 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Recursive Reasoning
May 20, 2026How should future neural reasoning systems implement extended computation? Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative latent-state refinement with shared transition functions. Yet existing RRMs are largely deterministic, following a single latent trajectory and converging to a single prediction. We introduce Generative Recursive reAsoning Models (GRAM), a framework that turns recursive latent reasoning into probabilistic multi-trajectory computation. GRAM models reasoning as a stochastic latent trajectory, enabling multiple hypotheses, alternative solution strategies, and inference-time scaling through both recursive depth and parallel trajectory sampling. This yields a latent-variable generative model supporting conditional reasoning via $p_θ(y \mid x)$ and, with fixed or absent inputs, unconditional generation via $p_θ(x)$. Trained with amortized variational inference, GRAM improves over deterministic recurrent and recursive baselines on structured reasoning and multi-solution constraint satisfaction tasks, while demonstrating an unconditional generation capability. https://ahn-ml.github.io/gram-website
Inference-Time Scaling in Diffusion Models through Iterative Partial Refinement
May 19, 2026Inference-time scaling has emerged as a major approach for improving reasoning capabilities, and has been increasingly applied to diffusion models. However, existing inference-time scaling methods for diffusion models typically rely on external verifiers or reward models to rank and select samples, limiting their scalability to settings where such evaluators are available and reliable. Moreover, while recent diffusion models perform sequential inference with region-wise, mixed-noise conditioning, inference-time scaling tailored to this setting remains relatively underexplored. We propose Iterative Partial Refinement (IPR), an inference-time scaling method for sequential diffusion that requires no external verifier. Starting from an already-generated sample, IPR re-noises a subset of regions and regenerates them conditioned on the remaining regions, enabling the model to revise earlier decisions under a richer context than was available during the initial generation. This iterative partial refinement produces more globally consistent samples without external verification. On reasoning tasks requiring global constraint satisfaction, IPR consistently improves performance: on MNIST Sudoku, the valid solution rate increases from 55.8% to 75.0%. These results show that iterative partial refinement alone can serve as an effective inference-time scaling strategy for diffusion models in sequential, mixed-noise settings. Code is available at: https://github.com/ahn-ml/IPR
Learning to Theorize the World from Observation
May 05, 2026What does it mean to understand the world? Contemporary world models often operationalize understanding as accurate future prediction in latent or observation space. Developmental cognitive science, however, suggests a different view: human understanding emerges through the construction of internal theories of how the world works, even before mature language is acquired. Inspired by this theory-building view of cognition, we introduce Learning-to-Theorize, a learning paradigm for inferring explicit explanatory theories of the world from raw, non-textual observations. We instantiate this paradigm with the Neural Theorizer (NEO), a probabilistic neural model that induces latent programs as a learned Language of Thought and executes them through a shared transition model. In NEO, a theory is represented as an executable, compositional program whose learned primitives can be systematically recombined to explain novel phenomena. Experiments show that this formulation enables explanation-driven generalization, allowing observations to be understood in terms of the programs that generate them.
Understanding LoRA as Knowledge Memory: An Empirical Analysis
Mar 01, 2026Continuous knowledge updating for pre-trained large language models (LLMs) is increasingly necessary yet remains challenging. Although inference-time methods like In-Context Learning (ICL) and Retrieval-Augmented Generation (RAG) are popular, they face constraints in context budgets, costs, and retrieval fragmentation. Departing from these context-dependent paradigms, this work investigates a parametric approach using Low-Rank Adaptation (LoRA) as a modular knowledge memory. Although few recent works examine this concept, the fundamental mechanics governing its capacity and composability remain largely unexplored. We bridge this gap through the first systematic empirical study mapping the design space of LoRA-based memory, ranging from characterizing storage capacity and optimizing internalization to scaling multi-module systems and evaluating long-context reasoning. Rather than proposing a single architecture, we provide practical guidance on the operational boundaries of LoRA memory. Overall, our findings position LoRA as the complementary axis of memory alongside RAG and ICL, offering distinct advantages.
Loopholing Discrete Diffusion: Deterministic Bypass of the Sampling Wall
Oct 22, 2025Discrete diffusion models offer a promising alternative to autoregressive generation through parallel decoding, but they suffer from a sampling wall: once categorical sampling occurs, rich distributional information collapses into one-hot vectors and cannot be propagated across steps, forcing subsequent steps to operate with limited information. To mitigate this problem, we introduce Loopholing, a novel and simple mechanism that preserves this information via a deterministic latent pathway, leading to Loopholing Discrete Diffusion Models (LDDMs). Trained efficiently with a self-conditioning strategy, LDDMs achieve substantial gains-reducing generative perplexity by up to 61% over prior baselines, closing (and in some cases surpassing) the gap with autoregressive models, and producing more coherent text. Applied to reasoning tasks, LDDMs also improve performance on arithmetic benchmarks such as Countdown and Game of 24. These results also indicate that loopholing mitigates idle steps and oscillations, providing a scalable path toward high-quality non-autoregressive text generation.
