 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilver Linings in the Shadows: Harnessing Membership Inference for Machine Unlearning
Jul 01, 2024



With the continued advancement and widespread adoption of machine learning (ML) models across various domains, ensuring user privacy and data security has become a paramount concern. In compliance with data privacy regulations, such as GDPR, a secure machine learning framework should not only grant users the right to request the removal of their contributed data used for model training but also facilitates the elimination of sensitive data fingerprints within machine learning models to mitigate potential attack - a process referred to as machine unlearning. In this study, we present a novel unlearning mechanism designed to effectively remove the impact of specific data samples from a neural network while considering the performance of the unlearned model on the primary task. In achieving this goal, we crafted a novel loss function tailored to eliminate privacy-sensitive information from weights and activation values of the target model by combining target classification loss and membership inference loss. Our adaptable framework can easily incorporate various privacy leakage approximation mechanisms to guide the unlearning process. We provide empirical evidence of the effectiveness of our unlearning approach with a theoretical upper-bound analysis through a membership inference mechanism as a proof of concept. Our results showcase the superior performance of our approach in terms of unlearning efficacy and latency as well as the fidelity of the primary task, across four datasets and four deep learning architectures.
Unveiling the Unseen: Exploring Whitebox Membership Inference through the Lens of Explainability
Jul 01, 2024



The increasing prominence of deep learning applications and reliance on personalized data underscore the urgent need to address privacy vulnerabilities, particularly Membership Inference Attacks (MIAs). Despite numerous MIA studies, significant knowledge gaps persist, particularly regarding the impact of hidden features (in isolation) on attack efficacy and insufficient justification for the root causes of attacks based on raw data features. In this paper, we aim to address these knowledge gaps by first exploring statistical approaches to identify the most informative neurons and quantifying the significance of the hidden activations from the selected neurons on attack accuracy, in isolation and combination. Additionally, we propose an attack-driven explainable framework by integrating the target and attack models to identify the most influential features of raw data that lead to successful membership inference attacks. Our proposed MIA shows an improvement of up to 26% on state-of-the-art MIA.
HNS: An Efficient Hermite Neural Solver for Solving Time-Fractional Partial Differential Equations
Oct 07, 2023



Neural network solvers represent an innovative and promising approach for tackling time-fractional partial differential equations by utilizing deep learning techniques. L1 interpolation approximation serves as the standard method for addressing time-fractional derivatives within neural network solvers. However, we have discovered that neural network solvers based on L1 interpolation approximation are unable to fully exploit the benefits of neural networks, and the accuracy of these models is constrained to interpolation errors. In this paper, we present the high-precision Hermite Neural Solver (HNS) for solving time-fractional partial differential equations. Specifically, we first construct a high-order explicit approximation scheme for fractional derivatives using Hermite interpolation techniques, and rigorously analyze its approximation accuracy. Afterward, taking into account the infinitely differentiable properties of deep neural networks, we integrate the high-order Hermite interpolation explicit approximation scheme with deep neural networks to propose the HNS. The experimental results show that HNS achieves higher accuracy than methods based on the L1 scheme for both forward and inverse problems, as well as in high-dimensional scenarios. This indicates that HNS has significantly improved accuracy and flexibility compared to existing L1-based methods, and has overcome the limitations of explicit finite difference approximation methods that are often constrained to function value interpolation. As a result, the HNS is not a simple combination of numerical computing methods and neural networks, but rather achieves a complementary and mutually reinforcing advantages of both approaches. The data and code can be found at \url{https://github.com/hsbhc/HNS}.
PMNN:Physical Model-driven Neural Network for solving time-fractional differential equations
Oct 07, 2023



