 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine-tuning with Synthetic Rationale Data Hurts Real-World Disease Prediction
Jun 09, 2026Supervised fine-tuning with synthetic rationale data is widely assumed to improve language model performance on clinical prediction tasks by teaching models not just what to predict but why. We test this assumption on five-year Alzheimer's disease and related dementias (ADRD) prediction from longitudinal health histories. Across a large-scale controlled experiment of 504 configurations, we find that rationale-based SFT consistently and substantially hurts prediction performance relative to label-only fine-tuning. The degradation persists across model families and data scales, and is not resolved by using a reasoning-oriented base model. Crucially, the failure is not explained by poor rationale quality: human expert annotation confirms that the generated rationales are medically accurate and faithfully grounded in patient-specific evidence, and few-shot experiments show that the same rationales improve performance when used as inference-time demonstrations rather than training targets. We identify the root cause as a structural conflict between narrative plausibility and discriminative optimization. We hope our work paves the path toward a more precise understanding of when and how rationale-based supervision helps and when it does not, guiding the responsible development of language models for high-stakes clinical prediction.
GUIDE: Goal-Initialized Directional Understanding for End-to-End Visual Navigation
Jun 09, 2026Learning-based visual navigation for legged robots typically relies on continuous goal updates from hierarchical state estimation to provide a persistent directional reference. This reliance incurs additional sensory and computational overhead and deviates from fully end-to-end mobile autonomy. Furthermore, under partial observability, policies are prone to learn myopic behaviors, easily becoming trapped in dead ends and complex structural layouts. To address these limitations, we investigate a goal-initialized navigation setting, where the target is provided only once at the beginning of an episode, requiring the robot to operate based on intrinsic spatial memory without subsequent goal updates from external modules. In this work, we propose GUIDE, a fully end-to-end reinforcement learning framework designed to cultivate internal directional awareness. Specifically, GUIDE incorporates a spatial anchor predictor that leverages multi-frequency proprioceptive history to extract egomotion representations, thereby maintaining a persistent long-horizon spatial context for navigation. Concurrently, it utilizes raw depth streams to perceive local environmental geometry. We evaluate the proposed framework across both simulation and real-world scenarios on a quadruped robot. Experiments show that GUIDE learns reliable egomotion and directional awareness, enabling a fully end-to-end deployed policy to safely navigate through dense clutter and structured mazes without subsequent goal guidance or prior maps.
Learning to Evolve: Multi-modal Interactive Fields for Robust Humanoid Navigation in Dynamic Environments
May 21, 2026Safe manipulation-oriented navigation for humanoid robots requires scene memory that remains reliable under locomotion-induced perceptual distortion, environmental changes, and interaction-level geometric safety constraints. Existing semantic mapping and scene-graph systems are difficult to deploy directly in this setting because they often assume stable camera trajectories, static environments, or coarse object geometry. We introduce the Multi-modal Interactive Field (MIF), a humanoid-oriented system that integrates confidence-aware semantic 3D Gaussian Splatting, discrepancy-triggered spatial memory updates, and task-driven geometric reconstruction within a closed-loop perception-adaptation pipeline. MIF couples three fields: an uncertainty-aware 3DGS Appearance Field that suppresses gait-induced blur, a Spatial Field that maintains topological memory, and a Geometry Field that supports Interaction Pose Safety (IPS) before manipulation. A discrepancy detection score is introduced to separate locomotion-induced false-positive changes from persistent changes and updates only locally inconsistent regions. On a Unitree-G1 humanoid in a real dynamic office, MIF improves relocation success in non-static environments from 12% to 94% compared with static scene-graph memory, while reducing semantic memory footprint by 91.4% through feature distillation for practical online operation. Project page and code: https://ziya-jiang.github.io/MIF-homepage/
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
Flow-CDNet: A Novel Network for Detecting Both Slow and Fast Changes in Bitemporal Images
Jul 03, 2025Change detection typically involves identifying regions with changes between bitemporal images taken at the same location. Besides significant changes, slow changes in bitemporal images are also important in real-life scenarios. For instance, weak changes often serve as precursors to major hazards in scenarios like slopes, dams, and tailings ponds. Therefore, designing a change detection network that simultaneously detects slow and fast changes presents a novel challenge. In this paper, to address this challenge, we propose a change detection network named Flow-CDNet, consisting of two branches: optical flow branch and binary change detection branch. The first branch utilizes a pyramid structure to extract displacement changes at multiple scales. The second one combines a ResNet-based network with the optical flow branch's output to generate fast change outputs. Subsequently, to supervise and evaluate this new change detection framework, a self-built change detection dataset Flow-Change, a loss function combining binary tversky loss and L2 norm loss, along with a new evaluation metric called FEPE are designed. Quantitative experiments conducted on Flow-Change dataset demonstrated that our approach outperforms the existing methods. Furthermore, ablation experiments verified that the two branches can promote each other to enhance the detection performance.
