 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Policy Optimization with Self-Distillation
Jun 02, 2026Self-distilled policy optimization (SDPO) has become a popular paradigm for LLM post-training, where a model learns from its own predictions conditioned on privileged information. SDPO, however, is sensitive to how much each update step should be trusted: corrections from a self-teacher can be highly informative on some batches and misleading on others, and applying them uniformly with a fixed step size can destabilize training. Drawing inspiration from viscous-fluid dynamics and formalizing the analogy at the SDE level, we propose Physics-Guided Policy Optimization (PGPO), which introduces an information-modulated step-size multiplier derived from a mutual-information estimate between the student's predictions and the feedback-conditioned teacher. We show that this modulation preserves the order-1 weak-approximation guarantees of vanilla SGD, and incurs negligible overhead per iteration. We evaluate PGPO on the Science-QA dataset, where it outperforms SDPO on 3 of the 4 domains with gains of up to +4.5 points, while remaining stable in a setting where SDPO collapses late in training.
Hindsight-Anchored Policy Optimization: Turning Failure into Feedback in Sparse Reward Settings
Mar 11, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising paradigm for post-training reasoning models. However, group-based methods such as Group Relative Policy Optimization (GRPO) face a critical dilemma in sparse-reward settings: pure Reinforcement Learning (RL) suffers from advantage collapse and high-variance gradient estimation, while mixed-policy optimization introduces persistent distributional bias. To resolve this dilemma, we introduce Hindsight-Anchored Policy Optimization (HAPO). HAPO employs the Synthetic Success Injection (SSI) operator, a hindsight mechanism that selectively anchors optimization to teacher demonstrations during failure. This injection is governed by a Thompson sampling-inspired gating mechanism, creating an autonomous, self-paced curriculum. Theoretically, we demonstrate that HAPO achieves \textit{asymptotic consistency}: by naturally annealing the teacher signal as the policy improves, HAPO recovers the unbiased on-policy gradient. This ensures off-policy guidance acts as a temporary scaffold rather than a persistent ceiling, enabling the model to surpass the limitations of static teacher forcing.
Synthetic Data-Driven Prompt Tuning for Financial QA over Tables and Documents
Nov 14, 2025Financial documents like earning reports or balance sheets often involve long tables and multi-page reports. Large language models have become a new tool to help numerical reasoning and understanding these documents. However, prompt quality can have a major effect on how well LLMs perform these financial reasoning tasks. Most current methods tune prompts on fixed datasets of financial text or tabular data, which limits their ability to adapt to new question types or document structures, or they involve costly and manually labeled/curated dataset to help build the prompts. We introduce a self-improving prompt framework driven by data-augmented optimization. In this closed-loop process, we generate synthetic financial tables and document excerpts, verify their correctness and robustness, and then update the prompt based on the results. Specifically, our framework combines a synthetic data generator with verifiers and a prompt optimizer, where the generator produces new examples that exposes weaknesses in the current prompt, the verifiers check the validity and robustness of the produced examples, and the optimizer incrementally refines the prompt in response. By iterating these steps in a feedback cycle, our method steadily improves prompt accuracy on financial reasoning tasks without needing external labels. Evaluation on DocMath-Eval benchmark demonstrates that our system achieves higher performance in both accuracy and robustness than standard prompt methods, underscoring the value of incorporating synthetic data generation into prompt learning for financial applications.
SIPDO: Closed-Loop Prompt Optimization via Synthetic Data Feedback
May 26, 2025



Prompt quality plays a critical role in the performance of large language models (LLMs), motivating a growing body of work on prompt optimization. Most existing methods optimize prompts over a fixed dataset, assuming static input distributions and offering limited support for iterative improvement. We introduce SIPDO (Self-Improving Prompts through Data-Augmented Optimization), a closed-loop framework for prompt learning that integrates synthetic data generation into the optimization process. SIPDO couples a synthetic data generator with a prompt optimizer, where the generator produces new examples that reveal current prompt weaknesses and the optimizer incrementally refines the prompt in response. This feedback-driven loop enables systematic improvement of prompt performance without assuming access to external supervision or new tasks. Experiments across question answering and reasoning benchmarks show that SIPDO outperforms standard prompt tuning methods, highlighting the value of integrating data synthesis into prompt learning workflows.
