 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modulation Network for Audio-Visual Event Localization
Aug 30, 2021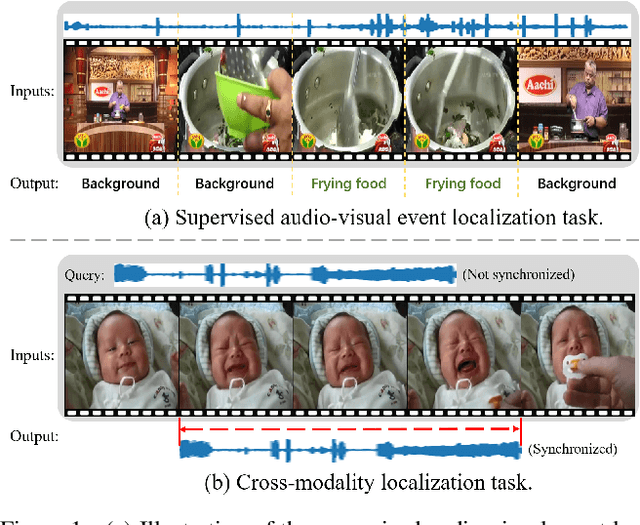

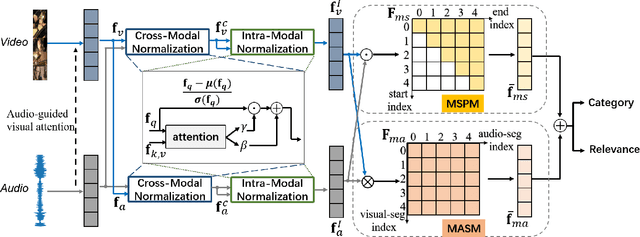
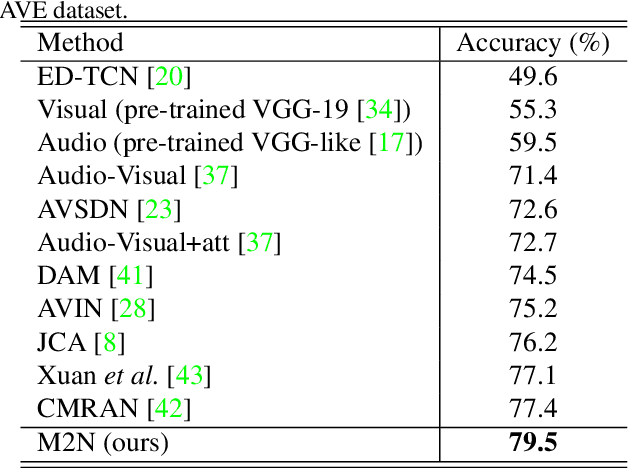
We study the problem of localizing audio-visual events that are both audible and visible in a video. Existing works focus on encoding and aligning audio and visual features at the segment level while neglecting informative correlation between segments of the two modalities and between multi-scale event proposals. We propose a novel MultiModulation Network (M2N) to learn the above correlation and leverage it as semantic guidance to modulate the related auditory, visual, and fused features. In particular, during feature encoding, we propose cross-modal normalization and intra-modal normalization. The former modulates the features of two modalities by establishing and exploiting the cross-modal relationship. The latter modulates the features of a single modality with the event-relevant semantic guidance of the same modality. In the fusion stage,we propose a multi-scale proposal modulating module and a multi-alignment segment modulating module to introduce multi-scale event proposals and enable dense matching between cross-modal segments. With the auditory, visual, and fused features modulated by the correlation information regarding audio-visual events, M2N performs accurate event localization. Extensive experiments conducted on the AVE dataset demonstrate that our proposed method outperforms the state of the art in both supervised event localization and cross-modality localization.
