 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping the KL Agreement Trap in On-Policy Distillation
Jun 08, 2026On-policy distillation (OPD) provides dense token-level supervision by asking a teacher to score student-generated rollouts. However, when the student drifts into an unrecoverable prefix, the teacher may locally agree with the degraded state, producing low reverse KL but little corrective training signal. We identify this persistent regime as a low-KL agreement trap. Further analyses show that tokens during and after such traps produce less useful supervision signals. We propose KAT (KL Agreement Trap Termination), an online OPD termination rule that detects persistent low-KL agreement with a dynamic training-adaptive threshold. By filtering weak supervision from degenerate agreement, KAT improves avg@k accuracy by 2.66% and pass@k by 3.43% across four mathematical benchmarks, while reducing average rollout length by 59.73%.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
LLMs as Better Recommenders with Natural Language Collaborative Signals: A Self-Assessing Retrieval Approach
May 26, 2025Incorporating collaborative information (CI) effectively is crucial for leveraging LLMs in recommendation tasks. Existing approaches often encode CI using soft tokens or abstract identifiers, which introduces a semantic misalignment with the LLM's natural language pretraining and hampers knowledge integration. To address this, we propose expressing CI directly in natural language to better align with LLMs' semantic space. We achieve this by retrieving a curated set of the most relevant user behaviors in natural language form. However, identifying informative CI is challenging due to the complexity of similarity and utility assessment. To tackle this, we introduce a Self-assessing COllaborative REtrieval framework (SCORE) following the retrieve-rerank paradigm. First, a Collaborative Retriever (CAR) is developed to consider both collaborative patterns and semantic similarity. Then, a Self-assessing Reranker (SARE) leverages LLMs' own reasoning to assess and prioritize retrieved behaviors. Finally, the selected behaviors are prepended to the LLM prompt as natural-language CI to guide recommendation. Extensive experiments on two public datasets validate the effectiveness of SCORE in improving LLM-based recommendation.
Improving Recommendation Fairness without Sensitive Attributes Using Multi-Persona LLMs
May 26, 2025Despite the success of recommender systems in alleviating information overload, fairness issues have raised concerns in recent years, potentially leading to unequal treatment for certain user groups. While efforts have been made to improve recommendation fairness, they often assume that users' sensitive attributes are available during model training. However, collecting sensitive information can be difficult, especially on platforms that involve no personal information disclosure. Therefore, we aim to improve recommendation fairness without any access to sensitive attributes. However, this is a non-trivial task because uncovering latent sensitive patterns from complicated user behaviors without explicit sensitive attributes can be difficult. Consequently, suboptimal estimates of sensitive distributions can hinder the fairness training process. To address these challenges, leveraging the remarkable reasoning abilities of Large Language Models (LLMs), we propose a novel LLM-enhanced framework for Fair recommendation withOut Sensitive Attributes (LLMFOSA). A Multi-Persona Sensitive Information Inference module employs LLMs with distinct personas that mimic diverse human perceptions to infer and distill sensitive information. Furthermore, a Confusion-Aware Sensitive Representation Learning module incorporates inference results and rationales to develop robust sensitive representations, considering the mislabeling confusion and collective consensus among agents. The model is then optimized by a formulated mutual information objective. Extensive experiments on two public datasets validate the effectiveness of LLMFOSA in improving fairness.
