 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reasoning with Knowledge Graph for Social Relationship Understanding
Jul 02, 2018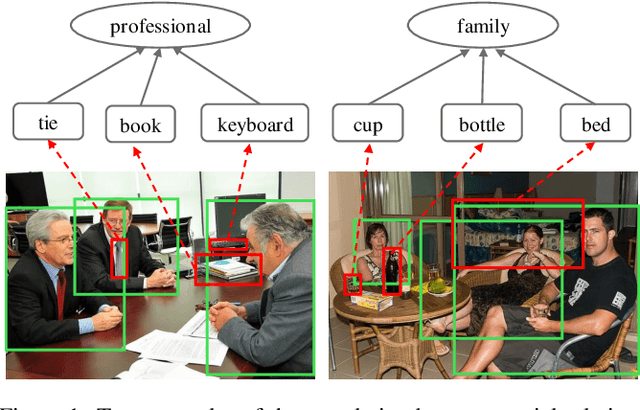
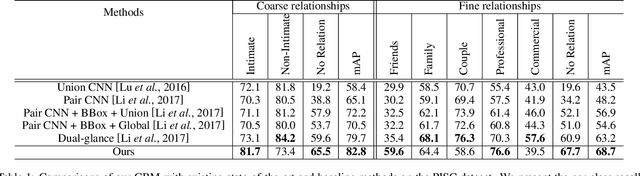
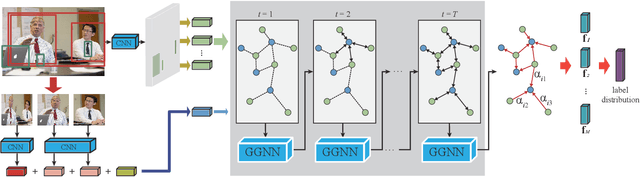

Social relationships (e.g., friends, couple etc.) form the basis of the social network in our daily life. Automatically interpreting such relationships bears a great potential for the intelligent systems to understand human behavior in depth and to better interact with people at a social level. Human beings interpret the social relationships within a group not only based on the people alone, and the interplay between such social relationships and the contextual information around the people also plays a significant role. However, these additional cues are largely overlooked by the previous studies. We found that the interplay between these two factors can be effectively modeled by a novel structured knowledge graph with proper message propagation and attention. And this structured knowledge can be efficiently integrated into the deep neural network architecture to promote social relationship understanding by an end-to-end trainable Graph Reasoning Model (GRM), in which a propagation mechanism is learned to propagate node message through the graph to explore the interaction between persons of interest and the contextual objects. Meanwhile, a graph attentional mechanism is introduced to explicitly reason about the discriminative objects to promote recognition. Extensive experiments on the public benchmarks demonstrate the superiority of our method over the existing leading competitors.
Learning Selfie-Friendly Abstraction from Artistic Style Images
May 21, 2018

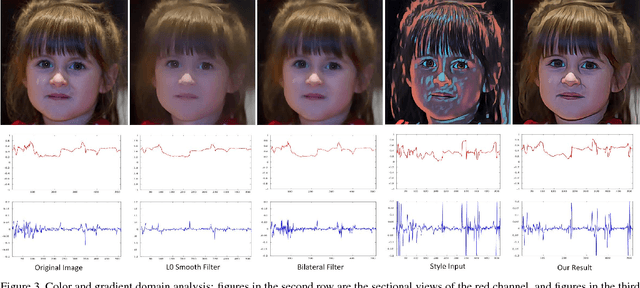
Artistic style transfer can be thought as a process to generate different versions of abstraction of the original image. However, most of the artistic style transfer operators are not optimized for human faces thus mainly suffers from two undesirable features when applying them to selfies. First, the edges of human faces may unpleasantly deviate from the ones in the original image. Second, the skin color is far from faithful to the original one which is usually problematic in producing quality selfies. In this paper, we take a different approach and formulate this abstraction process as a gradient domain learning problem. We aim to learn a type of abstraction which not only achieves the specified artistic style but also circumvents the two aforementioned drawbacks thus highly applicable to selfie photography. We also show that our method can be directly generalized to videos with high inter-frame consistency. Our method is also robust to non-selfie images, and the generalization to various kinds of real-life scenes is discussed. We will make our code publicly available.