Learning Conditional Knowledge Distillation for Degraded-Reference Image Quality Assessment
Aug 18, 2021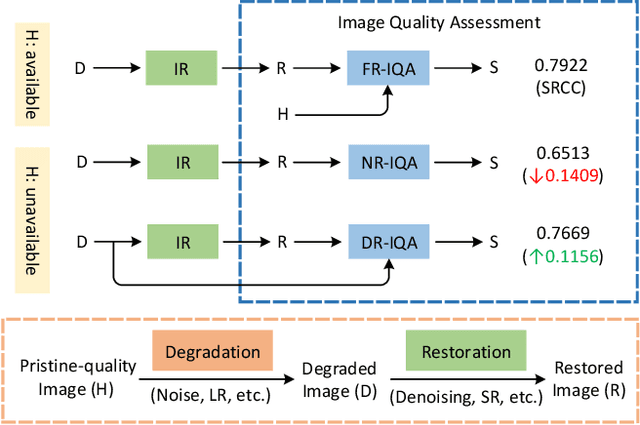
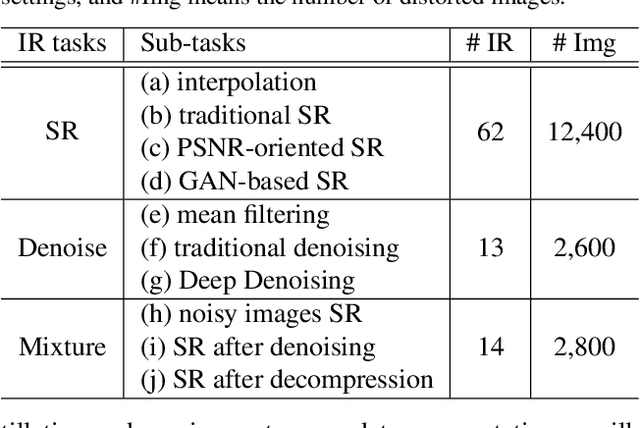
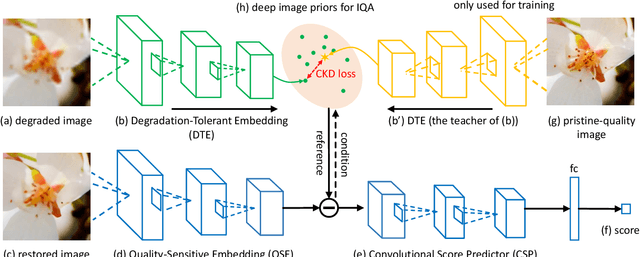
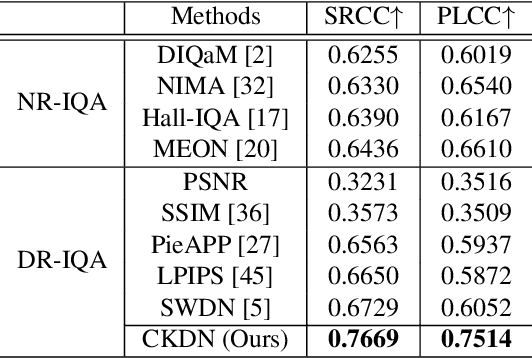
An important scenario for image quality assessment (IQA) is to evaluate image restoration (IR) algorithms. The state-of-the-art approaches adopt a full-reference paradigm that compares restored images with their corresponding pristine-quality images. However, pristine-quality images are usually unavailable in blind image restoration tasks and real-world scenarios. In this paper, we propose a practical solution named degraded-reference IQA (DR-IQA), which exploits the inputs of IR models, degraded images, as references. Specifically, we extract reference information from degraded images by distilling knowledge from pristine-quality images. The distillation is achieved through learning a reference space, where various degraded images are encouraged to share the same feature statistics with pristine-quality images. And the reference space is optimized to capture deep image priors that are useful for quality assessment. Note that pristine-quality images are only used during training. Our work provides a powerful and differentiable metric for blind IRs, especially for GAN-based methods. Extensive experiments show that our results can even be close to the performance of full-reference settings.