Crowdsourcing-Based Knowledge Graph Construction for Drug Side Effects Using Large Language Models with an Application on Semaglutide
Apr 08, 2025



Social media is a rich source of real-world data that captures valuable patient experience information for pharmacovigilance. However, mining data from unstructured and noisy social media content remains a challenging task. We present a systematic framework that leverages large language models (LLMs) to extract medication side effects from social media and organize them into a knowledge graph (KG). We apply this framework to semaglutide for weight loss using data from Reddit. Using the constructed knowledge graph, we perform comprehensive analyses to investigate reported side effects across different semaglutide brands over time. These findings are further validated through comparison with adverse events reported in the FAERS database, providing important patient-centered insights into semaglutide's side effects that complement its safety profile and current knowledge base of semaglutide for both healthcare professionals and patients. Our work demonstrates the feasibility of using LLMs to transform social media data into structured KGs for pharmacovigilance.
Patients Speak, AI Listens: LLM-based Analysis of Online Reviews Uncovers Key Drivers for Urgent Care Satisfaction
Mar 26, 2025Investigating the public experience of urgent care facilities is essential for promoting community healthcare development. Traditional survey methods often fall short due to limited scope, time, and spatial coverage. Crowdsourcing through online reviews or social media offers a valuable approach to gaining such insights. With recent advancements in large language models (LLMs), extracting nuanced perceptions from reviews has become feasible. This study collects Google Maps reviews across the DMV and Florida areas and conducts prompt engineering with the GPT model to analyze the aspect-based sentiment of urgent care. We first analyze the geospatial patterns of various aspects, including interpersonal factors, operational efficiency, technical quality, finances, and facilities. Next, we determine Census Block Group(CBG)-level characteristics underpinning differences in public perception, including population density, median income, GINI Index, rent-to-income ratio, household below poverty rate, no insurance rate, and unemployment rate. Our results show that interpersonal factors and operational efficiency emerge as the strongest determinants of patient satisfaction in urgent care, while technical quality, finances, and facilities show no significant independent effects when adjusted for in multivariate models. Among socioeconomic and demographic factors, only population density demonstrates a significant but modest association with patient ratings, while the remaining factors exhibit no significant correlations. Overall, this study highlights the potential of crowdsourcing to uncover the key factors that matter to residents and provide valuable insights for stakeholders to improve public satisfaction with urgent care.
Resilient Legged Local Navigation: Learning to Traverse with Compromised Perception End-to-End
Oct 05, 2023



Autonomous robots must navigate reliably in unknown environments even under compromised exteroceptive perception, or perception failures. Such failures often occur when harsh environments lead to degraded sensing, or when the perception algorithm misinterprets the scene due to limited generalization. In this paper, we model perception failures as invisible obstacles and pits, and train a reinforcement learning (RL) based local navigation policy to guide our legged robot. Unlike previous works relying on heuristics and anomaly detection to update navigational information, we train our navigation policy to reconstruct the environment information in the latent space from corrupted perception and react to perception failures end-to-end. To this end, we incorporate both proprioception and exteroception into our policy inputs, thereby enabling the policy to sense collisions on different body parts and pits, prompting corresponding reactions. We validate our approach in simulation and on the real quadruped robot ANYmal running in real-time (<10 ms CPU inference). In a quantitative comparison with existing heuristic-based locally reactive planners, our policy increases the success rate over 30% when facing perception failures. Project Page: https://bit.ly/45NBTuh.