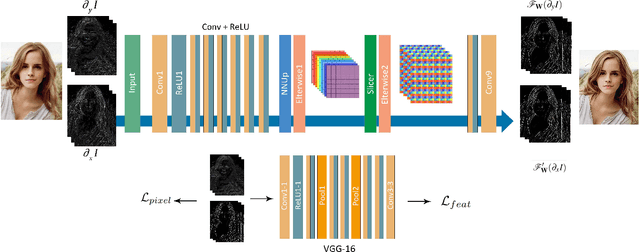
Learning Dual Convolutional Neural Networks for Low-Level Vision
May 14, 2018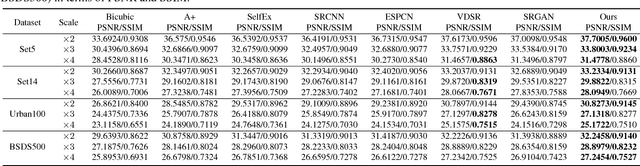
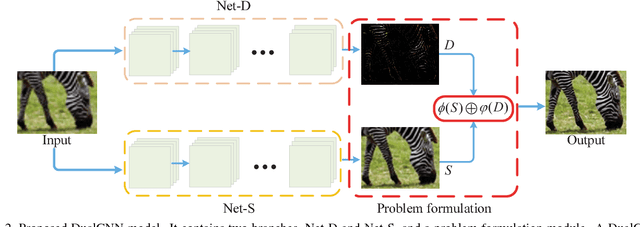
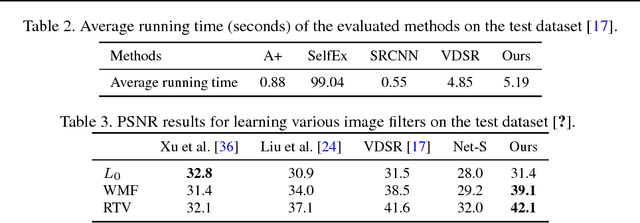

In this paper, we propose a general dual convolutional neural network (DualCNN) for low-level vision problems, e.g., super-resolution, edge-preserving filtering, deraining and dehazing. These problems usually involve the estimation of two components of the target signals: structures and details. Motivated by this, our proposed DualCNN consists of two parallel branches, which respectively recovers the structures and details in an end-to-end manner. The recovered structures and details can generate the target signals according to the formation model for each particular application. The DualCNN is a flexible framework for low-level vision tasks and can be easily incorporated into existing CNNs. Experimental results show that the DualCNN can be effectively applied to numerous low-level vision tasks with favorable performance against the state-of-the-art methods.
3D Human Pose Estimation in the Wild by Adversarial Learning
Apr 16, 2018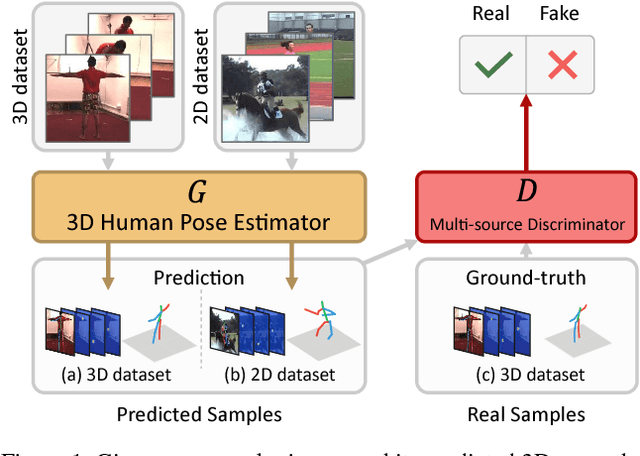
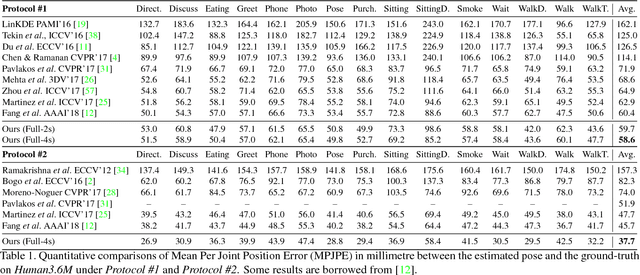
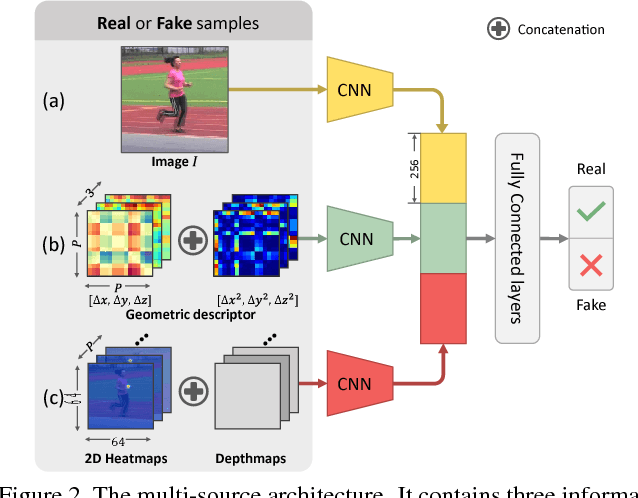
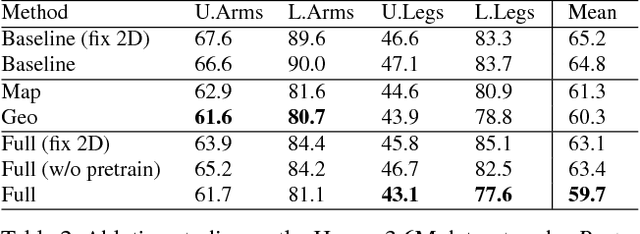
Recently, remarkable advances have been achieved in 3D human pose estimation from monocular images because of the powerful Deep Convolutional Neural Networks (DCNNs). Despite their success on large-scale datasets collected in the constrained lab environment, it is difficult to obtain the 3D pose annotations for in-the-wild images. Therefore, 3D human pose estimation in the wild is still a challenge. In this paper, we propose an adversarial learning framework, which distills the 3D human pose structures learned from the fully annotated dataset to in-the-wild images with only 2D pose annotations. Instead of defining hard-coded rules to constrain the pose estimation results, we design a novel multi-source discriminator to distinguish the predicted 3D poses from the ground-truth, which helps to enforce the