Learning Bias-Invariant Representation by Cross-Sample Mutual Information Minimization
Aug 13, 2021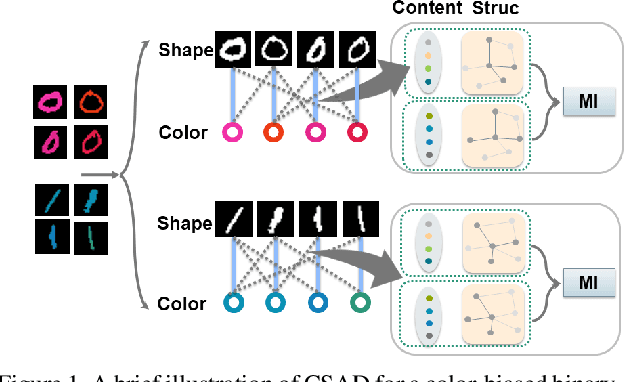
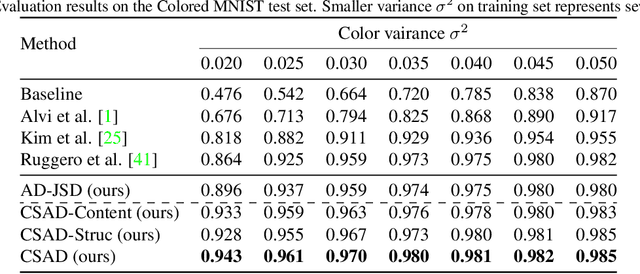
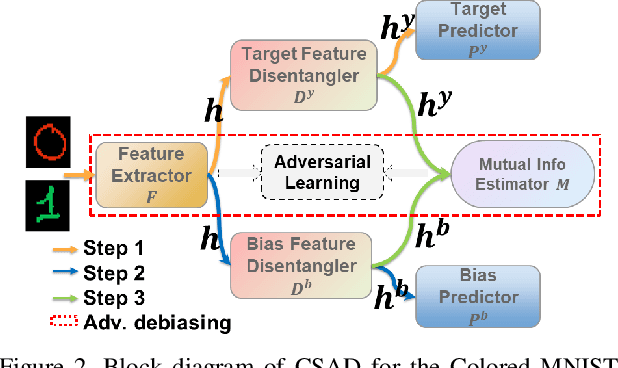
Deep learning algorithms mine knowledge from the training data and thus would likely inherit the dataset's bias information. As a result, the obtained model would generalize poorly and even mislead the decision process in real-life applications. We propose to remove the bias information misused by the target task with a cross-sample adversarial debiasing (CSAD) method. CSAD explicitly extracts target and bias features disentangled from the latent representation generated by a feature extractor and then learns to discover and remove the correlation between the target and bias features. The correlation measurement plays a critical role in adversarial debiasing and is conducted by a cross-sample neural mutual information estimator. Moreover, we propose joint content and local structural representation learning to boost mutual information estimation for better performance. We conduct thorough experiments on publicly available datasets to validate the advantages of the proposed method over state-of-the-art approaches.
UniFaceGAN: A Unified Framework for Temporally Consistent Facial Video Editing
Aug 12, 2021



Recent research has witnessed advances in facial image editing tasks including face swapping and face reenactment. However, these methods are confined to dealing with one specific task at a time. In addition, for video facial editing, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In this paper, we propose a unified temporally consistent facial video editing framework termed UniFaceGAN. Based on a 3D reconstruction model and a simple yet efficient dynamic training sample selection mechanism, our framework is designed to handle face swapping and face reenactment simultaneously. To enforce the temporal consistency, a novel 3D temporal loss constraint is introduced based on the barycentric coordinate interpolation. Besides, we propose a region-aware conditional normalization layer to replace the traditional AdaIN or SPADE to synthesize more context-harmonious results. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Boosting Entity-aware Image Captioning with Multi-modal Knowledge Graph
Jul 26, 2021
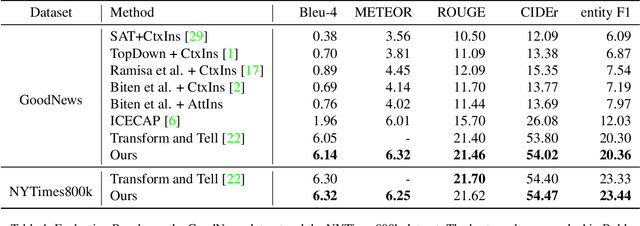
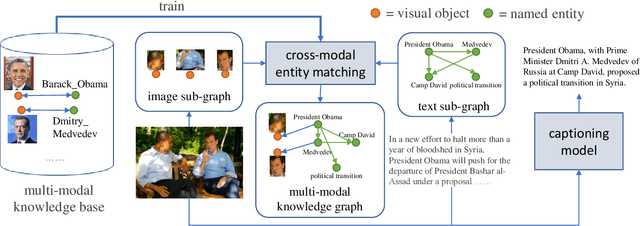
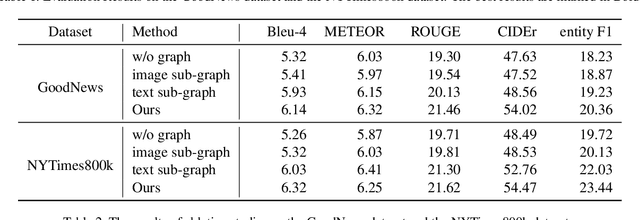
Entity-aware image captioning aims to describe named entities and events related to the image by utilizing the background knowledge in the associated article. This task remains challenging as it is difficult to learn the association between named entities and visual cues due to the long-tail distribution of named entities. Furthermore, the complexity of the article brings difficulty in extracting fine-grained relationships between entities to generate informative event descriptions about the image. To tackle these challenges, we propose a novel approach that constructs a multi-modal knowledge graph to associate the visual objects with named entities and capture the relationship between entities simultaneously with the help of external knowledge collected from the web. Specifically, we build a text sub-graph by extracting named entities and their relationships from the article, and build an image sub-graph by detecting the objects in the image. To connect these two sub-graphs, we propose a cross-modal entity matching module trained using a knowledge base that contains Wikipedia entries and the corresponding images. Finally, the multi-modal knowledge graph is integrated into the captioning model via a graph attention mechanism. Extensive experiments on both GoodNews and NYTimes800k datasets demonstrate the effectiveness of our method.