Crowdsourcing-Based Knowledge Graph Construction for Drug Side Effects Using Large Language Models with an Application on Semaglutide
Apr 08, 2025



Social media is a rich source of real-world data that captures valuable patient experience information for pharmacovigilance. However, mining data from unstructured and noisy social media content remains a challenging task. We present a systematic framework that leverages large language models (LLMs) to extract medication side effects from social media and organize them into a knowledge graph (KG). We apply this framework to semaglutide for weight loss using data from Reddit. Using the constructed knowledge graph, we perform comprehensive analyses to investigate reported side effects across different semaglutide brands over time. These findings are further validated through comparison with adverse events reported in the FAERS database, providing important patient-centered insights into semaglutide's side effects that complement its safety profile and current knowledge base of semaglutide for both healthcare professionals and patients. Our work demonstrates the feasibility of using LLMs to transform social media data into structured KGs for pharmacovigilance.
Towards Single-Lens Controllable Depth-of-Field Imaging via All-in-Focus Aberration Correction and Monocular Depth Estimation
Sep 15, 2024



Controllable Depth-of-Field (DoF) imaging commonly produces amazing visual effects based on heavy and expensive high-end lenses. However, confronted with the increasing demand for mobile scenarios, it is desirable to achieve a lightweight solution with Minimalist Optical Systems (MOS). This work centers around two major limitations of MOS, i.e., the severe optical aberrations and uncontrollable DoF, for achieving single-lens controllable DoF imaging via computational methods. A Depth-aware Controllable DoF Imaging (DCDI) framework is proposed equipped with All-in-Focus (AiF) aberration correction and monocular depth estimation, where the recovered image and corresponding depth map are utilized to produce imaging results under diverse DoFs of any high-end lens via patch-wise convolution. To address the depth-varying optical degradation, we introduce a Depth-aware Degradation-adaptive Training (DA2T) scheme. At the dataset level, a Depth-aware Aberration MOS (DAMOS) dataset is established based on the simulation of Point Spread Functions (PSFs) under different object distances. Additionally, we design two plug-and-play depth-aware mechanisms to embed depth information into the aberration image recovery for better tackling depth-aware degradation. Furthermore, we propose a storage-efficient Omni-Lens-Field model to represent the 4D PSF library of various lenses. With the predicted depth map, recovered image, and depth-aware PSF map inferred by Omni-Lens-Field, single-lens controllable DoF imaging is achieved. Comprehensive experimental results demonstrate that the proposed framework enhances the recovery performance, and attains impressive single-lens controllable DoF imaging results, providing a seminal baseline for this field. The source code and the established dataset will be publicly available at https://github.com/XiaolongQian/DCDI.
End-to-end spoken language understanding using joint CTC loss and self-supervised, pretrained acoustic encoders
May 04, 2023



It is challenging to extract semantic meanings directly from audio signals in spoken language understanding (SLU), due to the lack of textual information. Popular end-to-end (E2E) SLU models utilize sequence-to-sequence automatic speech recognition (ASR) models to extract textual embeddings as input to infer semantics, which, however, require computationally expensive auto-regressive decoding. In this work, we leverage self-supervised acoustic encoders fine-tuned with Connectionist Temporal Classification (CTC) to extract textual embeddings and use joint CTC and SLU losses for utterance-level SLU tasks. Experiments show that our model achieves 4% absolute improvement over the the state-of-the-art (SOTA) dialogue act classification model on the DSTC2 dataset and 1.3% absolute improvement over the SOTA SLU model on the SLURP dataset.