Deep-learning-enabled Brain Hemodynamic Mapping Using Resting-state fMRI
Apr 25, 2022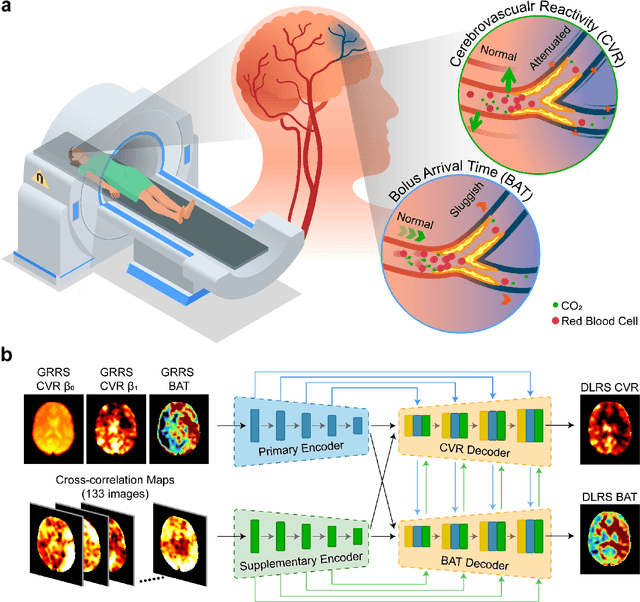
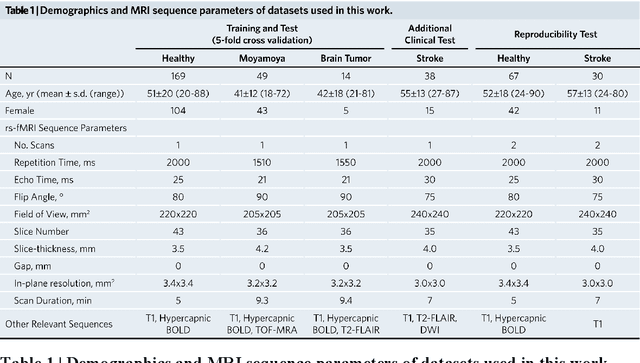
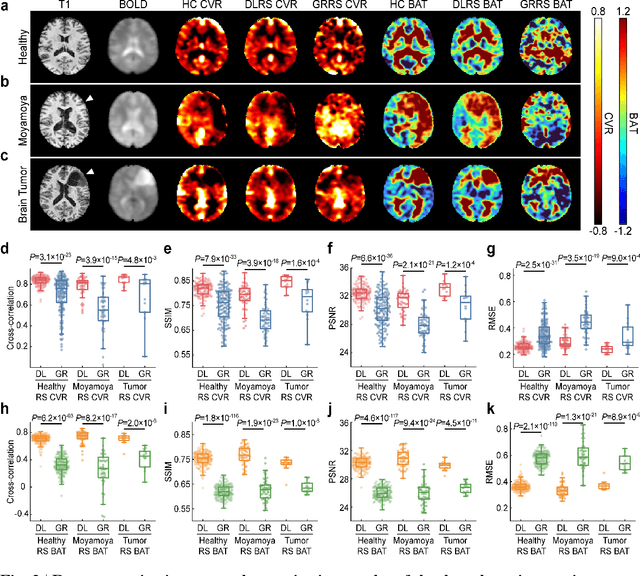
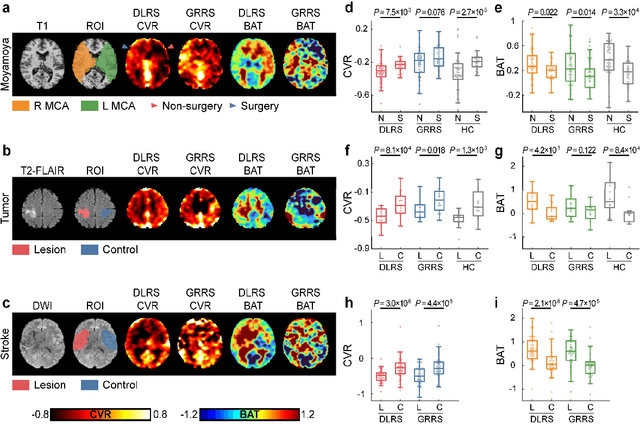
Cerebrovascular disease is a leading cause of death globally. Prevention and early intervention are known to be the most effective forms of its management. Non-invasive imaging methods hold great promises for early stratification, but at present lack the sensitivity for personalized prognosis. Resting-state functional magnetic resonance imaging (rs-fMRI), a powerful tool previously used for mapping neural activity, is available in most hospitals. Here we show that rs-fMRI can be used to map cerebral hemodynamic function and delineate impairment. By exploiting time variations in breathing pattern during rs-fMRI, deep learning enables reproducible mapping of cerebrovascular reactivity (CVR) and bolus arrive time (BAT) of the human brain using resting-state CO2 fluctuations as a natural 'contrast media'. The deep-learning network was trained with CVR and BAT maps obtained with a reference method of CO2-inhalation MRI, which included data from young and older healthy subjects and patients with Moyamoya disease and brain tumors. We demonstrate the performance of deep-learning cerebrovascular mapping in the detection of vascular abnormalities, evaluation of revascularization effects, and vascular alterations in normal aging. In addition, cerebrovascular maps obtained with the proposed method exhibited excellent reproducibility in both healthy volunteers and stroke patients. Deep-learning resting-state vascular imaging has the potential to become a useful tool in clinical cerebrovascular imaging.