Adaptive Recursive Circle Framework for Fine-grained Action Recognition
Jul 25, 2021

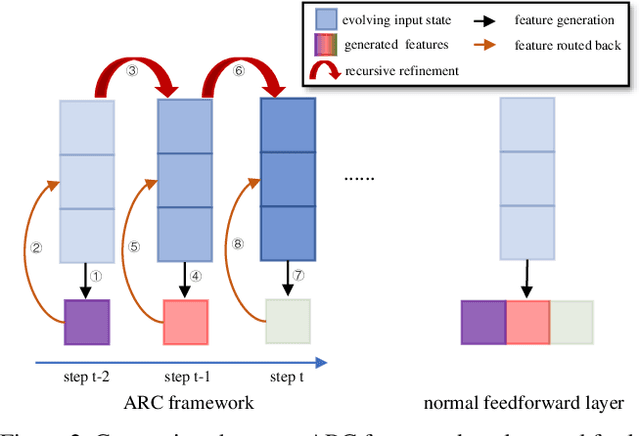
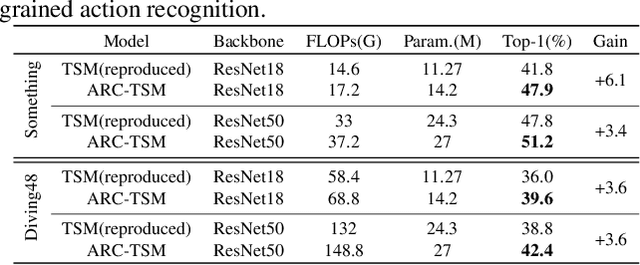
How to model fine-grained spatial-temporal dynamics in videos has been a challenging problem for action recognition. It requires learning deep and rich features with superior distinctiveness for the subtle and abstract motions. Most existing methods generate features of a layer in a pure feedforward manner, where the information moves in one direction from inputs to outputs. And they rely on stacking more layers to obtain more powerful features, bringing extra non-negligible overheads. In this paper, we propose an Adaptive Recursive Circle (ARC) framework, a fine-grained decorator for pure feedforward layers. It inherits the operators and parameters of the original layer but is slightly different in the use of those operators and parameters. Specifically, the input of the layer is treated as an evolving state, and its update is alternated with the feature generation. At each recursive step, the input state is enriched by the previously generated features and the feature generation is made with the newly updated input state. We hope the ARC framework can facilitate fine-grained action recognition by introducing deeply refined features and multi-scale receptive fields at a low cost. Significant improvements over feedforward baselines are observed on several benchmarks. For example, an ARC-equipped TSM-ResNet18 outperforms TSM-ResNet50 with 48% fewer FLOPs and 52% model parameters on Something-Something V1 and Diving48.
