 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking 1-bit Optimization Leveraging Pre-trained Large Language Models
Aug 09, 2025



1-bit LLM quantization offers significant advantages in reducing storage and computational costs. However, existing methods typically train 1-bit LLMs from scratch, failing to fully leverage pre-trained models. This results in high training costs and notable accuracy degradation. We identify that the large gap between full precision and 1-bit representations makes direct adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the floating-point weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.
Efficient Long-Context LLM Inference via KV Cache Clustering
Jun 13, 2025



Large language models (LLMs) with extended context windows have become increasingly prevalent for tackling complex tasks. However, the substantial Key-Value (KV) cache required for long-context LLMs poses significant deployment challenges. Existing approaches either discard potentially critical information needed for future generations or offer limited efficiency gains due to high computational overhead. In this paper, we introduce Chelsea, a simple yet effective framework for online KV cache clustering. Our approach is based on the observation that key states exhibit high similarity along the sequence dimension. To enable efficient clustering, we divide the sequence into chunks and propose Chunked Soft Matching, which employs an alternating partition strategy within each chunk and identifies clusters based on similarity. Chelsea then merges the KV cache within each cluster into a single centroid. Additionally, we provide a theoretical analysis of the computational complexity and the optimality of the intra-chunk partitioning strategy. Extensive experiments across various models and long-context benchmarks demonstrate that Chelsea achieves up to 80% reduction in KV cache memory usage while maintaining comparable model performance. Moreover, with minimal computational overhead, Chelsea accelerates the decoding stage of inference by up to 3.19$\times$ and reduces end-to-end latency by up to 2.72$\times$.
Adversarial Preference Learning for Robust LLM Alignment
May 30, 2025



Modern language models often rely on Reinforcement Learning from Human Feedback (RLHF) to encourage safe behaviors. However, they remain vulnerable to adversarial attacks due to three key limitations: (1) the inefficiency and high cost of human annotation, (2) the vast diversity of potential adversarial attacks, and (3) the risk of feedback bias and reward hacking. To address these challenges, we introduce Adversarial Preference Learning (APL), an iterative adversarial training method incorporating three key innovations. First, a direct harmfulness metric based on the model's intrinsic preference probabilities, eliminating reliance on external assessment. Second, a conditional generative attacker that synthesizes input-specific adversarial variations. Third, an iterative framework with automated closed-loop feedback, enabling continuous adaptation through vulnerability discovery and mitigation. Experiments on Mistral-7B-Instruct-v0.3 demonstrate that APL significantly enhances robustness, achieving 83.33% harmlessness win rate over the base model (evaluated by GPT-4o), reducing harmful outputs from 5.88% to 0.43% (measured by LLaMA-Guard), and lowering attack success rate by up to 65% according to HarmBench. Notably, APL maintains competitive utility, with an MT-Bench score of 6.59 (comparable to the baseline 6.78) and an LC-WinRate of 46.52% against the base model.
DisTime: Distribution-based Time Representation for Video Large Language Models
May 30, 2025



Despite advances in general video understanding, Video Large Language Models (Video-LLMs) face challenges in precise temporal localization due to discrete time representations and limited temporally aware datasets. Existing methods for temporal expression either conflate time with text-based numerical values, add a series of dedicated temporal tokens, or regress time using specialized temporal grounding heads. To address these issues, we introduce DisTime, a lightweight framework designed to enhance temporal comprehension in Video-LLMs. DisTime employs a learnable token to create a continuous temporal embedding space and incorporates a Distribution-based Time Decoder that generates temporal probability distributions, effectively mitigating boundary ambiguities and maintaining temporal continuity. Additionally, the Distribution-based Time Encoder re-encodes timestamps to provide time markers for Video-LLMs. To overcome temporal granularity limitations in existing datasets, we propose an automated annotation paradigm that combines the captioning capabilities of Video-LLMs with the localization expertise of dedicated temporal models. This leads to the creation of InternVid-TG, a substantial dataset with 1.25M temporally grounded events across 179k videos, surpassing ActivityNet-Caption by 55 times. Extensive experiments demonstrate that DisTime achieves state-of-the-art performance across benchmarks in three time-sensitive tasks while maintaining competitive performance in Video QA tasks. Code and data are released at https://github.com/josephzpng/DisTime.
Token-level Accept or Reject: A Micro Alignment Approach for Large Language Models
May 26, 2025With the rapid development of Large Language Models (LLMs), aligning these models with human preferences and values is critical to ensuring ethical and safe applications. However, existing alignment techniques such as RLHF or DPO often require direct fine-tuning on LLMs with billions of parameters, resulting in substantial computational costs and inefficiencies. To address this, we propose Micro token-level Accept-Reject Aligning (MARA) approach designed to operate independently of the language models. MARA simplifies the alignment process by decomposing sentence-level preference learning into token-level binary classification, where a compact three-layer fully-connected network determines whether candidate tokens are "Accepted" or "Rejected" as part of the response. Extensive experiments across seven different LLMs and three open-source datasets show that MARA achieves significant improvements in alignment performance while reducing computational costs.
Beyond Self-Repellent Kernels: History-Driven Target Towards Efficient Nonlinear MCMC on General Graphs
May 23, 2025We propose a history-driven target (HDT) framework in Markov Chain Monte Carlo (MCMC) to improve any random walk algorithm on discrete state spaces, such as general undirected graphs, for efficient sampling from target distribution $\boldsymbol{\mu}$. With broad applications in network science and distributed optimization, recent innovations like the self-repellent random walk (SRRW) achieve near-zero variance by prioritizing under-sampled states through transition kernel modifications based on past visit frequencies. However, SRRW's reliance on explicit computation of transition probabilities for all neighbors at each step introduces substantial computational overhead, while its strict dependence on time-reversible Markov chains excludes advanced non-reversible MCMC methods. To overcome these limitations, instead of direct modification of transition kernel, HDT introduces a history-dependent target distribution $\boldsymbol{\pi}[\mathbf{x}]$ to replace the original target $\boldsymbol{\mu}$ in any graph sampler, where $\mathbf{x}$ represents the empirical measure of past visits. This design preserves lightweight implementation by requiring only local information between the current and proposed states and achieves compatibility with both reversible and non-reversible MCMC samplers, while retaining unbiased samples with target distribution $\boldsymbol{\mu}$ and near-zero variance performance. Extensive experiments in graph sampling demonstrate consistent performance gains, and a memory-efficient Least Recently Used (LRU) cache ensures scalability to large general graphs.
EAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025



Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
DSPO: Direct Semantic Preference Optimization for Real-World Image Super-Resolution
Apr 21, 2025
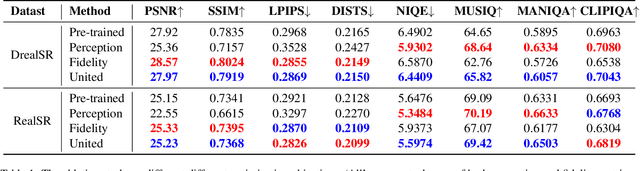
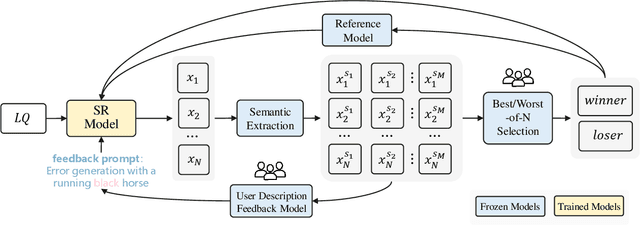

Recent advances in diffusion models have improved Real-World Image Super-Resolution (Real-ISR), but existing methods lack human feedback integration, risking misalignment with human preference and may leading to artifacts, hallucinations and harmful content generation. To this end, we are the first to introduce human preference alignment into Real-ISR, a technique that has been successfully applied in Large Language Models and Text-to-Image tasks to effectively enhance the alignment of generated outputs with human preferences. Specifically, we introduce Direct Preference Optimization (DPO) into Real-ISR to achieve alignment, where DPO serves as a general alignment technique that directly learns from the human preference dataset. Nevertheless, unlike high-level tasks, the pixel-level reconstruction objectives of Real-ISR are difficult to reconcile with the image-level preferences of DPO, which can lead to the DPO being overly sensitive to local anomalies, leading to reduced generation quality. To resolve this dichotomy, we propose Direct Semantic Preference Optimization (DSPO) to align instance-level human preferences by incorporating semantic guidance, which is through two strategies: (a) semantic instance alignment strategy, implementing instance-level alignment to ensure fine-grained perceptual consistency, and (b) user description feedback strategy, mitigating hallucinations through semantic textual feedback on instance-level images. As a plug-and-play solution, DSPO proves highly effective in both one-step and multi-step SR frameworks.
Omni-Dish: Photorealistic and Faithful Image Generation and Editing for Arbitrary Chinese Dishes
Apr 14, 2025



Dish images play a crucial role in the digital era, with the demand for culturally distinctive dish images continuously increasing due to the digitization of the food industry and e-commerce. In general cases, existing text-to-image generation models excel in producing high-quality images; however, they struggle to capture diverse characteristics and faithful details of specific domains, particularly Chinese dishes. To address this limitation, we propose Omni-Dish, the first text-to-image generation model specifically tailored for Chinese dishes. We develop a comprehensive dish curation pipeline, building the largest dish dataset to date. Additionally, we introduce a recaption strategy and employ a coarse-to-fine training scheme to help the model better learn fine-grained culinary nuances. During inference, we enhance the user's textual input using a pre-constructed high-quality caption library and a large language model, enabling more photorealistic and faithful image generation. Furthermore, to extend our model's capability for dish editing tasks, we propose Concept-Enhanced P2P. Based on this approach, we build a dish editing dataset and train a specialized editing model. Extensive experiments demonstrate the superiority of our methods.
Algorithm Design and Prototype Validation for Reconfigurable Intelligent Sensing Surface: Forward-Only Transmission
Mar 31, 2025



Sensing-assisted communication schemes have recently garnered significant research attention. In this work, we design a dual-function reconfigurable intelligent surface (RIS), integrating both active and passive elements, referred to as the reconfigurable intelligent sensing surface (RISS), to enhance communication. By leveraging sensing results from the active elements, we propose communication enhancement and robust interference suppression schemes for both near-field and far-field models, implemented through the passive elements. These schemes remove the need for base station (BS) feedback for RISS control, simplifying the communication process by replacing traditional channel state information (CSI) feedback with real-time sensing from the active elements. The proposed schemes are theoretically analyzed and then validated using software-defined radio (SDR). Experimental results demonstrate the effectiveness of the sensing algorithms in real-world scenarios, such as direction of arrival (DOA) estimation and radio frequency (RF) identification recognition. Moreover, the RISS-assisted communication system shows strong performance in communication enhancement and interference suppression, particularly in near-field models.