 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
Jun 09, 2026Built on pretrained vision foundation models (VFMs), representation autoencoders (RAEs) have recently emerged as a promising approach for constructing semantically rich latent spaces for image generation. However, their reconstruction quality often remains suboptimal, largely because deep VFM representations do not preserve sufficient fine-grained visual detail. This limitation becomes even more severe after discretization, where missing low-level information is difficult to recover. In fact, we observe that shallow VFM features retain considerably richer local appearance and structural detail, which complements the high-level semantics carried by deep features used in existing RAEs. Motivated by this complementary property, we propose Ideal, an In-depth Alignment framework for discrete representation autoencoding. By jointly aligning quantized tokens with both shallow and deep VFM features, Ideal enables the resulting discrete visual tokens to preserve both visual fidelity and rich semantics. Extensive experiments demonstrate that Ideal yields superior reconstruction performance, achieving 0.61 rFID on ImageNet and outperforming the previous best method by 0.28. When used for autoregressive image generation, Ideal further produces a gFID of 1.89, establishing a new state of the art for autoregressive image generation.
All-in-One Conditioning for Text-to-Image Synthesis
Feb 09, 2026Accurate interpretation and visual representation of complex prompts involving multiple objects, attributes, and spatial relationships is a critical challenge in text-to-image synthesis. Despite recent advancements in generating photorealistic outputs, current models often struggle with maintaining semantic fidelity and structural coherence when processing intricate textual inputs. We propose a novel approach that grounds text-to-image synthesis within the framework of scene graph structures, aiming to enhance the compositional abilities of existing models. Eventhough, prior approaches have attempted to address this by using pre-defined layout maps derived from prompts, such rigid constraints often limit compositional flexibility and diversity. In contrast, we introduce a zero-shot, scene graph-based conditioning mechanism that generates soft visual guidance during inference. At the core of our method is the Attribute-Size-Quantity-Location (ASQL) Conditioner, which produces visual conditions via a lightweight language model and guides diffusion-based generation through inference-time optimization. This enables the model to maintain text-image alignment while supporting lightweight, coherent, and diverse image synthesis.
Characterizing Motion Encoding in Video Diffusion Timesteps
Dec 18, 2025Text-to-video diffusion models synthesize temporal motion and spatial appearance through iterative denoising, yet how motion is encoded across timesteps remains poorly understood. Practitioners often exploit the empirical heuristic that early timesteps mainly shape motion and layout while later ones refine appearance, but this behavior has not been systematically characterized. In this work, we proxy motion encoding in video diffusion timesteps by the trade-off between appearance editing and motion preservation induced when injecting new conditions over specified timestep ranges, and characterize this proxy through a large-scale quantitative study. This protocol allows us to factor motion from appearance by quantitatively mapping how they compete along the denoising trajectory. Across diverse architectures, we consistently identify an early, motion-dominant regime and a later, appearance-dominant regime, yielding an operational motion-appearance boundary in timestep space. Building on this characterization, we simplify current one-shot motion customization paradigm by restricting training and inference to the motion-dominant regime, achieving strong motion transfer without auxiliary debiasing modules or specialized objectives. Our analysis turns a widely used heuristic into a spatiotemporal disentanglement principle, and our timestep-constrained recipe can serve as ready integration into existing motion transfer and editing methods.
LARP: Tokenizing Videos with a Learned Autoregressive Generative Prior
Oct 28, 2024We present LARP, a novel video tokenizer designed to overcome limitations in current video tokenization methods for autoregressive (AR) generative models. Unlike traditional patchwise tokenizers that directly encode local visual patches into discrete tokens, LARP introduces a holistic tokenization scheme that gathers information from the visual content using a set of learned holistic queries. This design allows LARP to capture more global and semantic representations, rather than being limited to local patch-level information. Furthermore, it offers flexibility by supporting an arbitrary number of discrete tokens, enabling adaptive and efficient tokenization based on the specific requirements of the task. To align the discrete token space with downstream AR generation tasks, LARP integrates a lightweight AR transformer as a training-time prior model that predicts the next token on its discrete latent space. By incorporating the prior model during training, LARP learns a latent space that is not only optimized for video reconstruction but is also structured in a way that is more conducive to autoregressive generation. Moreover, this process defines a sequential order for the discrete tokens, progressively pushing them toward an optimal configuration during training, ensuring smoother and more accurate AR generation at inference time. Comprehensive experiments demonstrate LARP's strong performance, achieving state-of-the-art FVD on the UCF101 class-conditional video generation benchmark. LARP enhances the compatibility of AR models with videos and opens up the potential to build unified high-fidelity multimodal large language models (MLLMs).
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Feb 22, 2024