Triplet is All You Need with Random Mappings for Unsupervised Visual Representation Learning
Jul 22, 2021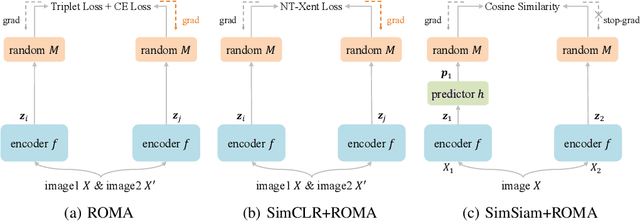
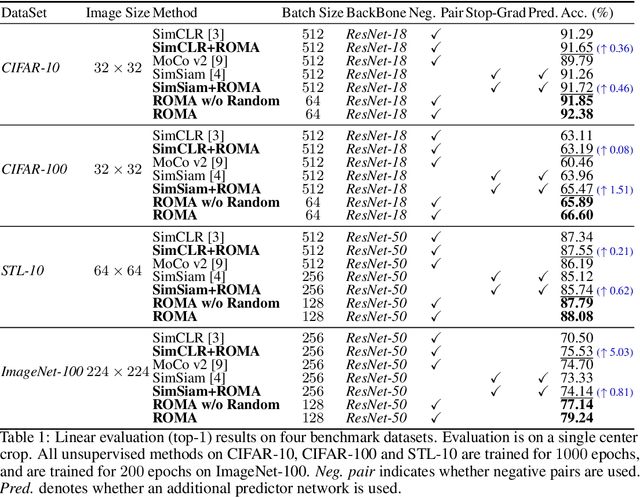
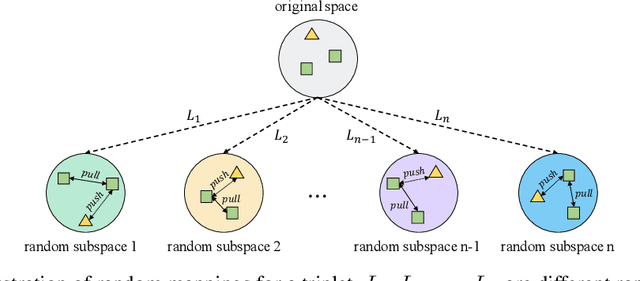

Contrastive self-supervised learning (SSL) has achieved great success in unsupervised visual representation learning by maximizing the similarity between two augmented views of the same image (positive pairs) and simultaneously contrasting other different images (negative pairs). However, this type of methods, such as SimCLR and MoCo, relies heavily on a large number of negative pairs and thus requires either large batches or memory banks. In contrast, some recent non-contrastive SSL methods, such as BYOL and SimSiam, attempt to discard negative pairs by introducing asymmetry and show remarkable performance. Unfortunately, to avoid collapsed solutions caused by not using negative pairs, these methods require sophisticated asymmetry designs. In this paper, we argue that negative pairs are still necessary but one is sufficient, i.e., triplet is all you need. A simple triplet-based loss can achieve surprisingly good performance without requiring large batches or asymmetry. Moreover, we observe that unsupervised visual representation learning can gain significantly from randomness. Based on this observation, we propose a simple plug-in RandOm MApping (ROMA) strategy by randomly mapping samples into other spaces and enforcing these randomly projected samples to satisfy the same correlation requirement. The proposed ROMA strategy not only achieves the state-of-the-art performance in conjunction with the triplet-based loss, but also can further effectively boost other SSL methods.
Noise Stability Regularization for Improving BERT Fine-tuning
Jul 10, 2021
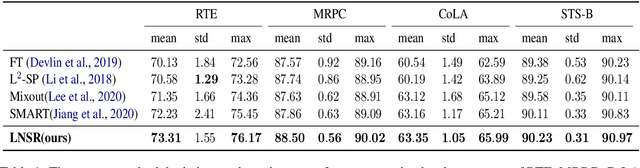

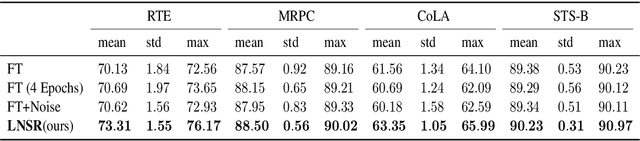
Fine-tuning pre-trained language models such as BERT has become a common practice dominating leaderboards across various NLP tasks. Despite its recent success and wide adoption, this process is unstable when there are only a small number of training samples available. The brittleness of this process is often reflected by the sensitivity to random seeds. In this paper, we propose to tackle this problem based on the noise stability property of deep nets, which is investigated in recent literature (Arora et al., 2018; Sanyal et al., 2020). Specifically, we introduce a novel and effective regularization method to improve fine-tuning on NLP tasks, referred to as Layer-wise Noise Stability Regularization (LNSR). We extend the theories about adding noise to the input and prove that our method gives a stabler regularization effect. We provide supportive evidence by experimentally confirming that well-performing models show a low sensitivity to noise and fine-tuning with LNSR exhibits clearly higher generalizability and stability. Furthermore, our method also demonstrates advantages over other state-of-the-art algorithms including L2-SP (Li et al., 2018), Mixout (Lee et al., 2020) and SMART (Jiang et al., 2020).