pose estimator to generate anthropometrically valid poses even with images in the wild. We also observe that a carefully designed information source for the discriminator is essential to boost the performance. Thus, we design a geometric descriptor, which computes the pairwise relative locations and distances between body joints, as a new information source for the discriminator. The efficacy of our adversarial learning framework with the new geometric descriptor has been demonstrated through extensive experiments on widely used public benchmarks. Our approach significantly improves the performance compared with previous state-of-the-art approaches.
Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
Mar 18, 2018
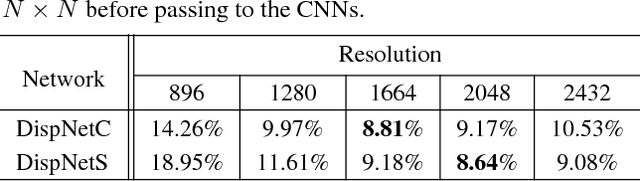

Despite the recent success of stereo matching with convolutional neural networks (CNNs), it remains arduous to generalize a pre-trained deep stereo model to a novel domain. A major difficulty is to collect accurate ground-truth disparities for stereo pairs in the target domain. In this work, we propose a self-adaptation approach for CNN training, utilizing both synthetic training data (with ground-truth disparities) and stereo pairs in the new domain (without ground-truths). Our method is driven by two empirical observations. By feeding real stereo pairs of different domains to stereo models pre-trained with synthetic data, we see that: i) a pre-trained model does not generalize well to the new domain, producing artifacts at boundaries and ill-posed regions; however, ii) feeding an up-sampled stereo pair leads to a disparity map with extra details. To avoid i) while exploiting ii), we formulate an iterative optimization problem with graph Laplacian regularization. At each iteration, the CNN adapts itself better to the new domain: we let the CNN learn its own higher-resolution output; at the meanwhile, a graph Laplacian regularization is imposed to discriminatively keep the desired edges while smoothing out the artifacts. We demonstrate the effectiveness of our method in two domains: daily scenes collected by smartphone cameras, and street views captured in a driving car.