Dialog act guided contextual adapter for personalized speech recognition
Mar 31, 2023



Personalization in multi-turn dialogs has been a long standing challenge for end-to-end automatic speech recognition (E2E ASR) models. Recent work on contextual adapters has tackled rare word recognition using user catalogs. This adaptation, however, does not incorporate an important cue, the dialog act, which is available in a multi-turn dialog scenario. In this work, we propose a dialog act guided contextual adapter network. Specifically, it leverages dialog acts to select the most relevant user catalogs and creates queries based on both -- the audio as well as the semantic relationship between the carrier phrase and user catalogs to better guide the contextual biasing. On industrial voice assistant datasets, our model outperforms both the baselines - dialog act encoder-only model, and the contextual adaptation, leading to the most improvement over the no-context model: 58% average relative word error rate reduction (WERR) in the multi-turn dialog scenario, in comparison to the prior-art contextual adapter, which has achieved 39% WERR over the no-context model.
A neural prosody encoder for end-ro-end dialogue act classification
May 11, 2022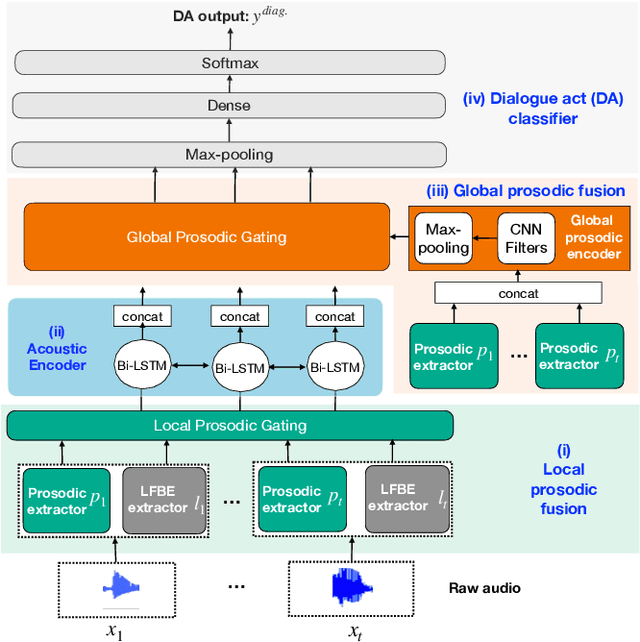
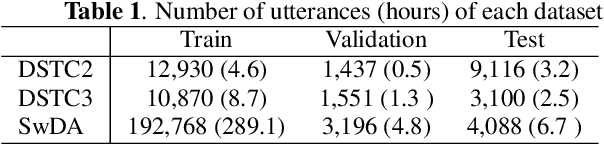
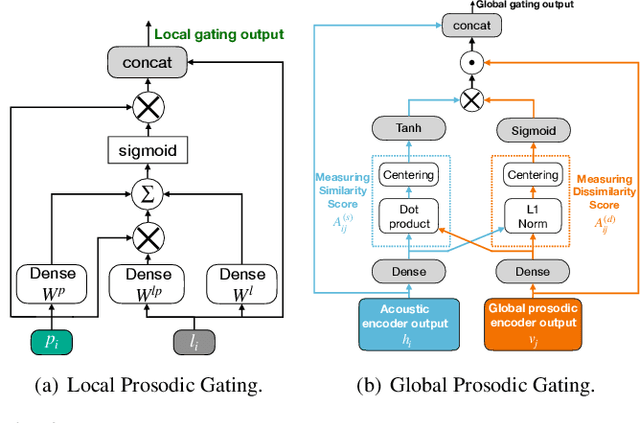

Dialogue act classification (DAC) is a critical task for spoken language understanding in dialogue systems. Prosodic features such as energy and pitch have been shown to be useful for DAC. Despite their importance, little research has explored neural approaches to integrate prosodic features into end-to-end (E2E) DAC models which infer dialogue acts directly from audio signals. In this work, we propose an E2E neural architecture that takes into account the need for characterizing prosodic phenomena co-occurring at different levels inside an utterance. A novel part of this architecture is a learnable gating mechanism that assesses the importance of prosodic features and selectively retains core information necessary for E2E DAC. Our proposed model improves DAC accuracy by 1.07% absolute across three publicly available benchmark datasets.