Benchmarking Poisoning Attacks against Retrieval-Augmented Generation
May 24, 2025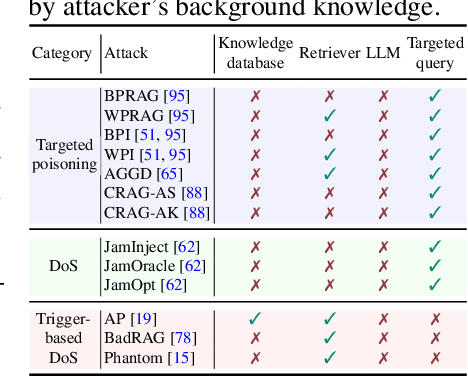
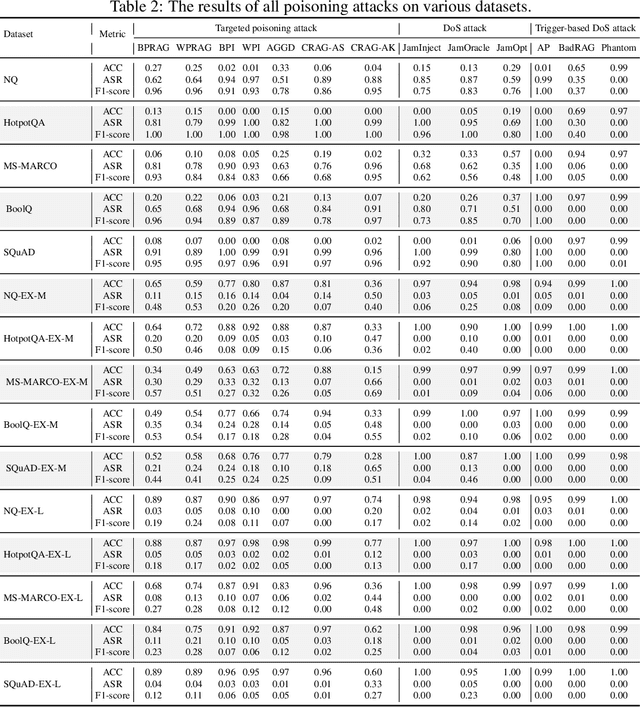
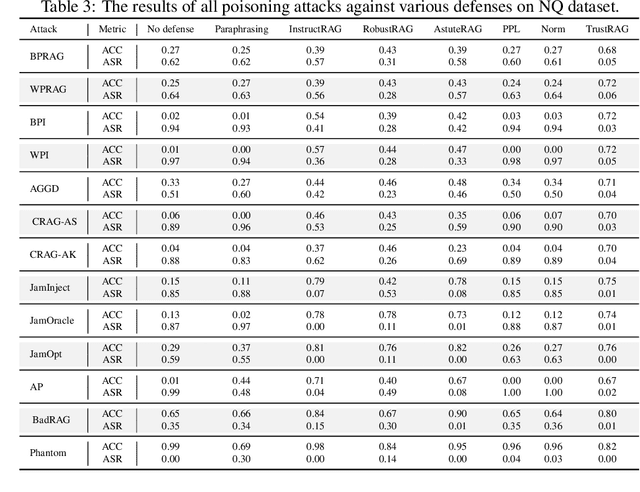
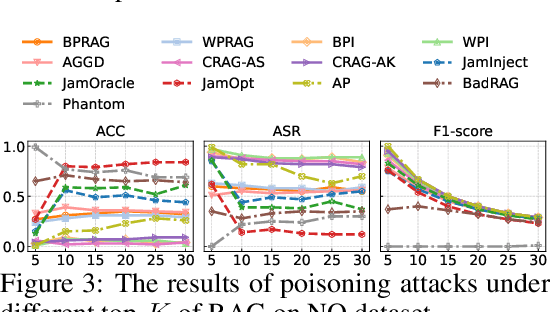
Retrieval-Augmented Generation (RAG) has proven effective in mitigating hallucinations in large language models by incorporating external knowledge during inference. However, this integration introduces new security vulnerabilities, particularly to poisoning attacks. Although prior work has explored various poisoning strategies, a thorough assessment of their practical threat to RAG systems remains missing. To address this gap, we propose the first comprehensive benchmark framework for evaluating poisoning attacks on RAG. Our benchmark covers 5 standard question answering (QA) datasets and 10 expanded variants, along with 13 poisoning attack methods and 7 defense mechanisms, representing a broad spectrum of existing techniques. Using this benchmark, we conduct a comprehensive evaluation of all included attacks and defenses across the full dataset spectrum. Our findings show that while existing attacks perform well on standard QA datasets, their effectiveness drops significantly on the expanded versions. Moreover, our results demonstrate that various advanced RAG architectures, such as sequential, branching, conditional, and loop RAG, as well as multi-turn conversational RAG, multimodal RAG systems, and RAG-based LLM agent systems, remain susceptible to poisoning attacks. Notably, current defense techniques fail to provide robust protection, underscoring the pressing need for more resilient and generalizable defense strategies.