In this paper, an innovative Physical Model-driven Neural Network (PMNN) method is proposed to solve time-fractional differential equations. It establishes a temporal iteration scheme based on physical model-driven neural networks which effectively combines deep neural networks (DNNs) with interpolation approximation of fractional derivatives. Specifically, once the fractional differential operator is discretized, DNNs are employed as a bridge to integrate interpolation approximation techniques with differential equations. On the basis of this integration, we construct a neural-based iteration scheme. Subsequently, by training DNNs to learn this temporal iteration scheme, approximate solutions to the differential equations can be obtained. The proposed method aims to preserve the intrinsic physical information within the equations as far as possible. It fully utilizes the powerful fitting capability of neural networks while maintaining the efficiency of the difference schemes for fractional differential equations. Moreover, we validate the efficiency and accuracy of PMNN through several numerical experiments.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
EmotionGesture: Audio-Driven Diverse Emotional Co-Speech 3D Gesture Generation
May 30, 2023



Generating vivid and diverse 3D co-speech gestures is crucial for various applications in animating virtual avatars. While most existing methods can generate gestures from audio directly, they usually overlook that emotion is one of the key factors of authentic co-speech gesture generation. In this work, we propose EmotionGesture, a novel framework for synthesizing vivid and diverse emotional co-speech 3D gestures from audio. Considering emotion is often entangled with the rhythmic beat in speech audio, we first develop an Emotion-Beat Mining module (EBM) to extract the emotion and audio beat features as well as model their correlation via a transcript-based visual-rhythm alignment. Then, we propose an initial pose based Spatial-Temporal Prompter (STP) to generate future gestures from the given initial poses. STP effectively models the spatial-temporal correlations between the initial poses and the future gestures, thus producing the spatial-temporal coherent pose prompt. Once we obtain pose prompts, emotion, and audio beat features, we will generate 3D co-speech gestures through a transformer architecture. However, considering the poses of existing datasets often contain jittering effects, this would lead to generating unstable gestures. To address this issue, we propose an effective objective function, dubbed Motion-Smooth Loss. Specifically, we model motion offset to compensate for jittering ground-truth by forcing gestures to be smooth. Last, we present an emotion-conditioned VAE to sample emotion features, enabling us to generate diverse emotional results. Extensive experiments demonstrate that our framework outperforms the state-of-the-art, achieving vivid and diverse emotional co-speech 3D gestures.
Community Detection Using Revised Medoid-Shift Based on KNN
Apr 19, 2023Community detection becomes an important problem with the booming of social networks. As an excellent clustering algorithm, Mean-Shift can not be applied directly to community detection, since Mean-Shift can only handle data with coordinates, while the data in the community detection problem is mostly represented by a graph that can be treated as data with a distance matrix (or similarity matrix). Fortunately, a new clustering algorithm called Medoid-Shift is proposed. The Medoid-Shift algorithm preserves the benefits of Mean-Shift and can be applied to problems based on distance matrix, such as community detection. One drawback of the Medoid-Shift algorithm is that there may be no data points within the neighborhood region defined by a distance parameter. To deal with the community detection problem better, a new algorithm called Revised Medoid-Shift (RMS) in this work is thus proposed. During the process of finding the next medoid, the RMS algorithm is based on a neighborhood defined by KNN, while the original Medoid-Shift is based on a neighborhood defined by a distance parameter. Since the neighborhood defined by KNN is more stable than the one defined by the distance parameter in terms of the number of data points within the neighborhood, the RMS algorithm may converge more smoothly. In the RMS method, each of the data points is shifted towards a medoid within the neighborhood defined by KNN. After the iterative process of shifting, each of the data point converges into a cluster center, and the data points converging into the same center are grouped into the same cluster.
Artificial Intelligence Advances for De Novo Molecular Structure Modeling in Cryo-EM
Feb 24, 2021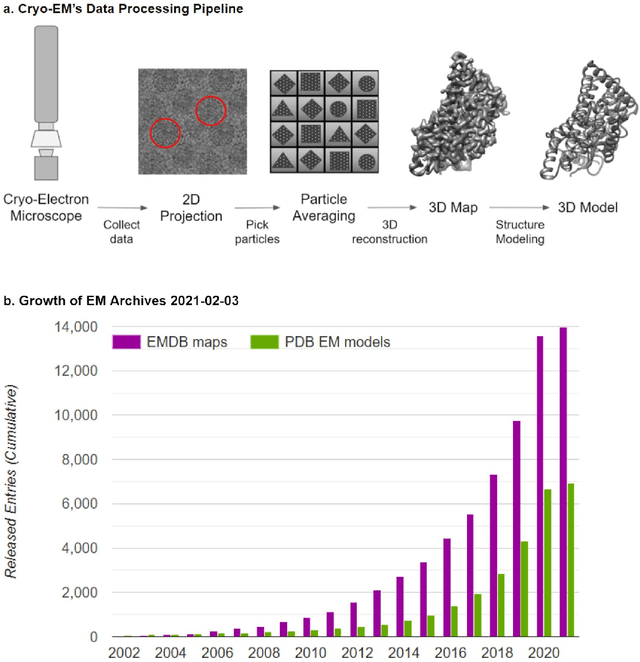