Distributed Neural Precoding for Hybrid mmWave MIMO Communications with Limited Feedback
Apr 18, 2022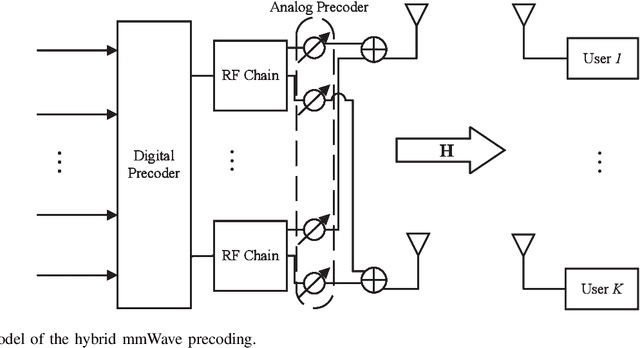
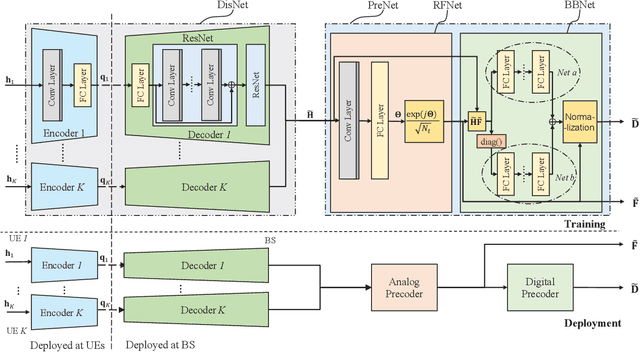
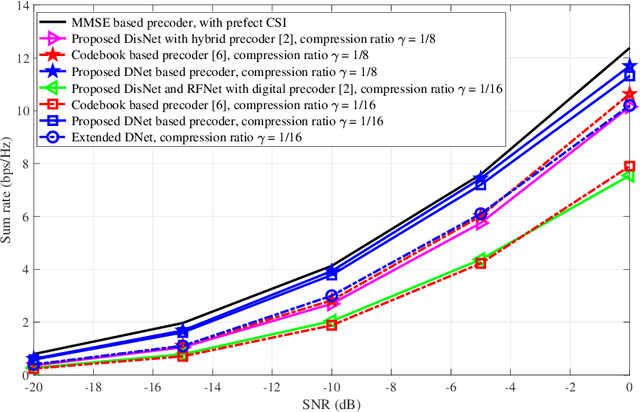
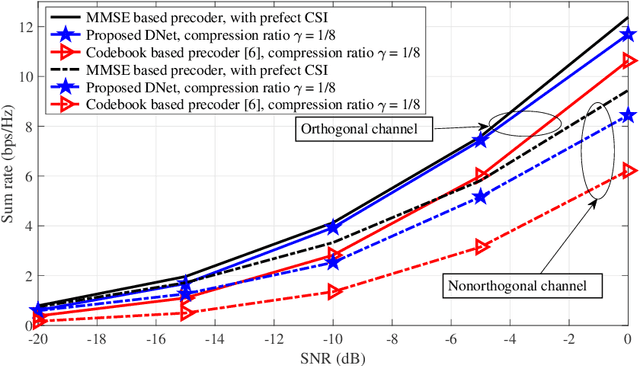
Hybrid precoding is a cost-efficient technique for millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) communications. This paper proposes a deep learning approach by using a distributed neural network for hybrid analog-and-digital precoding design with limited feedback. The proposed distributed neural precoding network, called DNet, is committed to achieving two objectives. First, the DNet realizes channel state information (CSI) compression with a distributed architecture of neural networks, which enables practical deployment on multiple users. Specifically, this neural network is composed of multiple independent sub-networks with the same structure and parameters, which reduces both the number of training parameters and network complexity. Secondly, DNet learns the calculation of hybrid precoding from reconstructed CSI from limited feedback. Different from existing black-box neural network design, the DNet is specifically designed according to the data form of the matrix calculation of hybrid precoding. Simulation results show that the proposed DNet significantly improves the performance up to nearly 50% compared to traditional limited feedback precoding methods under the tests with various CSI compression ratios.