Single View Stereo Matching
Mar 09, 2018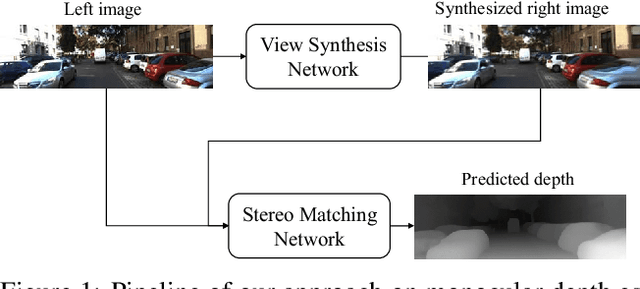
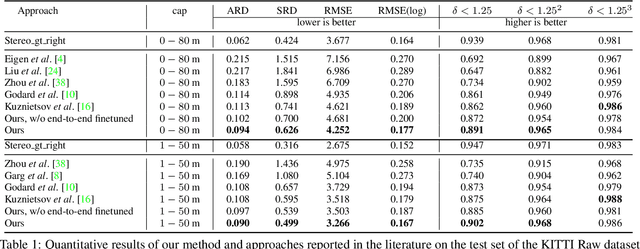
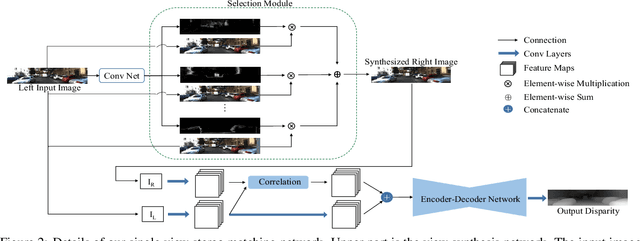
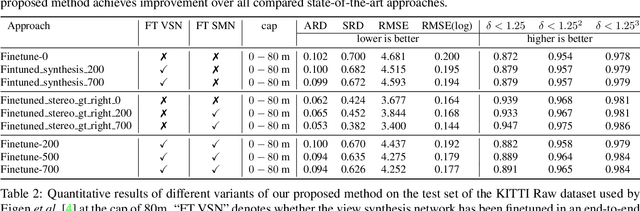
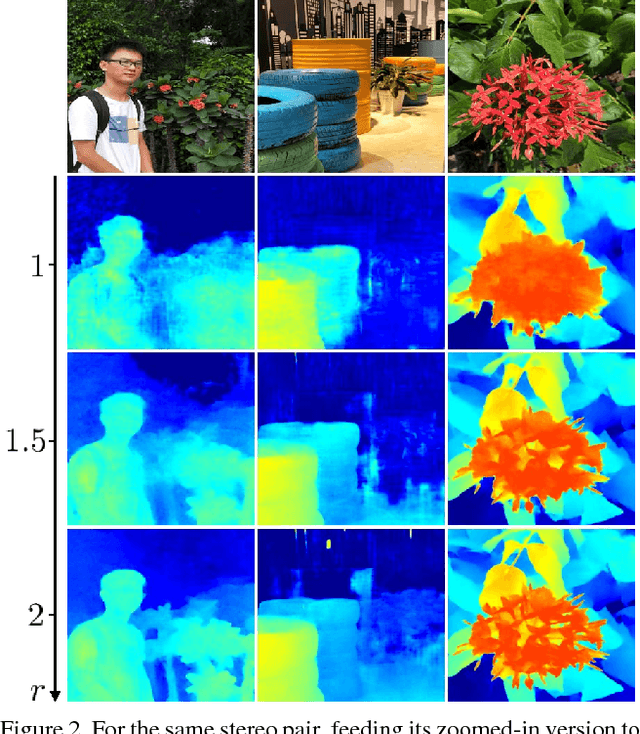
Previous monocular depth estimation methods take a single view and directly regress the expected results. Though recent advances are made by applying geometrically inspired loss functions during training, the inference procedure does not explicitly impose any geometrical constraint. Therefore these models purely rely on the quality of data and the effectiveness of learning to generalize. This either leads to suboptimal results or the demand of huge amount of expensive ground truth labelled data to generate reasonable results. In this paper, we show for the first time that the monocular depth estimation problem can be reformulated as two sub-problems, a view synthesis procedure followed by stereo matching, with two intriguing properties, namely i) geometrical constraints can be explicitly imposed during inference; ii) demand on labelled depth data can be greatly alleviated. We show that the whole pipeline can still be trained in an end-to-end fashion and this new formulation plays a critical role in advancing the performance. The resulting model outperforms all the previous monocular depth estimation methods as well as the stereo block matching method in the challenging KITTI dataset by only using a small number of real training data. The model also generalizes well to other monocular depth estimation benchmarks. We also discuss the implications and the advantages of solving monocular depth estimation using stereo methods.