Cryo-electron microscopy (cryo-EM) has become a major experimental technique to determine the structures of large protein complexes and molecular assemblies, as evidenced by the 2017 Nobel Prize. Although cryo-EM has been drastically improved to generate high-resolution three-dimensional (3D) maps that contain detailed structural information about macromolecules, the computational methods for using the data to automatically build structure models are lagging far behind. The traditional cryo-EM model building approach is template-based homology modeling. Manual de novo modeling is very time-consuming when no template model is found in the database. In recent years, de novo cryo-EM modeling using machine learning (ML) and deep learning (DL) has ranked among the top-performing methods in macromolecular structure modeling. Deep-learning-based de novo cryo-EM modeling is an important application of artificial intelligence, with impressive results and great potential for the next generation of molecular biomedicine. Accordingly, we systematically review the representative ML/DL-based de novo cryo-EM modeling methods. And their significances are discussed from both practical and methodological viewpoints. We also briefly describe the background of cryo-EM data processing workflow. Overall, this review provides an introductory guide to modern research on artificial intelligence (AI) for de novo molecular structure modeling and future directions in this emerging field.
Semi-Supervised Learning for In-Game Expert-Level Music-to-Dance Translation
Sep 27, 2020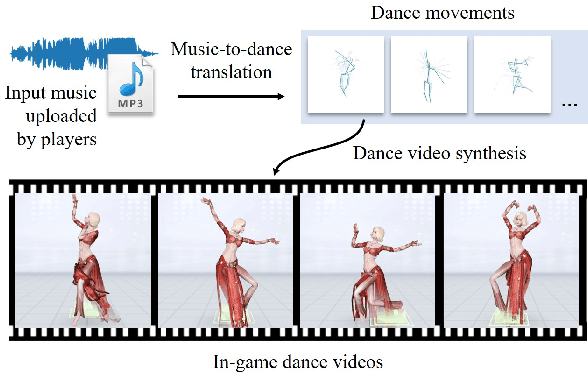