Image customization has been extensively studied in text-to-image (T2I) diffusion models, leading to impressive outcomes and applications. With the emergence of text-to-video (T2V) diffusion models, its temporal counterpart, motion customization, has not yet been well investigated. To address the challenge of one-shot motion customization, we propose Customize-A-Video that models the motion from a single reference video and adapting it to new subjects and scenes with both spatial and temporal varieties. It leverages low-rank adaptation (LoRA) on temporal attention layers to tailor the pre-trained T2V diffusion model for specific motion modeling from the reference videos. To disentangle the spatial and temporal information during the training pipeline, we introduce a novel concept of appearance absorbers that detach the original appearance from the single reference video prior to motion learning. Our proposed method can be easily extended to various downstream tasks, including custom video generation and editing, video appearance customization, and multiple motion combination, in a plug-and-play fashion. Our project page can be found at https://anonymous-314.github.io.
Towards Scalable Neural Representation for Diverse Videos
Mar 24, 2023



Implicit neural representations (INR) have gained increasing attention in representing 3D scenes and images, and have been recently applied to encode videos (e.g., NeRV, E-NeRV). While achieving promising results, existing INR-based methods are limited to encoding a handful of short videos (e.g., seven 5-second videos in the UVG dataset) with redundant visual content, leading to a model design that fits individual video frames independently and is not efficiently scalable to a large number of diverse videos. This paper focuses on developing neural representations for a more practical setup -- encoding long and/or a large number of videos with diverse visual content. We first show that instead of dividing videos into small subsets and encoding them with separate models, encoding long and diverse videos jointly with a unified model achieves better compression results. Based on this observation, we propose D-NeRV, a novel neural representation framework designed to encode diverse videos by (i) decoupling clip-specific visual content from motion information, (ii) introducing temporal reasoning into the implicit neural network, and (iii) employing the task-oriented flow as intermediate output to reduce spatial redundancies. Our new model largely surpasses NeRV and traditional video compression techniques on UCF101 and UVG datasets on the video compression task. Moreover, when used as an efficient data-loader, D-NeRV achieves 3%-10% higher accuracy than NeRV on action recognition tasks on the UCF101 dataset under the same compression ratios.
NeRV: Neural Representations for Videos
Oct 26, 2021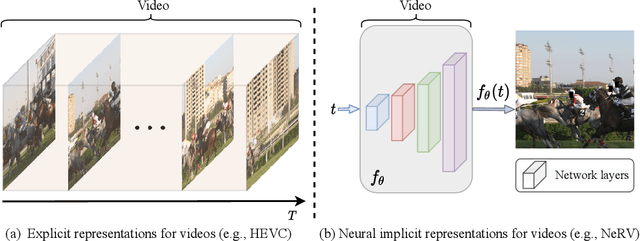

