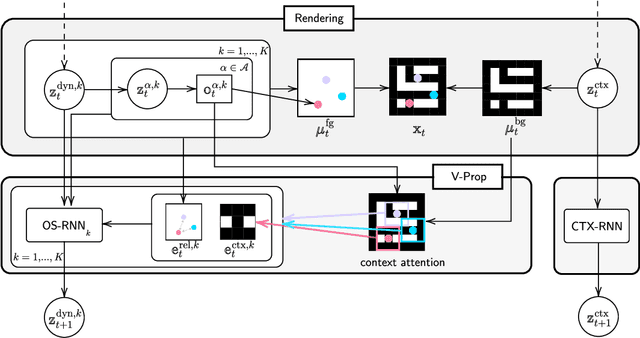
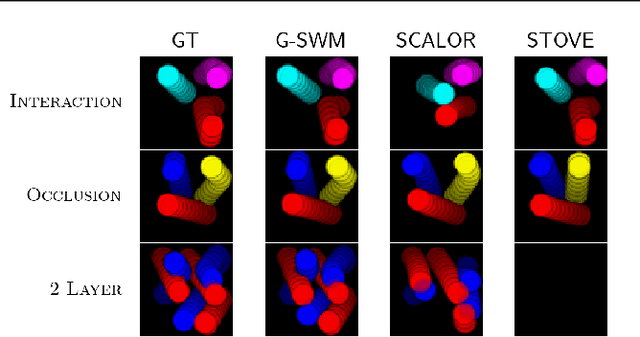
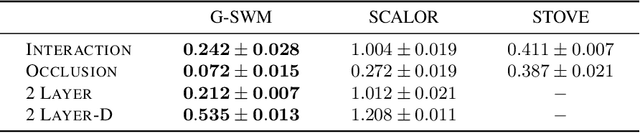
The remarkable recent advances in object-centric generative world models raise a few questions. First, while many of the recent achievements are indispensable for making a general and versatile world model, it is quite unclear how these ingredients can be integrated into a unified framework. Second, despite using generative objectives, abilities for object detection and tracking are mainly investigated, leaving the crucial ability of temporal imagination largely under question. Third, a few key abilities for more faithful temporal imagination such as multimodal uncertainty and situation-awareness are missing. In this paper, we introduce Generative Structured World Models (G-SWM). The G-SWM achieves the versatile world modeling not only by unifying the key properties of previous models in a principled framework but also by achieving two crucial new abilities, multimodal uncertainty and situation-awareness. Our thorough investigation on the temporal generation ability in comparison to the previous models demonstrates that G-SWM achieves the versatility with the best or comparable performance for all experiment settings including a few complex settings that have not been tested before.
SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
Feb 18, 2020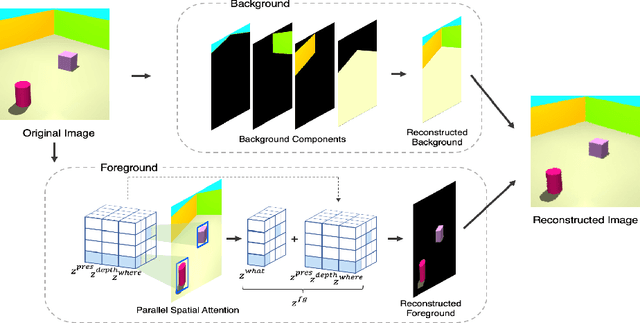