Traceback of Poisoning Attacks to Retrieval-Augmented Generation
Apr 30, 2025



Large language models (LLMs) integrated with retrieval-augmented generation (RAG) systems improve accuracy by leveraging external knowledge sources. However, recent research has revealed RAG's susceptibility to poisoning attacks, where the attacker injects poisoned texts into the knowledge database, leading to attacker-desired responses. Existing defenses, which predominantly focus on inference-time mitigation, have proven insufficient against sophisticated attacks. In this paper, we introduce RAGForensics, the first traceback system for RAG, designed to identify poisoned texts within the knowledge database that are responsible for the attacks. RAGForensics operates iteratively, first retrieving a subset of texts from the database and then utilizing a specially crafted prompt to guide an LLM in detecting potential poisoning texts. Empirical evaluations across multiple datasets demonstrate the effectiveness of RAGForensics against state-of-the-art poisoning attacks. This work pioneers the traceback of poisoned texts in RAG systems, providing a practical and promising defense mechanism to enhance their security.
EmotionGesture: Audio-Driven Diverse Emotional Co-Speech 3D Gesture Generation
May 30, 2023



Generating vivid and diverse 3D co-speech gestures is crucial for various applications in animating virtual avatars. While most existing methods can generate gestures from audio directly, they usually overlook that emotion is one of the key factors of authentic co-speech gesture generation. In this work, we propose EmotionGesture, a novel framework for synthesizing vivid and diverse emotional co-speech 3D gestures from audio. Considering emotion is often entangled with the rhythmic beat in speech audio, we first develop an Emotion-Beat Mining module (EBM) to extract the emotion and audio beat features as well as model their correlation via a transcript-based visual-rhythm alignment. Then, we propose an initial pose based Spatial-Temporal Prompter (STP) to generate future gestures from the given initial poses. STP effectively models the spatial-temporal correlations between the initial poses and the future gestures, thus producing the spatial-temporal coherent pose prompt. Once we obtain pose prompts, emotion, and audio beat features, we will generate 3D co-speech gestures through a transformer architecture. However, considering the poses of existing datasets often contain jittering effects, this would lead to generating unstable gestures. To address this issue, we propose an effective objective function, dubbed Motion-Smooth Loss. Specifically, we model motion offset to compensate for jittering ground-truth by forcing gestures to be smooth. Last, we present an emotion-conditioned VAE to sample emotion features, enabling us to generate diverse emotional results. Extensive experiments demonstrate that our framework outperforms the state-of-the-art, achieving vivid and diverse emotional co-speech 3D gestures.
Intelligent Electric Vehicle Charging Recommendation Based on Multi-Agent Reinforcement Learning
Feb 15, 2021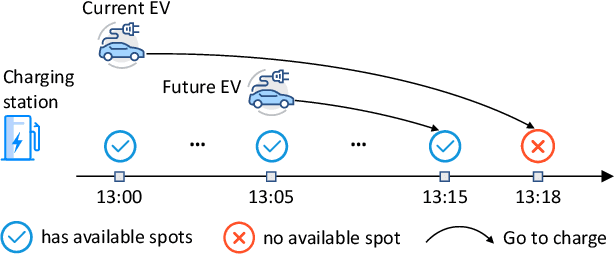
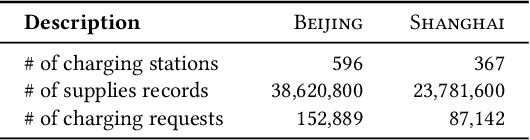
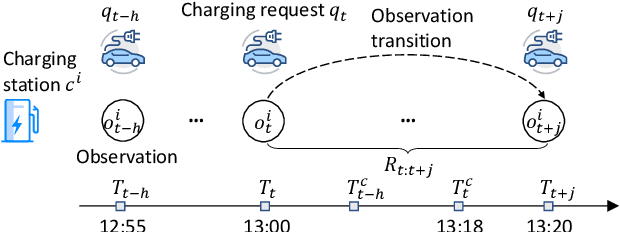
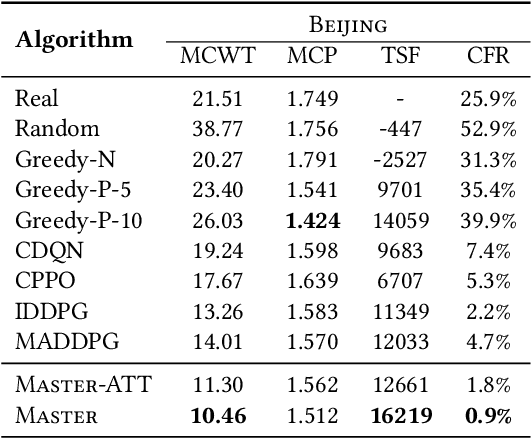
Electric Vehicle (EV) has become a preferable choice in the modern transportation system due to its environmental and energy sustainability. However, in many large cities, EV drivers often fail to find the proper spots for charging, because of the limited charging infrastructures and the spatiotemporally unbalanced charging demands. Indeed, the recent emergence of deep reinforcement learning provides great potential to improve the charging experience from various aspects over a long-term horizon. In this paper, we propose a framework, named Multi-Agent Spatio-Temporal Reinforcement Learning (Master), for intelligently recommending public accessible charging stations by jointly considering various long-term spatiotemporal factors. Specifically, by regarding each charging station as an individual agent, we formulate this problem as a multi-objective multi-agent reinforcement learning task. We first develop a multi-agent actor-critic framework with the centralized attentive critic to coordinate the recommendation between geo-distributed agents. Moreover, to quantify the influence of future potential charging competition, we introduce a delayed access strategy to exploit the knowledge of future charging competition during training. After that, to effectively optimize multiple learning objectives, we extend the centralized attentive critic to multi-critics and develop a dynamic gradient re-weighting strategy to adaptively guide the optimization direction. Finally, extensive experiments on two real-world datasets demonstrate that Master achieves the best comprehensive performance compared with nine baseline approaches.