Probing Inter-modality: Visual Parsing with Self-Attention for Vision-Language Pre-training
Jun 28, 2021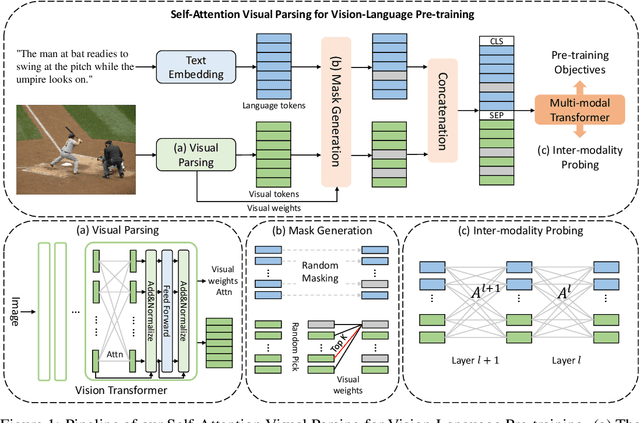
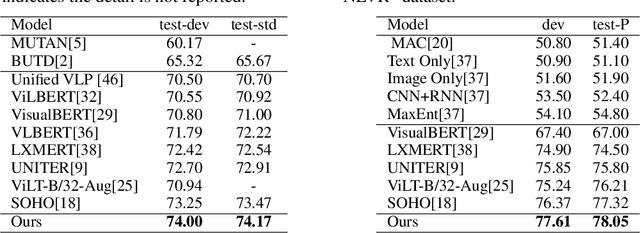

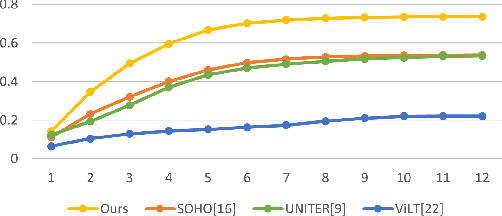
Vision-Language Pre-training (VLP) aims to learn multi-modal representations from image-text pairs and serves for downstream vision-language tasks in a fine-tuning fashion. The dominant VLP models adopt a CNN-Transformer architecture, which embeds images with a CNN, and then aligns images and text with a Transformer. Visual relationship between visual contents plays an important role in image understanding and is the basic for inter-modal alignment learning. However, CNNs have limitations in visual relation learning due to local receptive field's weakness in modeling long-range dependencies. Thus the two objectives of learning visual relation and inter-modal alignment are encapsulated in the same Transformer network. Such design might restrict the inter-modal alignment learning in the Transformer by ignoring the specialized characteristic of each objective. To tackle this, we propose a fully Transformer visual embedding for VLP to better learn visual relation and further promote inter-modal alignment. Specifically, we propose a metric named Inter-Modality Flow (IMF) to measure the interaction between vision and language modalities (i.e., inter-modality). We also design a novel masking optimization mechanism named Masked Feature Regression (MFR) in Transformer to further promote the inter-modality learning. To the best of our knowledge, this is the first study to explore the benefit of Transformer for visual feature learning in VLP. We verify our method on a wide range of vision-language tasks, including Image-Text Retrieval, Visual Question Answering (VQA), Visual Entailment and Visual Reasoning. Our approach not only outperforms the state-of-the-art VLP performance, but also shows benefits on the IMF metric.