LSTM Pose Machines
Mar 09, 2018
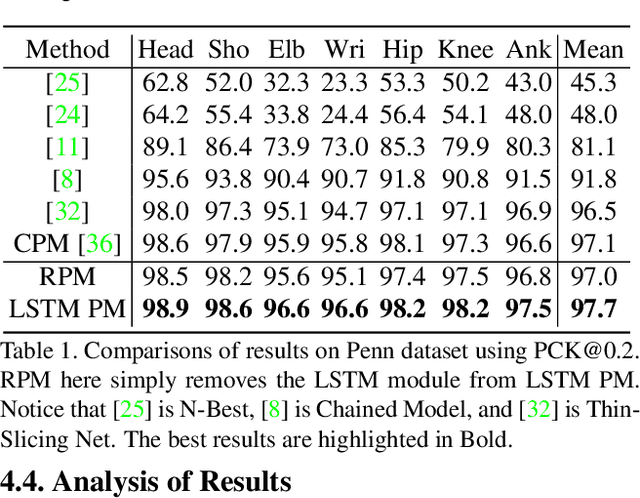
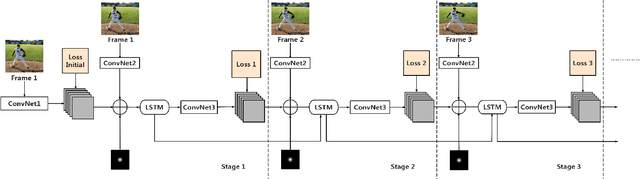
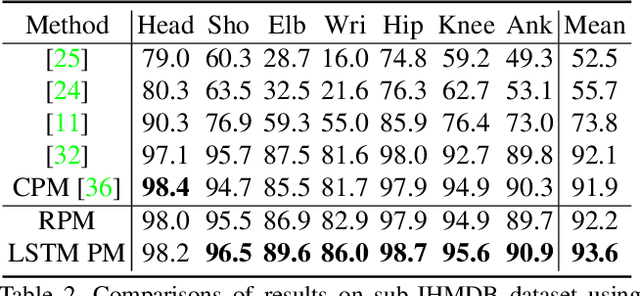
We observed that recent state-of-the-art results on single image human pose estimation were achieved by multi-stage Convolution Neural Networks (CNN). Notwithstanding the superior performance on static images, the application of these models on videos is not only computationally intensive, it also suffers from performance degeneration and flicking. Such suboptimal results are mainly attributed to the inability of imposing sequential geometric consistency, handling severe image quality degradation (e.g. motion blur and occlusion) as well as the inability of capturing the temporal correlation among video frames. In this paper, we proposed a novel recurrent network to tackle these problems. We showed that if we were to impose the weight sharing scheme to the multi-stage CNN, it could be re-written as a Recurrent Neural Network (RNN). This property decouples the relationship among multiple network stages and results in significantly faster speed in invoking the network for videos. It also enables the adoption of Long Short-Term Memory (LSTM) units between video frames. We found such memory augmented RNN is very effective in imposing geometric consistency among frames. It also well handles input quality degradation in videos while successfully stabilizes the sequential outputs. The experiments showed that our approach significantly outperformed current state-of-the-art methods on two large-scale video pose estimation benchmarks. We also explored the memory cells inside the LSTM and provided insights on why such mechanism would benefit the prediction for video-based pose estimations.
Image Dehazing using Bilinear Composition Loss Function
Oct 01, 2017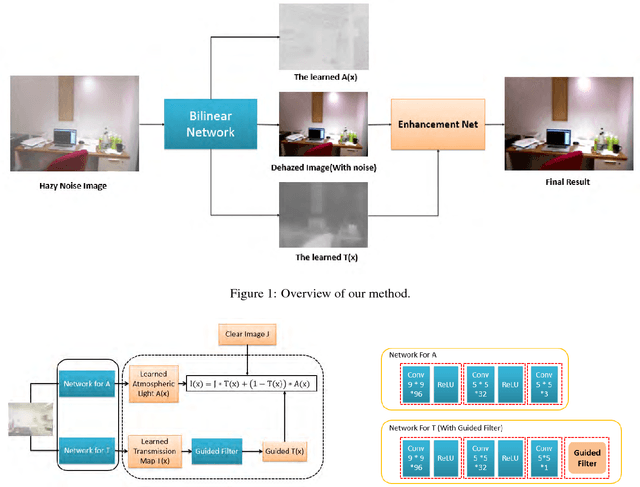



In this paper, we introduce a bilinear composition loss function to address the problem of image dehazing. Previous methods in image dehazing use a two-stage approach which first estimate the transmission map followed by clear image estimation. The drawback of a two-stage method is that it tends to boost local image artifacts such as noise, aliasing and blocking. This is especially the case for heavy haze images captured with a low quality device. Our method is based on convolutional neural networks. Unique in our method is the bilinear composition loss function which directly model the correlations between transmission map, clear image, and atmospheric light. This allows errors to be back-propagated to each sub-network concurrently, while maintaining the composition constraint to avoid overfitting of each sub-network. We evaluate the effectiveness of our proposed method using both synthetic and real world examples. Extensive experiments show that our method outperfoms state-of-the-art methods especially for haze images with severe noise level and compressions.