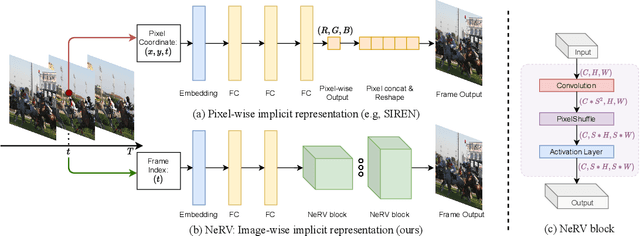

We propose a novel neural representation for videos (NeRV) which encodes videos in neural networks. Unlike conventional representations that treat videos as frame sequences, we represent videos as neural networks taking frame index as input. Given a frame index, NeRV outputs the corresponding RGB image. Video encoding in NeRV is simply fitting a neural network to video frames and decoding process is a simple feedforward operation. As an image-wise implicit representation, NeRV output the whole image and shows great efficiency compared to pixel-wise implicit representation, improving the encoding speed by 25x to 70x, the decoding speed by 38x to 132x, while achieving better video quality. With such a representation, we can treat videos as neural networks, simplifying several video-related tasks. For example, conventional video compression methods are restricted by a long and complex pipeline, specifically designed for the task. In contrast, with NeRV, we can use any neural network compression method as a proxy for video compression, and achieve comparable performance to traditional frame-based video compression approaches (H.264, HEVC \etc). Besides compression, we demonstrate the generalization of NeRV for video denoising. The source code and pre-trained model can be found at https://github.com/haochen-rye/NeRV.git.
StEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis
Apr 14, 2021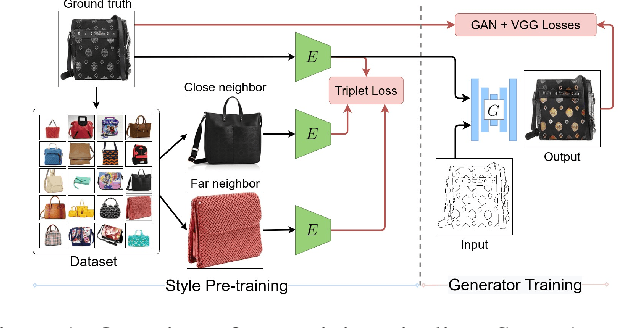
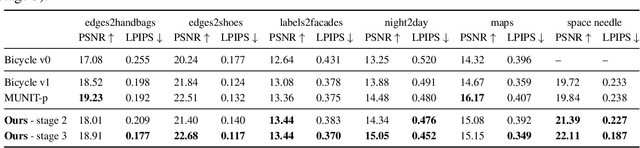

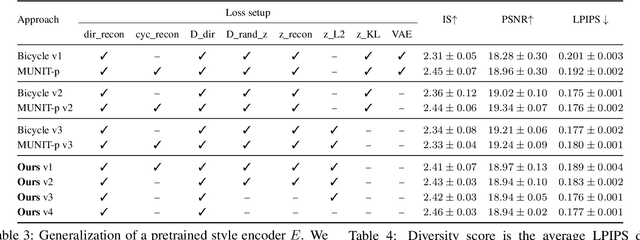
We propose a novel approach for multi-modal Image-to-image (I2I) translation. To tackle the one-to-many relationship between input and output domains, previous works use complex training objectives to learn a latent embedding, jointly with the generator, that models the variability of the output domain. In contrast, we directly model the style variability of images, independent of the image synthesis task. Specifically, we pre-train a generic style encoder using a novel proxy task to learn an embedding of images, from arbitrary domains, into a low-dimensional style latent space. The learned latent space introduces several advantages over previous traditional approaches to multi-modal I2I translation. First, it is not dependent on the target dataset, and generalizes well across multiple domains. Second, it learns a more powerful and expressive latent space, which improves the fidelity of style capture and transfer. The proposed style pre-training also simplifies the training objective and speeds up the training significantly. Furthermore, we provide a detailed study of the contribution of different loss terms to the task of multi-modal I2I translation, and propose a simple alternative to VAEs to enable sampling from unconstrained latent spaces. Finally, we achieve state-of-the-art results on six challenging benchmarks with a simple training objective that includes only a GAN loss and a reconstruction loss.