How COVID-19 Have Changed Crowdfunding: Evidence From GoFundMe
Jun 18, 2021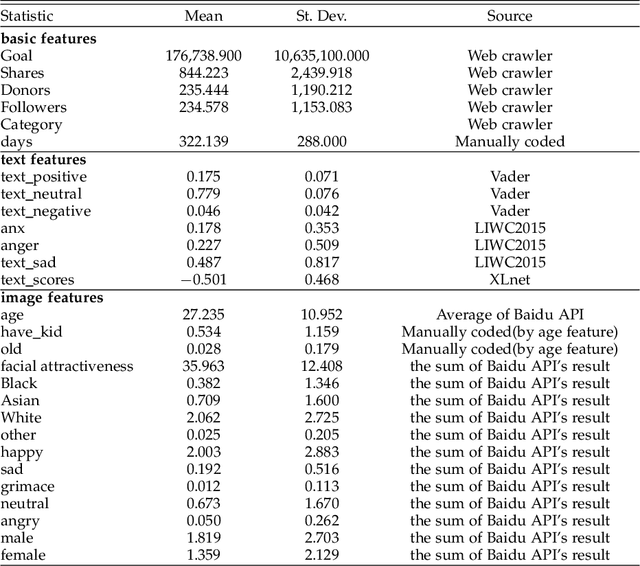
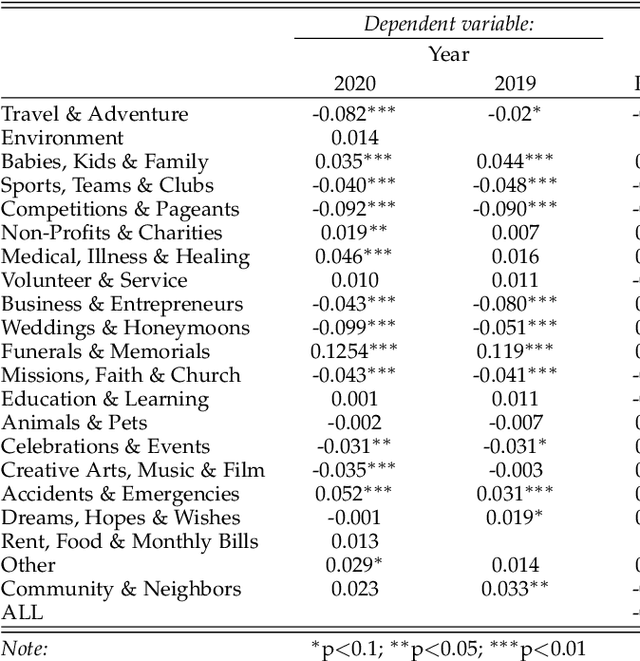
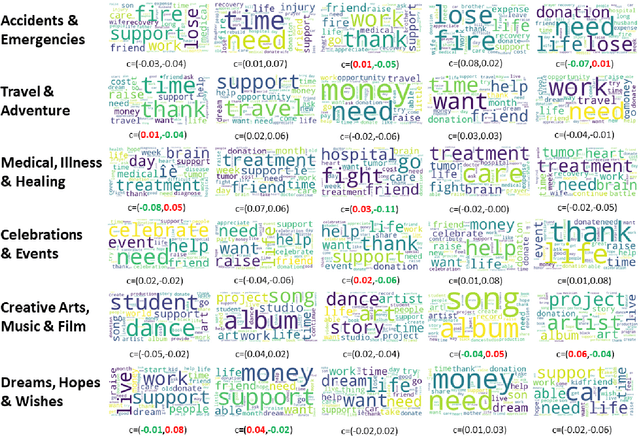
While the long-term effects of COVID-19 are yet to be determined, its immediate impact on crowdfunding is nonetheless significant. This study takes a computational approach to more deeply comprehend this change. Using a unique data set of all the campaigns published over the past two years on GoFundMe, we explore the factors that have led to the successful funding of a crowdfunding project. In particular, we study a corpus of crowdfunded projects, analyzing cover images and other variables commonly present on crowdfunding sites. Furthermore, we construct a classifier and a regression model to assess the significance of features based on XGBoost. In addition, we employ counterfactual analysis to investigate the causality between features and the success of crowdfunding. More importantly, sentiment analysis and the paired sample t-test are performed to examine the differences in crowdfunding campaigns before and after the COVID-19 outbreak that started in March 2020. First, we note that there is significant racial disparity in crowdfunding success. Second, we find that sad emotion expressed through the campaign's description became significant after the COVID-19 outbreak. Considering all these factors, our findings shed light on the impact of COVID-19 on crowdfunding campaigns.