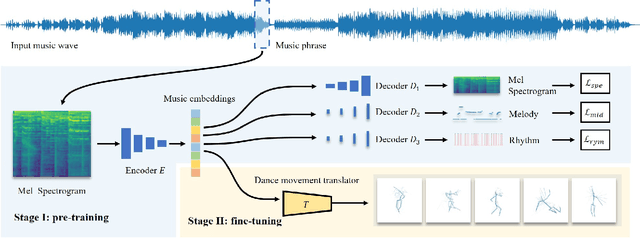

Music-to-dance translation is a brand-new and powerful feature in recent role-playing games. Players can now let their characters dance along with specified music clips and even generate fan-made dance videos. Previous works of this topic consider music-to-dance as a supervised motion generation problem based on time-series data. However, these methods suffer from limited training data pairs and the degradation of movements. This paper provides a new perspective for this task where we re-formulate the translation problem as a piece-wise dance phrase retrieval problem based on the choreography theory. With such a design, players are allowed to further edit the dance movements on top of our generation while other regression based methods ignore such user interactivity. Considering that the dance motion capture is an expensive and time-consuming procedure which requires the assistance of professional dancers, we train our method under a semi-supervised learning framework with a large unlabeled dataset (20x than labeled data) collected. A co-ascent mechanism is introduced to improve the robustness of our network. Using this unlabeled dataset, we also introduce self-supervised pre-training so that the translator can understand the melody, rhythm, and other components of music phrases. We show that the pre-training significantly improves the translation accuracy than that of training from scratch. Experimental results suggest that our method not only generalizes well over various styles of music but also succeeds in expert-level choreography for game players.
A Brand-level Ranking System with the Customized Attention-GRU Model
Aug 11, 2018
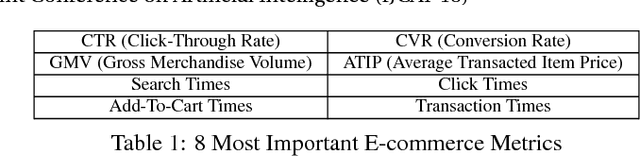
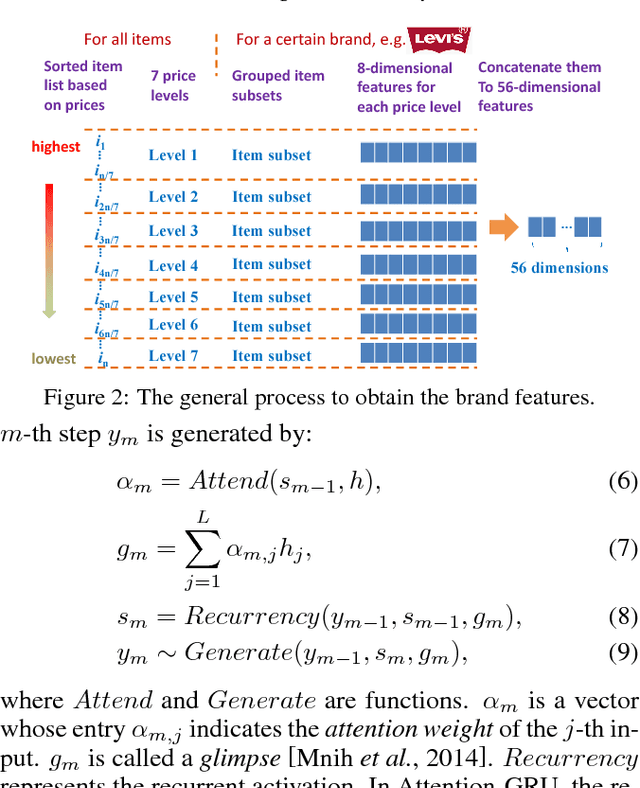
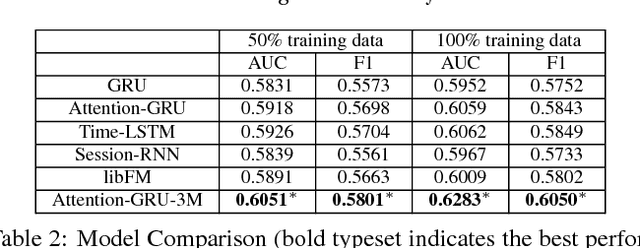
In e-commerce websites like Taobao, brand is playing a more important role in influencing users' decision of click/purchase, partly because users are now attaching more importance to the quality of products and brand is an indicator of quality. However, existing ranking systems are not specifically designed to satisfy this kind of demand. Some design tricks may partially alleviate this problem, but still cannot provide satisfactory results or may create additional interaction cost. In this paper, we design the first brand-level ranking system to address this problem. The key challenge of this system is how to sufficiently exploit users' rich behavior in e-commerce websites to rank the brands. In our solution, we firstly conduct the feature engineering specifically tailored for the personalized brand ranking problem and then rank the brands by an adapted Attention-GRU model containing three important modifications. Note that our proposed modifications can also apply to many other machine learning models on various tasks. We conduct a series of experiments to evaluate the effectiveness of our proposed ranking model and test the response to the brand-level ranking system from real users on a large-scale e-commerce platform, i.e. Taobao.
* 7 pages, 6 figures, 3 tables. Published in IJCAI 2018. Make some figures and tables more clear