Robust Tracking Using Region Proposal Networks
May 30, 2017

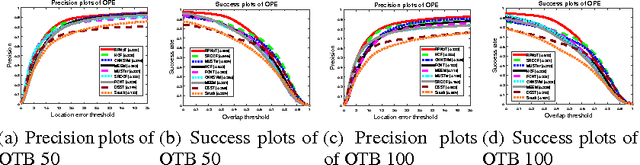
Recent advances in visual tracking showed that deep Convolutional Neural Networks (CNN) trained for image classification can be strong feature extractors for discriminative trackers. However, due to the drastic difference between image classification and tracking, extra treatments such as model ensemble and feature engineering must be carried out to bridge the two domains. Such procedures are either time consuming or hard to generalize well across datasets. In this paper we discovered that the internal structure of Region Proposal Network (RPN)'s top layer feature can be utilized for robust visual tracking. We showed that such property has to be unleashed by a novel loss function which simultaneously considers classification accuracy and bounding box quality. Without ensemble and any extra treatment on feature maps, our proposed method achieved state-of-the-art results on several large scale benchmarks including OTB50, OTB100 and VOT2016. We will make our code publicly available.
Accurate Single Stage Detector Using Recurrent Rolling Convolution
Apr 19, 2017
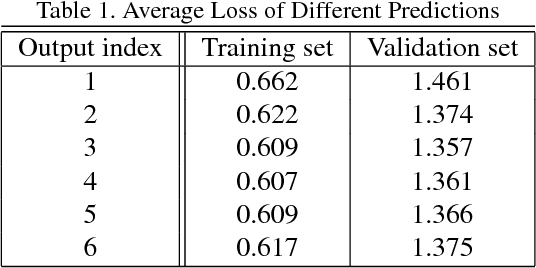
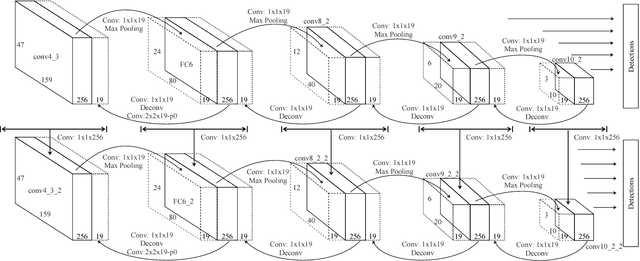
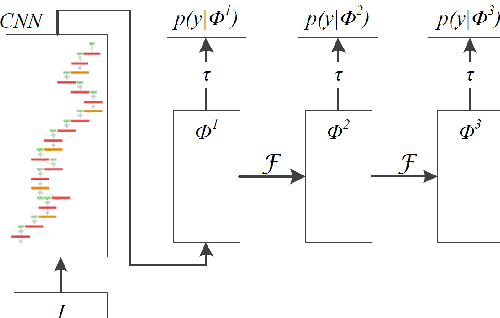
Most of the recent successful methods in accurate object detection and localization used some variants of R-CNN style two stage Convolutional Neural Networks (CNN) where plausible regions were proposed in the first stage then followed by a second stage for decision refinement. Despite the simplicity of training and the efficiency in deployment, the single stage detection methods have not been as competitive when evaluated in benchmarks consider mAP for high IoU thresholds. In this paper, we proposed a novel single stage end-to-end trainable object detection network to overcome this limitation. We achieved this by introducing Recurrent Rolling Convolution (RRC) architecture over multi-scale feature maps to construct object classifiers and bounding box regressors which are "deep in context". We evaluated our method in the challenging KITTI dataset which measures methods under IoU threshold of 0.7. We showed that with RRC, a single reduced VGG-16 based model already significantly outperformed all the previously published results. At the time this paper was written our models ranked the first in KITTI car detection (the hard level), the first in cyclist detection and the second in pedestrian detection. These results were not reached by the previous single stage methods. The code is publicly available.