NeXtQSM -- A complete deep learning pipeline for data-consistent quantitative susceptibility mapping trained with hybrid data
Jul 16, 2021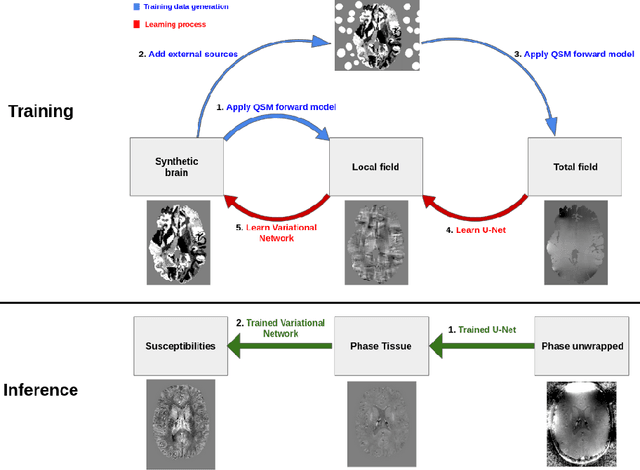
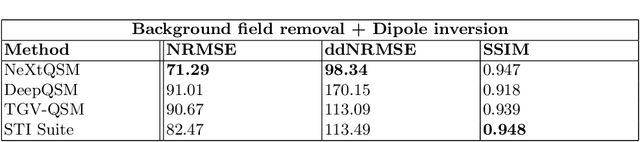
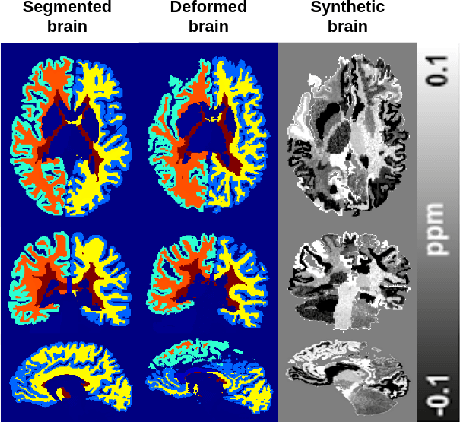
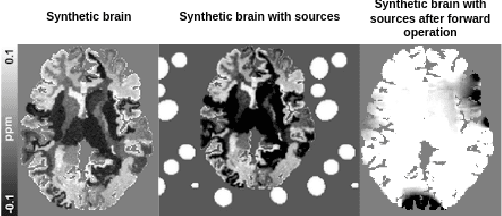
Deep learning based Quantitative Susceptibility Mapping (QSM) has shown great potential in recent years, outperforming traditional non-learning approaches in speed and accuracy. However, many of the current deep learning approaches are not data consistent, require in vivo training data or do not solve all steps of the QSM processing pipeline. Here we aim to overcome these limitations and developed a framework to solve the QSM processing steps jointly. We developed a new hybrid training data generation method that enables the end-to-end training for solving background field correction and dipole inversion in a data-consistent fashion using a variational network that combines the QSM model term and a learned regularizer. We demonstrate that NeXtQSM overcomes the limitations of previous model-agnostic deep learning methods and show that NeXtQSM offers a complete deep learning based pipeline for computing robust, fast and accurate quantitative susceptibility maps.