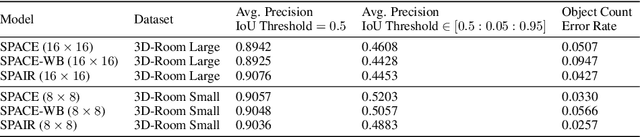
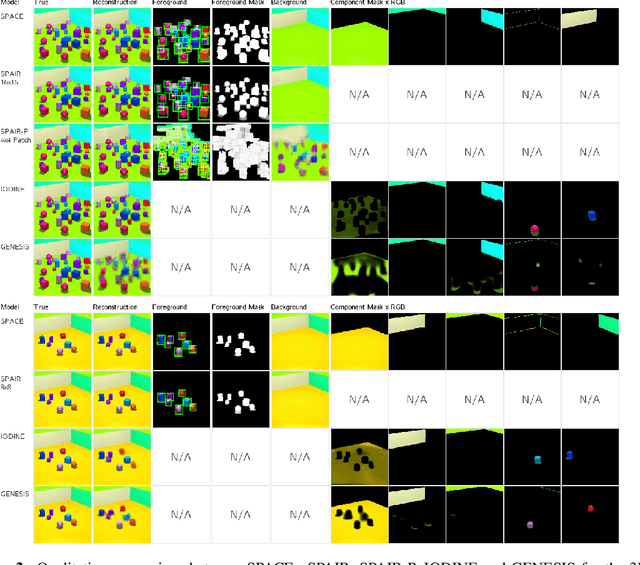
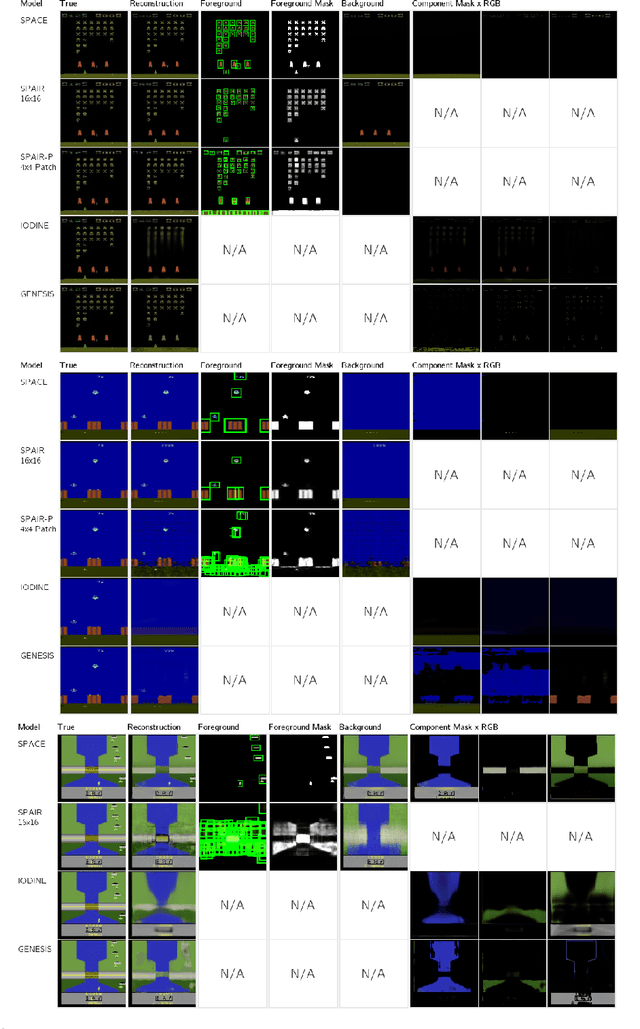
The ability to decompose complex multi-object scenes into meaningful abstractions like objects is fundamental to achieve higher-level cognition. Previous approaches for unsupervised object-oriented scene representation learning are either based on spatial-attention or scene-mixture approaches and limited in scalability which is a main obstacle towards modeling real-world scenes. In this paper, we propose a generative latent variable model, called SPACE, that provides a unified probabilistic modeling framework that combines the best of spatial-attention and scene-mixture approaches. SPACE can explicitly provide factorized object representations for foreground objects while also decomposing background segments of complex morphology. Previous models are good at either of these, but not both. SPACE also resolves the scalability problems of previous methods by incorporating parallel spatial-attention and thus is applicable to scenes with a large number of objects without performance degradations. We show through experiments on Atari and 3D-Rooms that SPACE achieves the above properties consistently in comparison to SPAIR, IODINE, and GENESIS. Results of our experiments can be found on our project website: https://sites.google.com/view/space-project-page