Out-of-Town Recommendation with Travel Intention Modeling
Feb 06, 2021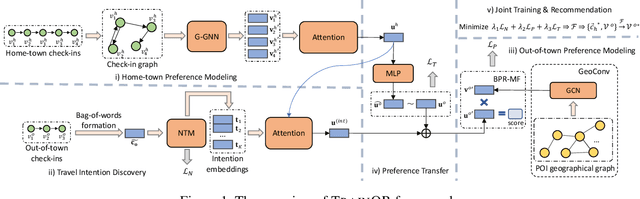
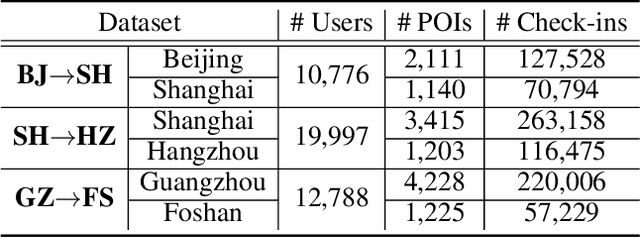
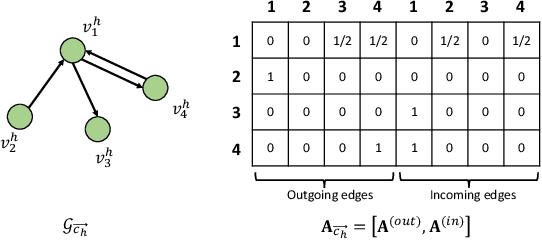
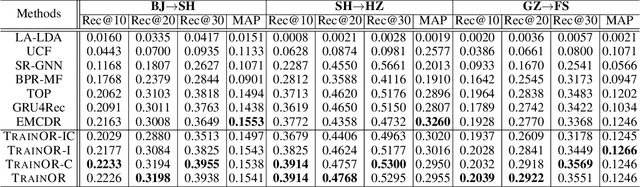
Out-of-town recommendation is designed for those users who leave their home-town areas and visit the areas they have never been to before. It is challenging to recommend Point-of-Interests (POIs) for out-of-town users since the out-of-town check-in behavior is determined by not only the user's home-town preference but also the user's travel intention. Besides, the user's travel intentions are complex and dynamic, which leads to big difficulties in understanding such intentions precisely. In this paper, we propose a TRAvel-INtention-aware Out-of-town Recommendation framework, named TRAINOR. The proposed TRAINOR framework distinguishes itself from existing out-of-town recommenders in three aspects. First, graph neural networks are explored to represent users' home-town check-in preference and geographical constraints in out-of-town check-in behaviors. Second, a user-specific travel intention is formulated as an aggregation combining home-town preference and generic travel intention together, where the generic travel intention is regarded as a mixture of inherent intentions that can be learned by Neural Topic Model (NTM). Third, a non-linear mapping function, as well as a matrix factorization method, are employed to transfer users' home-town preference and estimate out-of-town POI's representation, respectively. Extensive experiments on real-world data sets validate the effectiveness of the TRAINOR framework. Moreover, the learned travel intention can deliver meaningful explanations for understanding a user's travel purposes.