Discrete JEPA: Learning Discrete Token Representations without Reconstruction
Jun 17, 2025



The cornerstone of cognitive intelligence lies in extracting hidden patterns from observations and leveraging these principles to systematically predict future outcomes. However, current image tokenization methods demonstrate significant limitations in tasks requiring symbolic abstraction and logical reasoning capabilities essential for systematic inference. To address this challenge, we propose Discrete-JEPA, extending the latent predictive coding framework with semantic tokenization and novel complementary objectives to create robust tokenization for symbolic reasoning tasks. Discrete-JEPA dramatically outperforms baselines on visual symbolic prediction tasks, while striking visual evidence reveals the spontaneous emergence of deliberate systematic patterns within the learned semantic token space. Though an initial model, our approach promises a significant impact for advancing Symbolic world modeling and planning capabilities in artificial intelligence systems.
Fast Monte Carlo Tree Diffusion: 100x Speedup via Parallel Sparse Planning
Jun 11, 2025Diffusion models have recently emerged as a powerful approach for trajectory planning. However, their inherently non-sequential nature limits their effectiveness in long-horizon reasoning tasks at test time. The recently proposed Monte Carlo Tree Diffusion (MCTD) offers a promising solution by combining diffusion with tree-based search, achieving state-of-the-art performance on complex planning problems. Despite its strengths, our analysis shows that MCTD incurs substantial computational overhead due to the sequential nature of tree search and the cost of iterative denoising. To address this, we propose Fast-MCTD, a more efficient variant that preserves the strengths of MCTD while significantly improving its speed and scalability. Fast-MCTD integrates two techniques: Parallel MCTD, which enables parallel rollouts via delayed tree updates and redundancy-aware selection; and Sparse MCTD, which reduces rollout length through trajectory coarsening. Experiments show that Fast-MCTD achieves up to 100x speedup over standard MCTD while maintaining or improving planning performance. Remarkably, it even outperforms Diffuser in inference speed on some tasks, despite Diffuser requiring no search and yielding weaker solutions. These results position Fast-MCTD as a practical and scalable solution for diffusion-based inference-time reasoning.
Slot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
May 26, 2025Recently, multimodal large language models (MLLMs) have emerged as a key approach in achieving artificial general intelligence. In particular, vision-language MLLMs have been developed to generate not only text but also visual outputs from multimodal inputs. This advancement requires efficient image tokens that LLMs can process effectively both in input and output. However, existing image tokenization methods for MLLMs typically capture only global abstract concepts or uniformly segmented image patches, restricting MLLMs' capability to effectively understand or generate detailed visual content, particularly at the object level. To address this limitation, we propose an object-centric visual tokenizer based on Slot Attention specifically for MLLMs. In particular, based on the Q-Former encoder, diffusion decoder, and residual vector quantization, our proposed discretized slot tokens can encode local visual details while maintaining high-level semantics, and also align with textual data to be integrated seamlessly within a unified next-token prediction framework of LLMs. The resulting Slot-MLLM demonstrates significant performance improvements over baselines with previous visual tokenizers across various vision-language tasks that entail local detailed comprehension and generation. Notably, this work is the first demonstration of the feasibility of object-centric slot attention performed with MLLMs and in-the-wild natural images.
Adaptive Cyclic Diffusion for Inference Scaling
May 20, 2025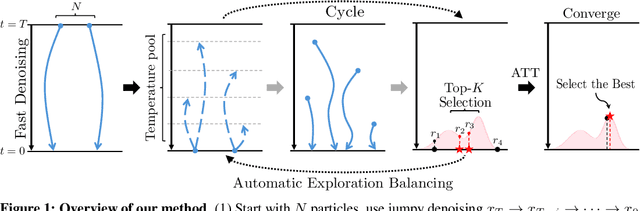

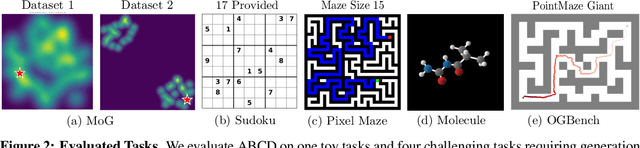
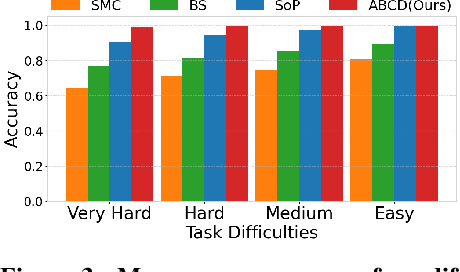
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.
Search-Based Correction of Reasoning Chains for Language Models
May 17, 2025Chain-of-Thought (CoT) reasoning has advanced the capabilities and transparency of language models (LMs); however, reasoning chains can contain inaccurate statements that reduce performance and trustworthiness. To address this, we introduce a new self-correction framework that augments each reasoning step in a CoT with a latent variable indicating its veracity, enabling modeling of all possible truth assignments rather than assuming correctness throughout. To efficiently explore this expanded space, we introduce Search Corrector, a discrete search algorithm over boolean-valued veracity assignments. It efficiently performs otherwise intractable inference in the posterior distribution over veracity assignments by leveraging the LM's joint likelihood over veracity and the final answer as a proxy reward. This efficient inference-time correction method facilitates supervised fine-tuning of an Amortized Corrector by providing pseudo-labels for veracity. The Amortized Corrector generalizes self-correction, enabling accurate zero-shot veracity inference in novel contexts. Empirical results demonstrate that Search Corrector reliably identifies errors in logical (ProntoQA) and mathematical reasoning (GSM8K) benchmarks. The Amortized Corrector achieves comparable zero-shot accuracy and improves final answer accuracy by up to 25%.